


Forskere viser blænding af energiforbrug i deep learnings navn

Kredit:CC0 Public Domain
Vente, hvad? At skabe en AI kan være meget værre for planeten end en bil? Tænk på CO2-fodaftryk. Det er, hvad en gruppe ved University of Massachusetts Amherst gjorde. De satte sig for at vurdere det energiforbrug, der skal til for at træne fire store neurale netværk.
Deres papir vækker i øjeblikket opmærksomhed blandt tech-se-sider. Den har titlen "Energi og politiske overvejelser for dyb læring i NLP, " af Emma Strubell, Ananya Ganesh og Andrew McCallum.
Det her, sagde Karen Hao, kunstig intelligens reporter for MIT Technology Review , var en livscyklusvurdering til træning af flere almindelige store AI-modeller.
"Seneste fremskridt inden for hardware og metodologi til træning af neurale netværk har indvarslet en ny generation af store netværk trænet på rigelige data, " sagde forskerne.
Hvad er dit gæt? At træning af en AI-model ville resultere i et "tungt" fodaftryk? "Lidt tung?" Hvad med "forfærdeligt?" Det sidste var ordet valgt af MIT Technology Review den 6. juli, Torsdag, rapportering om resultaterne.
Deep learning involverer behandling af meget store mængder data. (Oplægget undersøgte specifikt modeltræningsprocessen for behandling af naturligt sprog, underområdet af AI, der fokuserer på at lære maskiner at håndtere menneskeligt sprog, sagde Hao.) Donna Lu ind Ny videnskabsmand citerede Strubell, hvem sagde, "For at lære noget så komplekst som sprog, modellerne skal være store." Hvilke prisskabende modeller opnår gevinster i nøjagtighed? At bruge usædvanligt store beregningsressourcer til at gøre det er prisen, forårsager et betydeligt energiforbrug.
Hao rapporterede deres resultater, at "processen kan udsende mere end 626, 000 pund kuldioxidækvivalent - næsten fem gange livstidsemissionerne for den gennemsnitlige amerikanske bil (og det inkluderer fremstilling af selve bilen)."
Disse modeller er dyre at træne og udvikle - dyre i økonomisk forstand på grund af omkostningerne til hardware og elektricitet eller cloud computing-tid, og dyrt i miljømæssig forstand. De miljømæssige omkostninger skyldes CO2-fodaftrykket. Papiret forsøgte at bringe dette spørgsmål til NLP-forskernes opmærksomhed "ved at kvantificere de omtrentlige økonomiske og miljømæssige omkostninger ved at træne en række nyligt vellykkede neurale netværksmodeller til NLP."
Sådan testede de:For at måle miljøpåvirkningen, de trænede fire AI'er for en dag hver, og prøvede hele energiforbruget. De beregnede den samlede effekt, der kræves for at træne hver AI ved at gange dette med den samlede træningstid, der er rapporteret af hver models udviklere. Et CO2-fodaftryk blev estimeret baseret på de gennemsnitlige CO2-emissioner, der blev brugt til elproduktion i USA.
Hvad anbefalede forfatterne? De gik i retning af anbefalinger til at reducere omkostningerne og "forbedre egenkapitalen" i NLP-forskning. Egenkapital? Forfatterne rejser spørgsmålet.
"Akademiske forskere har brug for lige adgang til beregningsressourcer. Nylige fremskridt inden for tilgængelig computer kommer til en høj pris, som ikke kan opnås for alle, der ønsker adgang. De fleste af de modeller, der er undersøgt i dette papir, blev udviklet uden for den akademiske verden; nylige forbedringer i tilstanden af- kunstpræcision er mulig takket være industriens adgang til databehandling i stor skala."
Forfatterne påpegede, at "at begrænse denne forskningsstil til industrilaboratorier skader NLP-forskningssamfundet på mange måder." Kreativiteten er kvalt. Gode ideer er ikke nok, hvis forskerholdet mangler adgang til storskala databehandling.
"Sekund, den forbyder visse typer forskning på grundlag af adgang til finansielle ressourcer. Dette fremmer endnu dybere den allerede problematiske 'rig bliv rigere'-cyklus af forskningsfinansiering, hvor grupper, der allerede er succesfulde og dermed velfinansierede, har en tendens til at modtage mere finansiering på grund af deres eksisterende resultater."
Forfatterne sagde, "Forskere bør prioritere beregningseffektiv hardware og algoritmer." I denne ånd, Forfatterne anbefalede en indsats fra industrien og den akademiske verden for at fremme forskning i mere beregningseffektive algoritmer, og hardware, der kræver mindre energi.
Hvad er det næste? Forskningen vil blive præsenteret på det årlige møde i Association for Computer Linguistics i Firenze, Italien i juli.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Et dybt dyk i undersøisk overvågning:Hold øje med havbundenVerdens kontinentalhylder er krydret med undersøiske oliebrønde. Når de ikke længere er i brug, nogen bliver nødt til at overvåge dem - men hvordan? En gruppe NTNU kandidatstuderende har et muligt sva
Et dybt dyk i undersøisk overvågning:Hold øje med havbundenVerdens kontinentalhylder er krydret med undersøiske oliebrønde. Når de ikke længere er i brug, nogen bliver nødt til at overvåge dem - men hvordan? En gruppe NTNU kandidatstuderende har et muligt sva -
 En ny vandrende biolog, der bevæger sig langs en kaskelothvalens kropsoverfladeKredit:Tsuchiya et al. Et team af forskere ved Yamagata University og Teikyo University of Science, i Japan, har for nylig udviklet en ny vandrende biolog, eller hvalrover, som kan rejse langs en
En ny vandrende biolog, der bevæger sig langs en kaskelothvalens kropsoverfladeKredit:Tsuchiya et al. Et team af forskere ved Yamagata University og Teikyo University of Science, i Japan, har for nylig udviklet en ny vandrende biolog, eller hvalrover, som kan rejse langs en -
 Indien skal bygge solenergi, vindmølleparker langs grænsen til PakistanIndien øger sin investering i vedvarende energi i et hæsblæsende tempo Indien planlægger at bygge en række vedvarende energiprojekter langs sit solbagte, vindpiskede vestlige grænse, embedsmænd sa
Indien skal bygge solenergi, vindmølleparker langs grænsen til PakistanIndien øger sin investering i vedvarende energi i et hæsblæsende tempo Indien planlægger at bygge en række vedvarende energiprojekter langs sit solbagte, vindpiskede vestlige grænse, embedsmænd sa -
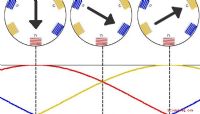 Dele af induktionsmotorerEn induktionsmotor er en type elektrisk motor, der omdanner elektrisk strøm til roterende bevægelse. En induktionsmotor anvender princippet om elektromagnetisk induktion for at få rotoren til at dreje
Dele af induktionsmotorerEn induktionsmotor er en type elektrisk motor, der omdanner elektrisk strøm til roterende bevægelse. En induktionsmotor anvender princippet om elektromagnetisk induktion for at få rotoren til at dreje
- Babytrin:Gammelt kranium hjælper med at spore vejen til moderne barndom
- 10 typer studieforstyrrelser
- Spraybelagt taktil sensor på en 3-D overflade til robothud
- Ny forskning finder, at ulighed mellem kønnene rækker ud over graven
- Nitrogenoxid, en drivhusgas, er i fremmarch:studie
- Ingeniører sætter titusindvis af kunstige hjernesynapser på en enkelt chip