


Linsefri billeddannelse gennem avanceret maskinlæring til næste generations billedregistreringsløsninger
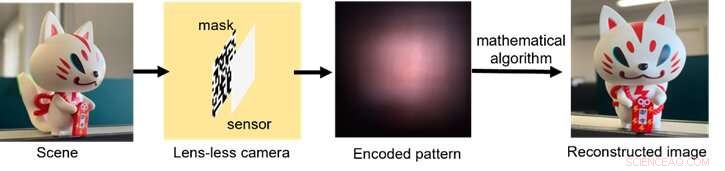
Et skematisk billede af, hvordan den linseløse billedbehandlingsproces fungerer, fra lysindsamling over indkodning af signalet til efterbehandling med computeralgoritmer. Kredit:Xiuxi Pan fra Tokyo Tech
Et kamera kræver normalt et linsesystem for at tage et fokuseret billede, og kameraet med linse har været den dominerende billedløsning i århundreder. Et kamera med objektiver kræver et komplekst linsesystem for at opnå højkvalitets, lysstærk og aberrationsfri billeddannelse. De seneste årtier har set en stigning i efterspørgslen efter mindre, lettere og billigere kameraer. Der er et klart behov for næste generations kameraer med høj funktionalitet, kompakt nok til at blive installeret hvor som helst. Miniaturiseringen af det objektiverede kamera er dog begrænset af linsesystemet og den fokuseringsafstand, der kræves af refraktive linser.
Nylige fremskridt inden for databehandlingsteknologi kan forenkle linsesystemet ved at erstatte nogle dele af det optiske system med databehandling. Hele objektivet kan forlades takket være brugen af billedrekonstruktionscomputere, hvilket giver mulighed for et objektivløst kamera, som er ultratyndt, let og billigt. Det objektivløse kamera har for nylig vundet indpas. Men indtil videre er billedrekonstruktionsteknikken ikke blevet etableret, hvilket resulterer i utilstrækkelig billedkvalitet og kedelig beregningstid for det objektivløse kamera.
For nylig har forskere udviklet en ny billedgenopbygningsmetode, der forbedrer beregningstiden og giver billeder i høj kvalitet. Et kernemedlem af forskerholdet, prof. Masahiro Yamaguchi fra Tokyo Tech, beskriver den oprindelige motivation bag forskningen:"Uden begrænsningerne ved en linse kunne det objektivløse kamera være ultra-miniature, hvilket kunne tillade nye applikationer, der er hinsides vores fantasi." Deres arbejde er blevet offentliggjort i Optics Letters .
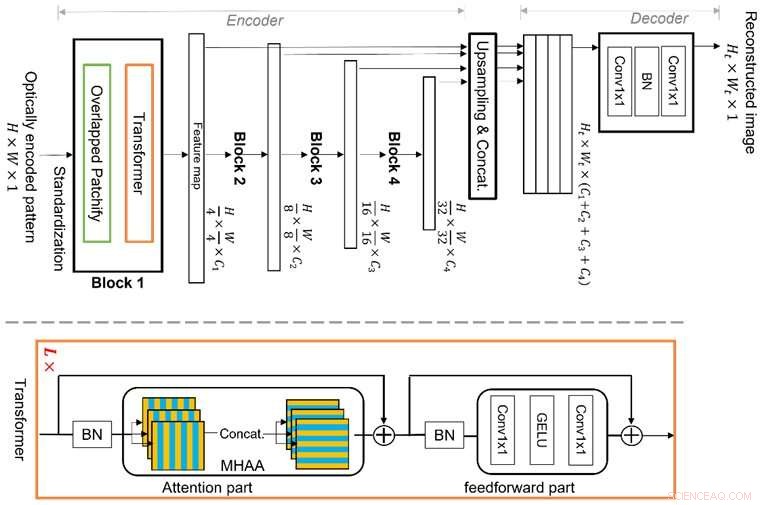
Vision Transformer (ViT) er en avanceret maskinlæringsteknik, som er bedre til global funktionsræsonnement på grund af dens nye struktur af multitrins transformerblokke med overlappede "patchify"-moduler. Dette giver den mulighed for effektivt at lære billedfunktioner i en hierarkisk repræsentation, hvilket gør den i stand til at adressere multipleksingsegenskaben og undgå begrænsningerne ved konventionel CNN-baseret dyb læring, og derved tillade bedre billedrekonstruktion. Kredit:Xiuxi Pan fra Tokyo Tech
Den typiske optiske hardware i det objektivløse kamera består blot af en tynd maske og en billedsensor. Billedet rekonstrueres derefter ved hjælp af en matematisk algoritme. Masken og sensoren kan fremstilles sammen i etablerede halvlederfremstillingsprocesser til fremtidig produktion. Masken koder optisk det indfaldende lys og kaster mønstre på sensoren. Selvom de støbte mønstre er fuldstændig utolkelige for det menneskelige øje, kan de afkodes med eksplicit viden om det optiske system.
Afkodningsprocessen – baseret på billedrekonstruktionsteknologi – forbliver dog udfordrende. Traditionelle modelbaserede afkodningsmetoder tilnærmer den fysiske proces af den linseløse optik og rekonstruerer billedet ved at løse et "konveks" optimeringsproblem. Dette betyder, at rekonstruktionsresultatet er modtageligt for de ufuldkomne tilnærmelser af den fysiske model. Desuden er den nødvendige beregning for at løse optimeringsproblemet tidskrævende, fordi den kræver iterativ beregning. Dyb læring kunne hjælpe med at undgå begrænsningerne ved modelbaseret afkodning, da den i stedet kan lære modellen og afkode billedet ved en ikke-iterativ direkte proces. Eksisterende deep learning-metoder til linseløs billeddannelse, som anvender et foldet neuralt netværk (CNN), kan dog ikke producere billeder af høj kvalitet. De er ineffektive, fordi CNN behandler billedet baseret på forholdet mellem nabo "lokale" pixels, hvorimod linseløs optik transformerer lokal information i scenen til overlappende "global" information på alle billedsensorens pixels, gennem en egenskab kaldet "multiplexing". "

Det linseløse kamera består af en maske og en billedsensor med en adskillelsesafstand på 2,5 mm. Masken er fremstillet ved kromaflejring i en syntetisk silicaplade med en åbningsstørrelse på 40×40 μm. Kredit:Xiuxi Pan fra Tokyo Tech
Tokyo Tech-forskerholdet studerer denne multipleksingsegenskab og har nu foreslået en ny, dedikeret maskinlæringsalgoritme til billedrekonstruktion. Den foreslåede algoritme er baseret på en førende maskinlæringsteknik kaldet Vision Transformer (ViT), som er bedre til global funktionsræsonnement. Det nye ved algoritmen ligger i strukturen af flertrinstransformatorblokkene med overlappede "patchify"-moduler. Dette giver den mulighed for effektivt at lære billedfunktioner i en hierarkisk repræsentation. Som følge heraf kan den foreslåede metode godt adressere multipleksingsegenskaben og undgå begrænsningerne ved konventionel CNN-baseret deep learning, hvilket muliggør bedre billedrekonstruktion.
Mens konventionelle modelbaserede metoder kræver lange beregningstider for iterativ behandling, er den foreslåede metode hurtigere, fordi den direkte rekonstruktion er mulig med en iterativ-fri behandlingsalgoritme designet af maskinlæring. Påvirkningen af modeltilnærmelsesfejl reduceres også dramatisk, fordi maskinlæringssystemet lærer den fysiske model. Desuden bruger den foreslåede ViT-baserede metode globale funktioner i billedet og er velegnet til at behandle støbte mønstre over et bredt område på billedsensoren, hvorimod konventionelle maskinlæringsbaserede afkodningsmetoder hovedsageligt lærer lokale relationer af CNN.
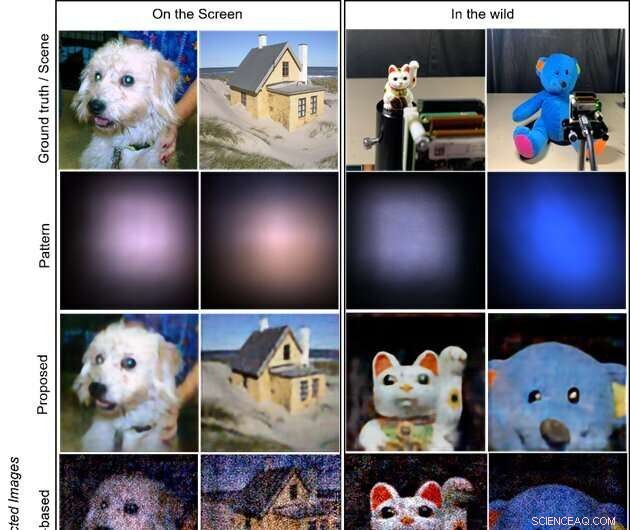
Målene er billederne, der vises på en LCD-skærm (to venstre kolonner) og objekterne i naturen (højre to kolonner; vinkende kattedukke og udstoppet bjørn). Den første række viser sandhedens billeder, der vises på skærmen, og optagelsesscenerne for objekter i naturen. Den anden række viser de fangede mønstre på sensoren. De sidste tre rækker illustrerer de rekonstruerede billeder ved henholdsvis de foreslåede, modelbaserede og CNN-baserede metoder. Den foreslåede metode producerer de mest højkvalitets og visuelt tiltalende billeder. Kredit:Xiuxi Pan fra Tokyo Tech
Sammenfattende løser den foreslåede metode begrænsningerne ved konventionelle metoder såsom iterativ billedrekonstruktionsbaseret behandling og CNN-baseret maskinlæring med ViT-arkitekturen, hvilket muliggør erhvervelse af billeder af høj kvalitet på kort tid. Forskerholdet udførte yderligere optiske eksperimenter – som rapporteret i deres seneste publikation i – som tyder på, at det linseløse kamera med den foreslåede rekonstruktionsmetode kan producere højkvalitets og visuelt tiltalende billeder, mens hastigheden af efterbehandlingsberegning er høj nok til at tidsfangst.
"Vi er klar over, at miniaturisering ikke bør være den eneste fordel ved det linseløse kamera. Det linseløse kamera kan anvendes til billeddannelse af usynligt lys, hvor brugen af en linse er upraktisk eller endda umulig. Derudover er den underliggende dimensionalitet af opfanget optisk information af det linseløse kamera er større end to, hvilket gør one-shot 3D-billeddannelse og post-capture genfokusering mulig. Vi udforsker flere funktioner ved det linseløse kamera. Det ultimative mål med et objektivløst kamera er at være miniature-men alligevel mægtig. Vi er begejstret for at være førende i denne nye retning for næste generations billedbehandlings- og sensorløsninger," siger hovedforfatteren af undersøgelsen, Mr. Xiuxi Pan fra Tokyo Tech, mens han taler om deres fremtidige arbejde. + Udforsk yderligere
Udvidelse af infrarød mikrospektroskopi med Lucy-Richardson-Rosen beregningsrekonstruktionsmetode
 Varme artikler
Varme artikler
-
 Kontrol af kvante:Simuleringer afslører detaljer om, hvordan partikler interagererEn partikels spin påvirker den retning, den vil bevæge sig. Hvis de to partikler bevæger sig i bestemte retninger, de vil kollidere med hinanden og yderligere påvirke den retning, de bevæger sig, som
Kontrol af kvante:Simuleringer afslører detaljer om, hvordan partikler interagererEn partikels spin påvirker den retning, den vil bevæge sig. Hvis de to partikler bevæger sig i bestemte retninger, de vil kollidere med hinanden og yderligere påvirke den retning, de bevæger sig, som -
 Big Bang Theory får råb til NobelprismeddelelsenUlf Danielsson, medlem af Nobeludvalget taler under offentliggørelsen af vinderne af Nobelprisen i fysik 2019 under pressemøde på Royal Swedish Academy of Sciences i Stockholm, Sverige, tirsdag den
Big Bang Theory får råb til NobelprismeddelelsenUlf Danielsson, medlem af Nobeludvalget taler under offentliggørelsen af vinderne af Nobelprisen i fysik 2019 under pressemøde på Royal Swedish Academy of Sciences i Stockholm, Sverige, tirsdag den -
 Forskere validerer flere udsvingsteorier for første gangForskere testede eksperimentelt differentialfluktuationssætningen ved hjælp af en optisk svævet nanosfære, som kan være fanget i luften kontinuerligt i 65 uger, erhverve store datasæt. Kredit:Tongcang
Forskere validerer flere udsvingsteorier for første gangForskere testede eksperimentelt differentialfluktuationssætningen ved hjælp af en optisk svævet nanosfære, som kan være fanget i luften kontinuerligt i 65 uger, erhverve store datasæt. Kredit:Tongcang -
 Flydende heliumfrie SRF-hulrum kan gøre industrielle applikationer praktiskeKobber/Niobium/Niobium Tinhulrum forbundet med kryokøleren. Kredit:US Department of Energy Byggestenene i superledende acceleratorer er superledende radiofrekvens (SRF) hulrum fremstillet primært
Flydende heliumfrie SRF-hulrum kan gøre industrielle applikationer praktiskeKobber/Niobium/Niobium Tinhulrum forbundet med kryokøleren. Kredit:US Department of Energy Byggestenene i superledende acceleratorer er superledende radiofrekvens (SRF) hulrum fremstillet primært