


Forbinder prikkerne mellem stemme og et menneskeligt ansigt
Kredit:arXiv:1905.09773 [cs.CV]
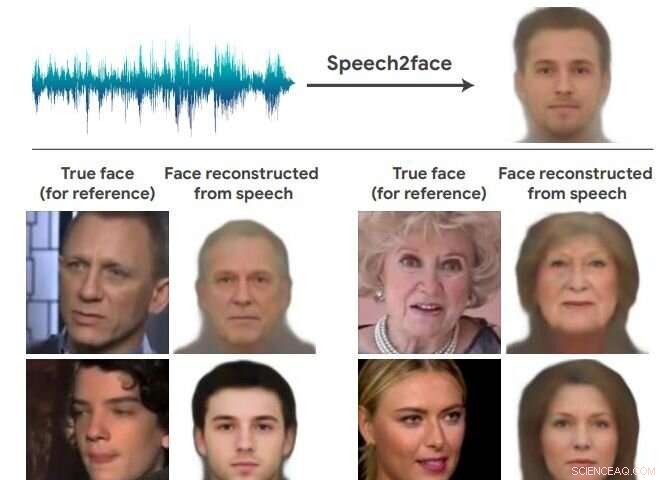
Endnu engang, teams med kunstig intelligens driller det umuliges rige og leverer overraskende resultater. Dette hold i nyhederne fandt ud af, hvordan en persons ansigt kan se ud, bare baseret på stemme. Velkommen til Speech2Face. Forskerholdet fandt en måde at rekonstruere nogle menneskers meget grove lighed baseret på korte lydklip.
Papiret, der beskriver deres arbejde, er op på arXiv, og har titlen "Speech2Face:Learning the Face Behind a Voice." Forfattere er Tae-Hyun Åh, Tali Dekel, Changil Kim, Inbar Mosseri, William Freemany, Michael Rubinstein og Wojciech Matusiky. "Vores mål i dette arbejde er at undersøge, i hvor høj grad vi kan udlede, hvordan en person ser ud fra den måde, de taler."
De evaluerer og kvantificerer numerisk, hvordan og på hvilken måde, deres Speech2Face -rekonstruktioner fra lyd ligner højttalernes sande ansigtsbilleder.
Forfatterne ønskede tilsyneladende at sikre sig, at deres hensigt var klar, ikke som et forsøg på at forbinde stemmer med billeder af de specifikke mennesker, der rent faktisk talte, da "vores mål ikke er at forudsige et genkendeligt billede af det nøjagtige ansigt, men snarere for at fange dominerende ansigtstræk hos personen, der er korreleret med inputtalen."
Forfatterne på GitHub sagde, at de også følte det vigtigt at diskutere i papiret etiske overvejelser "på grund af den potentielle følsomhed af ansigtsinformation."
De sagde i deres papir, at deres metode "ikke kan genskabe en persons sande identitet fra deres stemme (dvs. et nøjagtigt billede af deres ansigt). Dette skyldes, at vores model er trænet til at fange visuelle træk (relateret til alder, køn, osv.), der er fælles for mange individer, og kun i tilfælde, hvor der er stærke nok beviser til at forbinde disse visuelle funktioner med vokal-/taleegenskaber i dataene."
De sagde også, at modellen vil producere gennemsnitligt udseende ansigter - kun gennemsnitligt udseende ansigter - med karakteristiske visuelle træk korreleret med inputtalen.
Jackie Snow, Hurtigt selskab , skrev om deres metode. Snow sagde, at datasættet, de tog, bestod af klip fra YouTube. Speech2Face blev uddannet af forskere i videoer fra internettet, der viste folk tale. De skabte en neural netværksbaseret model, der "lærer vokalegenskaber forbundet med ansigtstræk fra videoerne."
Sne tilføjet, "Nu, når systemet hører en ny lydbid, AI'en kan bruge det, den har lært, til at gætte, hvordan ansigtet kan se ud."
Neurohive diskuterede deres arbejde:"Fra videoerne, de udtrækker tale-ansigtspar, som er fodret ind i to grene af arkitekturen. Billederne er kodet ind i en latent vektor ved hjælp af den forudtrænede ansigtsgenkendelsesmodel, mens bølgeformen føres ind i en stemmekoder i form af et spektrogram, for at udnytte kraften i konvolutionsarkitekturer. Den kodede vektor fra stemmekoderen føres ind i ansigtsdekoderen for at opnå den endelige ansigtsrekonstruktion."
Man kan også få en præcis rapport om deres metode og hvordan de testede med en artikel om Packt :
"De sagde, at de yderligere evaluerede og numerisk kvantificerede, hvordan deres Speech2Face rekonstruerer, opnår resultater direkte fra lyd, og hvordan det ligner højtalernes sande ansigtsbilleder. For det, de testede deres model både kvalitativt og kvantitativt på AVSpeech-datasættet og VoxCeleb-datasættet."
Hvordan kan deres resultater hjælpe virkelige applikationer? De sagde, "Vi mener, at forudsigelse af ansigtsbilleder direkte fra stemmen kan understøtte nyttige applikationer, såsom at knytte et repræsentativt ansigt til telefon-/videoopkald baseret på talerens stemme."
Hvorfor deres arbejde betyder noget:Tænk mønstre. "Tidligere forskning har udforsket metoder til at forudsige alder og køn ud fra tale, " sagde Sne, "men i dette tilfælde forskerne hævder, at de også har opdaget korrelationer med nogle ansigtsmønstre."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Tape, briller giver forskere mulighed for at omgå Face IDKredit:CC0 Public Domain I september 2018, en tech-watcher var beundringsværdigt ærlig:Hvis du er en normal person, Apple FaceID er grundlæggende sikkert, hun sagde. Men så denne tech-watcher, Rac
Tape, briller giver forskere mulighed for at omgå Face IDKredit:CC0 Public Domain I september 2018, en tech-watcher var beundringsværdigt ærlig:Hvis du er en normal person, Apple FaceID er grundlæggende sikkert, hun sagde. Men så denne tech-watcher, Rac -
 Forskere skaber vandafvisende elektronisk hud med selvhelbredende evnerForreste række, fra venstre:Li Si, doktorand, Institut for Materialevidenskab og Teknik, NUS Det Tekniske Fakultet; Dr Tan Yu Jun, forskningsstipendiat, Biomedicinsk Institut for Global Sundhedsforskn
Forskere skaber vandafvisende elektronisk hud med selvhelbredende evnerForreste række, fra venstre:Li Si, doktorand, Institut for Materialevidenskab og Teknik, NUS Det Tekniske Fakultet; Dr Tan Yu Jun, forskningsstipendiat, Biomedicinsk Institut for Global Sundhedsforskn -
 Bremse indendørs luftforurening i IndienKredit:CC0 Public Domain Jorden rundt, mere end 3 milliarder mennesker - næsten halvdelen af verdens befolkning - laver deres mad ved hjælp af fast brændsel som brænde og trækul på åben ild elle
Bremse indendørs luftforurening i IndienKredit:CC0 Public Domain Jorden rundt, mere end 3 milliarder mennesker - næsten halvdelen af verdens befolkning - laver deres mad ved hjælp af fast brændsel som brænde og trækul på åben ild elle -
 Ser ind i kroppen med indirekte lysOversigt over metoden. Anvendelsesscene for enheden til at fange venen i hudens arm (a) og sammenligning mellem et foto (b) og vores metode (c). Kredit:Hiroyuki Kubo Lys giver alle vores visuelle
Ser ind i kroppen med indirekte lysOversigt over metoden. Anvendelsesscene for enheden til at fange venen i hudens arm (a) og sammenligning mellem et foto (b) og vores metode (c). Kredit:Hiroyuki Kubo Lys giver alle vores visuelle
- Undersøgelse identificerer kemiske blandinger som mulige alternative kølemidler
- Metastabile metalliske nanopartikler kan finde anvendelse i elektronik, optik
- Beskæftigelsesrealiteter matcher ikke folks drømme
- Energiomstilling 2030:Akademier beskriver vejen til CO2-neutralitet i Europa
- Nitrogen kommer i den hurtige bane til kemisk syntese
- Nanotynd piezoelektrik fremmer selvdrevet elektronik