


Identificere blinde pletter af kunstig intelligens
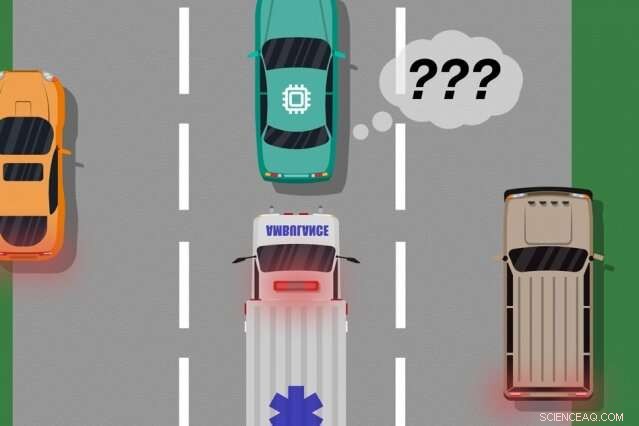
En model af MIT og Microsoft -forskere identificerer tilfælde, hvor autonome biler har "lært" af træningseksempler, der ikke matcher det, der rent faktisk sker på vejen, som kan bruges til at identificere hvilke indlærte handlinger der kan forårsage fejl i den virkelige verden. Kredit:MIT News
En ny model udviklet af MIT- og Microsoft -forskere identificerer tilfælde, hvor autonome systemer har "lært" af træningseksempler, der ikke matcher det, der rent faktisk sker i den virkelige verden. Ingeniører kunne bruge denne model til at forbedre sikkerheden ved kunstige intelligenssystemer, såsom førerløse køretøjer og autonome robotter.
AI -systemer, der driver førerløse biler, for eksempel, er uddannet grundigt i virtuelle simuleringer til at forberede køretøjet til næsten enhver begivenhed på vejen. Men nogle gange laver bilen en uventet fejl i den virkelige verden, fordi der opstår en hændelse, der burde, men gør ikke, ændre bilens adfærd.
Overvej en førerløs bil, der ikke var uddannet, og endnu vigtigere ikke har sensorerne nødvendige, at skelne mellem klart forskellige scenarier, såsom store, hvide biler og ambulancer med rødt, blinkende lys på vejen. Hvis bilen cruiser ned ad motorvejen, og en ambulance slår på sirenerne, bilen ved måske ikke at bremse og trække over, fordi den ikke opfatter ambulancen som forskellig fra en stor hvid bil.
I et par papirer - præsenteret på sidste års Autonomous Agents and Multiagent Systems -konference og den kommende Association for the Advancement of Artificial Intelligence -konference - beskriver forskerne en model, der bruger menneskelige input til at afdække disse træning "blinde pletter".
Som med traditionelle metoder, forskerne satte et AI -system gennem simuleringstræning. Men derefter, et menneske overvåger systemets handlinger nøje, når det virker i den virkelige verden, give feedback, når systemet lavede, eller var ved at lave, eventuelle fejl. Forskerne kombinerer derefter træningsdata med menneskelige feedbackdata, og brug maskinlæringsteknikker til at producere en model, der præciserer situationer, hvor systemet højst sandsynligt har brug for flere oplysninger om, hvordan man handler korrekt.
Forskerne validerede deres metode ved hjælp af videospil, med et simuleret menneske, der korrigerer den indlærte vej for en karakter på skærmen. Men det næste trin er at inkorporere modellen med traditionelle trænings- og testmetoder for autonome biler og robotter med menneskelig feedback.
"Modellen hjælper autonome systemer med bedre at vide, hvad de ikke ved, "siger første forfatter Ramya Ramakrishnan, en kandidatstuderende i datalogi og kunstig intelligenslaboratorium. "Mange gange, når disse systemer implementeres, deres uddannede simuleringer matcher ikke den virkelige verden [og] de kan begå fejl, såsom at komme ud for ulykker. Ideen er at bruge mennesker til at bygge bro over kløften mellem simulering og den virkelige verden, på en sikker måde, så vi kan reducere nogle af disse fejl. "
Medforfattere på begge papirer er:Julie Shah, en lektor i Institut for Aeronautik og Astronautik og leder af CSAIL's Interactive Robotics Group; og Ece Kamar, Debadeepta Dey, og Eric Horvitz, alt fra Microsoft Research. Besmira Nushi er en ekstra medforfatter på det kommende papir.
Tager feedback
Nogle traditionelle træningsmetoder giver menneskelig feedback under virkelige testkørsler, men kun for at opdatere systemets handlinger. Disse tilgange identificerer ikke blinde pletter, hvilket kunne være nyttigt for sikrere udførelse i den virkelige verden.
Forskernes tilgang sætter først et AI -system gennem simuleringstræning, hvor det vil producere en "politik", der i det væsentlige kortlægger enhver situation til den bedste handling, den kan foretage i simuleringerne. Derefter, systemet vil blive implementeret i den virkelige verden, hvor mennesker leverer fejlsignaler i regioner, hvor systemets handlinger er uacceptable.
Mennesker kan levere data på flere måder, såsom gennem "demonstrationer" og "rettelser". I demonstrationer, de menneskelige handlinger i den virkelige verden, mens systemet observerer og sammenligner menneskets handlinger med, hvad det ville have gjort i den situation. For førerløse biler, for eksempel, et menneske ville manuelt styre bilen, mens systemet producerer et signal, hvis dets planlagte adfærd afviger fra menneskets adfærd. Match og mismatch med menneskets handlinger giver støjende indikationer på, hvor systemet kan virke acceptabelt eller uacceptabelt.
Alternativt kan mennesket kan give rettelser, med den menneskelige overvågning af systemet, som det virker i den virkelige verden. Et menneske kunne sidde i førersædet, mens den autonome bil kører selv ad den planlagte rute. Hvis bilens handlinger er korrekte, mennesket gør ingenting. Hvis bilens handlinger er forkerte, imidlertid, mennesket kan tage rattet, som sender et signal om, at systemet ikke handlede uacceptabelt i den specifikke situation.
Når feedbackdataene fra mennesket er samlet, systemet har i det væsentlige en liste over situationer og, for hver situation, flere etiketter, der siger, at dens handlinger var acceptable eller uacceptable. En enkelt situation kan modtage mange forskellige signaler, fordi systemet opfatter mange situationer som identiske. For eksempel, en autonom bil kan have krydset langs en stor bil mange gange uden at sænke farten og trække over. Men, i kun ét tilfælde, en ambulance, som forekommer nøjagtig det samme for systemet, krydstogter forbi. Den autonome bil trækker ikke over og modtager et feedback -signal om, at systemet har taget en uacceptabel handling.
"På det tidspunkt, systemet har fået flere modstridende signaler fra et menneske:nogle med en stor bil ved siden af, og det gik fint, og en, hvor der var en ambulance samme præcise sted, men det var ikke fint. Systemet gør en lille bemærkning om, at det gjorde noget forkert, men ved ikke hvorfor, "Siger Ramakrishnan." Fordi agenten får alle disse modstridende signaler, det næste trin er at sammensætte de oplysninger, der skal stilles, 'Hvor sandsynligt er det, at jeg begår en fejl i denne situation, hvor jeg modtog disse blandede signaler?' "
Intelligent aggregering
Slutmålet er at få disse tvetydige situationer mærket som blinde pletter. Men det går ud over blot at opregne de acceptable og uacceptable handlinger for hver situation. Hvis systemet udførte korrekte handlinger ni gange ud af 10 i ambulancesituationen, for eksempel, et simpelt flertal ville betegne denne situation som sikker.
"Men fordi uacceptable handlinger er langt sjældnere end acceptable handlinger, systemet vil i sidste ende lære at forudsige alle situationer som sikre, som kan være ekstremt farlig, "Siger Ramakrishnan.
Til det formål, forskerne brugte Dawid-Skene-algoritmen, en machine-learning metode, der almindeligvis bruges til crowdsourcing til at håndtere etiketstøj. Algoritmen tager som input en liste over situationer, hver har et sæt støjende "acceptable" og "uacceptable" etiketter. Derefter samler den alle data og bruger nogle sandsynlighedsberegninger til at identificere mønstre i etiketterne for forudsagte blinde pletter og mønstre for forudsagte sikre situationer. Ved hjælp af disse oplysninger, den udsender en enkelt samlet "sikker" eller "blind spot" -mærke for hver situation sammen med dens tillidsniveau i denne etiket. Især algoritmen kan lære i en situation, hvor den kan have, for eksempel, udført acceptabelt 90 procent af tiden, situationen er stadig tvetydig nok til at fortjene en "blind vinkel".
Til sidst, algoritmen producerer en type "varmekort, "hvor hver situation fra systemets oprindelige uddannelse er tildelt lav til høj sandsynlighed for at være en blind plet for systemet.
"Når systemet implementeres i den virkelige verden, den kan bruge denne indlærte model til at handle mere forsigtigt og intelligent. Hvis den indlærte model forudsiger, at en tilstand er en blind plet med stor sandsynlighed, systemet kan forespørge et menneske om acceptabel handling, muliggør en sikrere udførelse, "Siger Ramakrishnan.
Denne historie er genudgivet med tilladelse fra MIT News (web.mit.edu/newsoffice/), et populært websted, der dækker nyheder om MIT -forskning, innovation og undervisning.
Sidste artikelDet er gratis og let at se tv med Locast under radaren
Næste artikelEt nyt køretøjssøgningssystem til videoovervågningsnetværk
 Varme artikler
Varme artikler
-
 Britisk lovgiver udfordrer Facebook på politiske annoncerFacebook CEO Mark Zuckerberg taler på Georgetown University, Torsdag, 17. oktober kl. 2019, i Washington. (AP Photo/Nick Wass) En indflydelsesrig britisk lovgiver udfordrede Facebooks nye indsats
Britisk lovgiver udfordrer Facebook på politiske annoncerFacebook CEO Mark Zuckerberg taler på Georgetown University, Torsdag, 17. oktober kl. 2019, i Washington. (AP Photo/Nick Wass) En indflydelsesrig britisk lovgiver udfordrede Facebooks nye indsats -
 Dyb læring kommer fuld cirkelKredit:CC0 Public Domain Årevis, de mennesker, der udviklede kunstig intelligens, hentede inspiration fra det, man vidste om den menneskelige hjerne, og det har haft stor succes som resultat. Nu,
Dyb læring kommer fuld cirkelKredit:CC0 Public Domain Årevis, de mennesker, der udviklede kunstig intelligens, hentede inspiration fra det, man vidste om den menneskelige hjerne, og det har haft stor succes som resultat. Nu, -
 Hårde nødder, knækket på en smart mådeAdditive Manufacturing gør det muligt at fremstille små metalstrukturer med en kompleks geometri. Her er et prøvestykke sammenlignet med et tændstikhoved. Brug af kunstig intelligens til at overvåge f
Hårde nødder, knækket på en smart mådeAdditive Manufacturing gør det muligt at fremstille små metalstrukturer med en kompleks geometri. Her er et prøvestykke sammenlignet med et tændstikhoved. Brug af kunstig intelligens til at overvåge f -
 Apples data viser en dramatisk indvirkning af virus på bevægelseGrafisk viser data, der afspejler ændringer i mobilitet, leveret af Apple, baseret på forespørgsler efter kortretninger. Apple har lanceret et nyt websted, der med slående grafer viser, hvordan co
Apples data viser en dramatisk indvirkning af virus på bevægelseGrafisk viser data, der afspejler ændringer i mobilitet, leveret af Apple, baseret på forespørgsler efter kortretninger. Apple har lanceret et nyt websted, der med slående grafer viser, hvordan co
- Ny forskning moderniserer konstruktion med ramt jord
- Forskerteam udvikler injicerbar behandling til soldater sårede i kamp
- Forskere får indsigt i genbrugsprocesser for nukleart og elektronisk affald
- Anvendelse af mikroskoper i Science
- Hvad er ledningsevnen af kobber?
- Snapchat udfordrer Facebook blandt amerikanske unge:undersøgelse