


Baidu-forskere udvikler en ny auto-tuning-ramme for autonome køretøjer
Datadrevet autonom kørselsplanlægger på Apollo-platformen. Kredit:Fan et al.
Forskere hos det kinesiske multinationale teknologiselskab Baidu har for nylig udviklet en datadrevet autotuning-ramme for selvkørende køretøjer baseret på Apollo autonome køreplatform. Rammen, præsenteret i et papir, der er forududgivet på arXiv, består af en ny forstærkende læringsalgoritme og en offline træningsstrategi, samt en automatisk metode til indsamling og mærkning af data.
En bevægelsesplanlægger til autonom kørsel er et system designet til at generere en sikker og komfortabel bane for at nå en ønsket destination. At designe og tune disse systemer til at sikre, at de fungerer godt under forskellige kørselsforhold, er en vanskelig opgave, som flere virksomheder og forskere verden over i øjeblikket forsøger at tackle.
"Bevægelsesplanlægning for selvkørende biler har en masse udfordrende problemer, "Fan Haoyang, en af de forskere, der har udført undersøgelsen, fortalte Tech Xplore. "En hovedudfordring er, at den skal håndtere tusindvis af forskellige scenarier. Typisk, vi definerer en belønning/omkostningsfunktionel tuning, der kan tilpasse disse forskelle i scenarier. Imidlertid, vi synes, det er en svær opgave."
Typisk, belønning-omkostning funktionel tuning kræver omfattende arbejde på vegne af forskere, samt ressourcer og tid brugt på både simuleringer og vejtests. Ud over, miljøet kan ændre sig dramatisk over tid, og efterhånden som køreforholdene bliver mere komplicerede, justering af bevægelsesplanlæggerens ydeevne bliver stadig sværere.

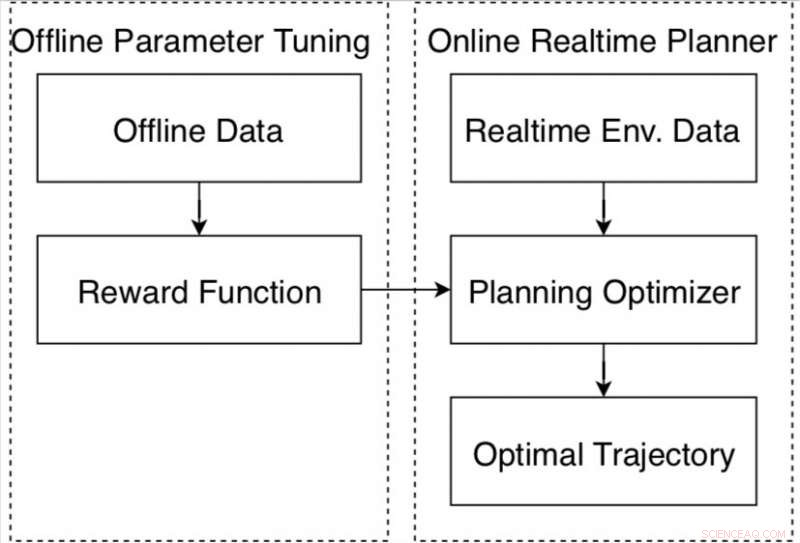
Algoritme tuning loop til bevægelsesplanlæggeren i Apollo autonome køreplatform. Kredit:Fan et al.
"For systematisk at løse dette problem, vi udviklede en datadrevet autotuning-ramme baseret på Apollo autonome kørselsramme, " Fan sagde. "Idéen med auto-tuning er at lære parametre fra menneskelige demonstrerede køredata. For eksempel, vi vil gerne forstå ud fra data, hvordan menneskelige chauffører balancerer hastighed og kørekomfort med forhindringsafstande. Men i mere komplicerede scenarier, for eksempel, en fyldt by, hvad kan vi lære af menneskelige chauffører?"
Den automatiske tuning-ramme, der er udviklet hos Baidu, inkluderer en ny forstærkende læringsalgoritme, som kan lære af data og forbedre deres ydeevne over tid. Sammenlignet med de fleste inverse forstærkningsindlæringsalgoritmer, det kan effektivt anvendes til forskellige kørselsscenarier.
Rammen inkluderer også en offline træningsstrategi, at tilbyde en sikker måde for forskere at justere parametre, før et autonomt køretøj testes på offentlig vej. Den indsamler også data fra ekspertchauffører og information om miljøet, automatisk mærkning af disse, så de kan analyseres ved hjælp af forstærkningsindlæringsalgoritmen.
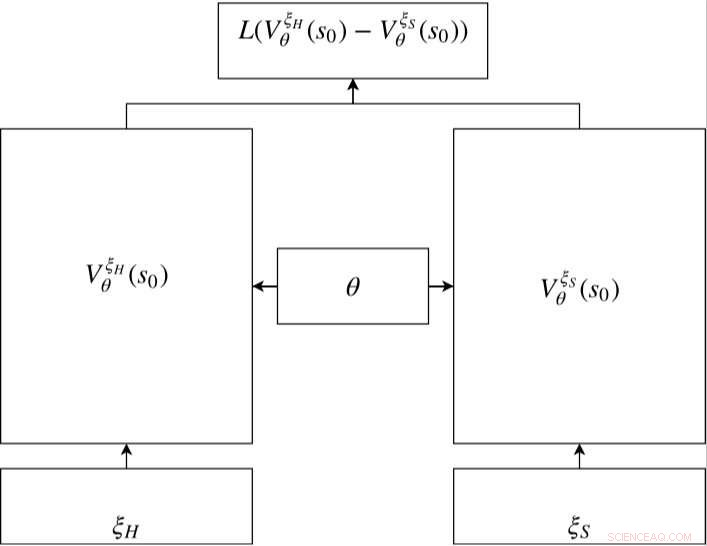
Siamesisk netværk i RC-IRL. Værdinetværkene for både de menneskelige og de samplede baner deler de samme netværksparameterindstillinger. Tabsfunktionen evaluerer forskellen mellem de samplede data og den genererede bane via værdinetværkets output. Kredit:Fan et al.
"Jeg tror, vi har udviklet en sikker pipeline til at lave et maskinlæringsskalerbart system ved at bruge menneskelige demonstrationsdata, " Fan sagde. "De menneskelige demodata med åben løkke indsamles og behøver ikke ekstra mærkning. Da træningsprocessen også er offline, vores metode er velegnet til autonom kørselsplanlægning, opretholdelse af offentlig trafiksikkerhed."
Forskerne evaluerede en bevægelsesplanlægger, der var indstillet ved hjælp af deres ramme både på simuleringer og test af offentlige veje. Sammenlignet med eksisterende tilgange, deres datadrevne metode var bedre i stand til at tilpasse sig forskellige kørselsscenarier, præsterer konsekvent godt under forskellige forhold.
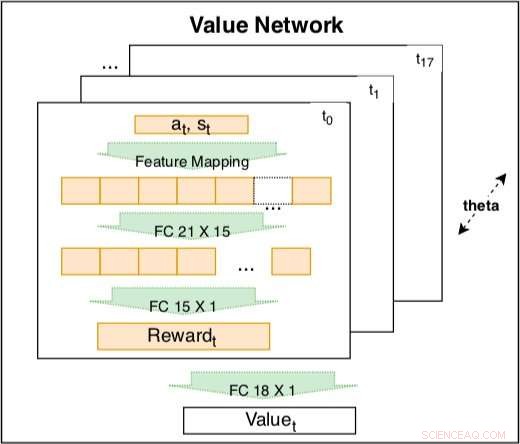
Værdinetværket inde i den siamesiske model bruges til at fange køreadfærd baseret på kodede funktioner. Netværket er en træningsbar lineær kombination af kodede belønninger på forskellige tidspunkter t =t0, ..., t17. Vægten af den kodede belønning er en indlærelig tidsforfaldsfaktor. Den kodede belønning inkluderer et inputlag med 21 rå funktioner og et skjult lag med 15 noder til at dække mulige interaktioner. Parametrene for belønningen på forskellige tidspunkter deler den samme θ for at opretholde konsistens. Kredit:Fan et al.
"Vores forskning er baseret på Baidu Apollo Open Source Autonomous Driving platform, " Fan sagde. "Vi håber, at flere og flere mennesker fra den akademiske verden og industrien kan bidrage til det autonome kørende økosystem gennem Apollo. I fremtiden, vi planlægger at forbedre den nuværende ramme for Baidu Apollo til et skalerbart maskinlæringssystem, der systematisk kan forbedre scenariedækningen af selvkørende biler."
© 2018 Tech Xplore
Sidste artikelLuftforurening dis kan sætte en bule i solenergi
Næste artikelRyanair anerkender kabinepersonalets fagforening i Irland
 Varme artikler
Varme artikler
-
 Pas på med at replikere sexisme i AI, eksperter advarerAI er videnskaben om programmering af maskiner eller computere til at gengive menneskelige processer, som læring og beslutningstagning Kunstig intelligens kunne efterligne menneskelig skævhed, her
Pas på med at replikere sexisme i AI, eksperter advarerAI er videnskaben om programmering af maskiner eller computere til at gengive menneskelige processer, som læring og beslutningstagning Kunstig intelligens kunne efterligne menneskelig skævhed, her -
 Nostalgispil:Dyr foldbar Motorola Razr kommer i forsalg 26. januar, hos Verizon, WalmartEn sexet telefon fra fortiden er ved at ramme comeback-sporet. Motorola razr kommer i forsalg i Nordamerika den 26. januar, udelukkende hos Verizon, Walmart og på Motorola.com. Den kommer i butikkern
Nostalgispil:Dyr foldbar Motorola Razr kommer i forsalg 26. januar, hos Verizon, WalmartEn sexet telefon fra fortiden er ved at ramme comeback-sporet. Motorola razr kommer i forsalg i Nordamerika den 26. januar, udelukkende hos Verizon, Walmart og på Motorola.com. Den kommer i butikkern -
 Facebook siger klar til ny californisk privatlivslovI januar 2020, Facebook vil frigive en meddelelse, der forklarer ændringer i datapolitikken foretaget på grund af CCPA-krav, og hvordan folk kan udøve deres juridiske rettigheder i henhold til loven
Facebook siger klar til ny californisk privatlivslovI januar 2020, Facebook vil frigive en meddelelse, der forklarer ændringer i datapolitikken foretaget på grund af CCPA-krav, og hvordan folk kan udøve deres juridiske rettigheder i henhold til loven -
 Apple ser starpower for lancering af ny streamingtjenesteApple er klar til at tage yderligere skridt inden for tjenester, herunder streaming-tv og nyhedsabonnementer med en lanceringsbegivenhed, der forventes den 25. marts Er det Hollywood-tid for Apple
Apple ser starpower for lancering af ny streamingtjenesteApple er klar til at tage yderligere skridt inden for tjenester, herunder streaming-tv og nyhedsabonnementer med en lanceringsbegivenhed, der forventes den 25. marts Er det Hollywood-tid for Apple
- Lokal nyhedsmængde øger ikke prosocial adfærd under COVID-19
- Brun dværg opdaget i CoRoT-20-systemet
- Eagle-eyed machine learning algoritme overgår menneskelige eksperter
- UNEPs chef opfordrer Kina til at gøre mere på klimaområdet
- Suomi NPP-satellit finder den tropiske storm Leepi nær det sydlige Japan
- Turbulente tider afsløret på Asteroid 4 Vesta