


Højtydende databehandling reducerer forberedelsestiden for partikelkollisionsdata

Denne animation viser en række kollisionsbegivenheder ved STAR, hver med tusindvis af partikelspor og signalerne registreret, da nogle af disse partikler rammer forskellige detektorkomponenter. Det burde give dig en idé om, hvor kompleks udfordringen er at rekonstruere en komplet registrering af hver enkelt partikel og de betingelser, hvorunder den blev skabt, så videnskabsmænd kan sammenligne hundreder af millioner af begivenheder for at lede efter trends og gøre opdagelser. Kredit:Brookhaven National Laboratory
For første gang, forskere har brugt high-performance computing (HPC) til at rekonstruere de data, der er indsamlet ved et kernefysisk eksperiment - et fremskridt, der dramatisk kan reducere den tid, det tager at gøre detaljerede data tilgængelige for videnskabelige opdagelser.
Demonstrationsprojektet brugte Cori-supercomputeren ved National Energy Research Scientific Computing Center (NERSC), et højtydende computercenter ved Lawrence Berkeley National Laboratory i Californien, at rekonstruere flere datasæt indsamlet af STAR-detektoren under partikelkollisioner ved Relativistic Heavy Ion Collider (RHIC), et kernefysisk forskningsanlæg ved Brookhaven National Laboratory i New York. Ved at køre flere computerjob samtidigt på de tildelte supercomputing-kerner, holdet forvandlede 4,73 petabyte rådata til 2,45 petabyte "fysikklare" data på en brøkdel af den tid, det ville have taget ved at bruge interne high-throughput computerressourcer, selv med en tovejs transkontinental datarejse.
"Grunden til, at dette er virkelig fantastisk, " sagde Brookhaven-fysiker Jérôme Lauret, hvem administrerer STARs computerbehov, "er, at disse højtydende computerressourcer er elastiske. Du kan ringe for at reservere en stor tildeling af computerkraft, når du har brug for det - f.eks. lige før en stor konference, hvor fysikere har travlt med at præsentere nye resultater." Ifølge Lauret, forberedelse af rådata til analyse tager typisk mange måneder, gør det næsten umuligt at give en sådan kortsigtet reaktionsevne. "Men med HPC, måske kunne du kondensere den mange måneders produktionstid til en uge. Det ville virkelig styrke forskerne!"
Præstationen viser de synergistiske evner hos RHIC og NERSC—U.S. Department of Energy (DOE) Office of Science brugerfaciliteter placeret ved DOE-drevne nationale laboratorier på modsatte kyster - forbundet med et af de mest omfattende højtydende datadelingsnetværk i verden, DOE's Energy Sciences Network (ESnet), en anden DOE Office of Science brugerfacilitet.
"Dette er en nøglebrugsmodel for højtydende databehandling til eksperimentelle data, demonstrerer, at forskere kan få deres rådatabehandling eller simuleringskampagner udført på få dage eller uger på et kritisk tidspunkt i stedet for at sprede sig over måneder på deres egne dedikerede ressourcer, " sagde Jeff Porter, et medlem af data- og analyseserviceteamet hos NERSC.
Milliarder af datapunkter
For at gøre fysikopdagelser på RHIC, videnskabsmænd skal sortere gennem hundreder af millioner af kollisioner mellem ioner accelereret til meget høj energi. STJERNE, en sofistikeret, elektronisk instrument i husstørrelse, registrerer det subatomære affald, der strømmer fra disse partikel-smashups. I de mest energiske begivenheder, mange tusinde partikler rammer detektorkomponenter, producerer fyrværkeri-lignende opvisninger af farverige partikelspor. Men for at finde ud af, hvad disse komplekse signaler betyder, og hvad de kan fortælle os om den spændende form for stof skabt i RHIC's kollisioner, videnskabsmænd har brug for detaljerede beskrivelser af alle partiklerne og de betingelser, hvorunder de blev produceret. De skal også sammenligne enorme statistiske prøver fra mange forskellige typer kollisionshændelser.
At katalogisere den information kræver sofistikerede algoritmer og mønstergenkendelsessoftware til at kombinere signaler fra de forskellige udlæsningselektronik, og en problemfri måde at matche disse data med registreringer af kollisionsforhold. Al information skal så pakkes ind på en måde, som fysikere kan bruge til deres analyser.

Cori, den nyeste supercomputer ved National Energy Research Scientific Computing Center (NERSC), er en Cray XC40 med en topydelse på omkring 30 petaflops. Kredit:Brookhaven National Laboratory
Siden RHIC startede i år 2000, denne rå databehandling, eller genopbygning, er blevet udført på dedikerede computerressourcer på RHIC og ATLAS Computing Facility (RACF) i Brookhaven. High-throughput computing (HTC) klynger knuser dataene, begivenhed for begivenhed, og skriv de kodede detaljer om hver kollision til et centraliseret masselager, der er tilgængeligt for STAR-fysikere rundt om i verden.
Men udfordringen med at holde trit med dataene er vokset med RHICs stadigt forbedrede kollisionsrater og efterhånden som nye detektorkomponenter er blevet tilføjet. I de seneste år, STARs årlige rådatasæt har nået milliarder af hændelser med datastørrelser i multi-Petabyte-området. Så STAR computerteamet undersøgte brugen af eksterne ressourcer for at imødekomme efterspørgslen efter rettidig adgang til fysikklare data.
Mange kerner gør let arbejde
I modsætning til high-throughput computere på RACF, som analyserer begivenheder én for én, HPC-ressourcer som dem hos NERSC opdeler store problemer i mindre opgaver, der kan køre parallelt. Så den første udfordring var at "parallisere" behandlingen af STAR-hændelsesdata.
"Vi skrev workflow-programmer, der opnåede det første niveau af parallelisering - event parallelisering, " sagde Lauret. Det betyder, at de indsender færre job lavet af mange begivenheder, som kan behandles samtidigt på de mange HPC-computerkerner.
"Forestil dig at bygge en by med 100 boliger. Hvis dette blev gjort på en måde med høj gennemstrømning, hvert hjem ville have én bygherre, der udfører alle opgaverne i rækkefølge - at bygge fundamentet, væggene, og så videre, " sagde Lauret. "Men med HPC ændrer vi paradigmet. I stedet for én arbejder pr. hus har vi 100 arbejdere pr. hus, og hver arbejder har en opgave - at bygge væggene eller taget. De arbejder parallelt, på samme tid, og vi samler alt sammen til sidst. Med denne tilgang, vi vil bygge det hus 100 gange hurtigere."
Selvfølgelig, det kræver noget kreativitet at tænke over, hvordan sådanne problemer kan opdeles i opgaver, der kan køre samtidigt i stedet for sekventielt, Lauret tilføjede.
HPC sparer også tid ved at matche rå detektorsignaler med data om miljøforholdene under hver begivenhed. At gøre dette, computerne skal have adgang til en "tilstandsdatabase" - en registrering af spændingen, temperatur, tryk, og andre detektorforhold, der skal tages højde for for at forstå opførselen af de partikler, der produceres ved hver kollision. I begivenhed for begivenhed, rekonstruktion med høj kapacitet, computerne kalder databasen op for at hente data for hver enkelt hændelse. Men fordi HPC-kerner deler noget hukommelse, hændelser, der opstår tæt i tid, kan bruge de samme cachelagrede tilstandsdata. Færre opkald til databasen betyder hurtigere databehandling.
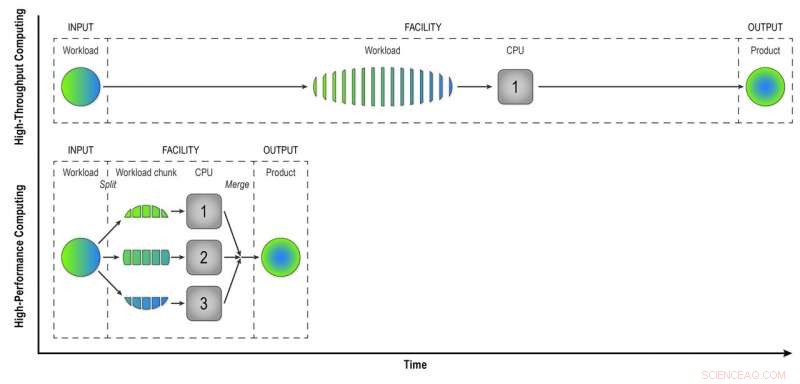
I high-throughput computing, en arbejdsbyrde, der består af data fra mange STAR-kollisioner, behandles hændelse-for-hændelse på en sekventiel måde for at give fysikere "rekonstruerede data" - det produkt, de har brug for til fuldt ud at analysere dataene. Højtydende computing deler arbejdsbyrden op i mindre bidder, der kan køres gennem separate CPU'er for at fremskynde datarekonstruktionen. I denne enkle illustration, at opdele en arbejdsbyrde på 15 hændelser i tre bidder af fem hændelser, der behandles parallelt, giver det samme produkt på en tredjedel af tiden som high-throughput-metoden. Brug af 32 CPU'er på en supercomputer som Cori kan i høj grad reducere den tid, det tager at transformere de rå data fra et rigtigt STAR-datasæt, med mange millioner begivenheder, til nyttig information, fysikere kan analysere for at gøre opdagelser. Kredit:Brookhaven National Laboratory
Networking teamwork
En anden udfordring ved at migrere opgaven med at rekonstruktion af rådata til et HPC-miljø var netop at få dataene fra New York til supercomputerne i Californien og tilbage. Både input- og outputdatasættene er enorme. Holdet startede i det små med et proof-of-principle-eksperiment – blot et par hundrede jobs – for at se, hvordan deres nye workflow-programmer ville fungere.
"Vi fik meget hjælp fra netværksprofessionelle i Brookhaven, sagde Lauret, "især Mark Lukascsyk, en af vores netværksingeniører, som var så begejstret for videnskaben og hjalp os med at gøre opdagelser." Kolleger i RACF og ESnet hjalp også med at identificere hardwareproblemer og udviklede løsninger, da teamet arbejdede tæt sammen med Jeff Porter, Mustafa Mustafa, og andre hos NERSC for at optimere dataoverførslen og end-to-end workflowet.
Start i det små, opskalere
Efter at have finjusteret deres metoder baseret på de indledende tests, holdet begyndte at skalere op til at bruge 6, 400 computerkerner på NERSC, så op og op og op.
"6, 400 kerner er allerede halvdelen af størrelsen af de ressourcer, der er tilgængelige til datarekonstruktion hos RACF, " sagde Lauret. "Til sidst gik vi til 25, 600 kerner i vores seneste test." Med alt klar i forvejen til en forhåndsreservation tildeling af tid på Cori supercomputeren, "Vi lavede denne test i et par dage og fik lavet en hel dataproduktion på ingen tid, " sagde Lauret. Ifølge Porter på NERSC, "Denne model er potentielt ret transformerende, og NERSC har arbejdet på at understøtte en sådan ressourceudnyttelse ved, for eksempel, forbinder dets centerdækkende højtydende disksystem direkte til dets dataoverførselsinfrastruktur og tillader betydelig fleksibilitet i, hvordan jobslots kan planlægges."
End-to-end effektiviteten af hele processen - den tid programmet kørte (ikke siddende inaktiv, venter på computerressourcer) multipliceret med effektiviteten ved at bruge de tildelte supercomputing slots og få nyttigt output hele vejen tilbage til Brookhaven - var 98 procent.
"Vi har bevist, at vi kan bruge HPC-ressourcerne effektivt til at eliminere efterslæb af ubehandlede data og løse midlertidige ressourcekrav for at fremskynde videnskabelige opdagelser, " sagde Lauret.
Han udforsker nu måder at generalisere arbejdsgangen til Open Science Grid – et globalt konsortium, der samler computerressourcer – så hele samfundet af højenergi- og kernefysikere kan gøre brug af det.
 Varme artikler
Varme artikler
-
 Superledning i high-Tc cuprates:Fra maksimal til minimal dissipation - et nyt paradigme?Kredit:CC0 Public Domain Forskere fra University of Bristols School of Physics brugte nogle af Europas stærkeste kontinuerlige magnetfelter til at afdække beviser for eksotiske ladningsbærere i de
Superledning i high-Tc cuprates:Fra maksimal til minimal dissipation - et nyt paradigme?Kredit:CC0 Public Domain Forskere fra University of Bristols School of Physics brugte nogle af Europas stærkeste kontinuerlige magnetfelter til at afdække beviser for eksotiske ladningsbærere i de -
 Galliumoxid viser høj elektronmobilitet, hvilket gør det lovende for bedre og billigere enhederSkematisk stak og det scannende elektronmikroskopiske billede af β- (AlxGa1-x) 2O3/Ga2O3 modulationsdopet felteffekttransistor. Kredit:Choong Hee Lee og Yuewei Zhang Den næste generation af energi
Galliumoxid viser høj elektronmobilitet, hvilket gør det lovende for bedre og billigere enhederSkematisk stak og det scannende elektronmikroskopiske billede af β- (AlxGa1-x) 2O3/Ga2O3 modulationsdopet felteffekttransistor. Kredit:Choong Hee Lee og Yuewei Zhang Den næste generation af energi -
 Lyn, med en chance for antimaterialeEt team fra Kyoto-universitetet har afsløret mysteriet om gammastrålingskaskader forårsaget af lynnedslag. Kredit:Kyoto University/Teruaki Enoto Et stormsystem nærmer sig:himlen mørkner, og det la
Lyn, med en chance for antimaterialeEt team fra Kyoto-universitetet har afsløret mysteriet om gammastrålingskaskader forårsaget af lynnedslag. Kredit:Kyoto University/Teruaki Enoto Et stormsystem nærmer sig:himlen mørkner, og det la -
 En sikker optisk fiber til at levere lys og medicin ind i kroppenEt billede af lyslevering gennem en citratbaseret optisk fiber. Kredit:Dingying Shan / Chenji Zhang / Penn State En fleksibel, biologisk nedbrydelig optisk fiber, der kan levere lys ind i kroppen
En sikker optisk fiber til at levere lys og medicin ind i kroppenEt billede af lyslevering gennem en citratbaseret optisk fiber. Kredit:Dingying Shan / Chenji Zhang / Penn State En fleksibel, biologisk nedbrydelig optisk fiber, der kan levere lys ind i kroppen