


Forskere bruger dyb læring til at bygge et automatisk talegenkendelsessystem for at hjælpe med at bevare Seneca-sproget

Venstre til højre, Ray Ptucha, adjunkt i computeringeniør, Robbie Jimerson, datalogi doktorand, både fra RIT, og Emily Prud'hommeaux, adjunkt i datalogi, leder NSF-projektet til at bruge kunstig intelligens-teknologi til at bevare Seneca-sproget. Kredit:A. Sue Weisler/RIT
Et nyt forskningsprojekt ved Rochester Institute of Technology vil hjælpe med at sikre, at det truede sprog i Seneca Indian Nation vil blive bevaret. Brug af dyb læring, en form for kunstig intelligens, RIT-forskere bygger en automatisk talegenkendelsesapplikation til at dokumentere og transskribere Seneca-folkets traditionelle sprog. Værket er også beregnet til at være en teknologisk ressource til at bevare andre sjældne eller forsvindende sprog.
"Motivationen for dette er personlig. Det første skridt i bevarelsen og revitaliseringen af vores sprog er dokumentation af det, " sagde Robert Jimerson (Seneca), en ph.d.-studerende i computer- og informationsvidenskab ved RIT og medlem af forskerteamet. Han samlede stammens ældste og nære venner, alle højttalere fra Seneca, at hjælpe med at producere lyd- og tekstdokumentation af dette indianske sprog, der tales flydende af færre end 50 personer.
Som alle sprog, Seneca har forskellige dialekter. Det giver også unikke udfordringer på grund af dets komplekse system til at bygge nye ord, hvor en hel sætning kan udtrykkes i et enkelt ord.
Jimerson er i stand til at bygge bro mellem teknologien og sproget.
"Under kølerhjelmen, det er data. Med mange modersmål, du har ikke den mængde data, " han sagde, forklarer, at nogle sprog, mens man taler, har måske ikke så mange formelle sproglige værktøjer – ordbøger, grammatiske materialer eller omfattende klasser for ikke-modersmålstalere, svarende til dem for spansk eller kinesisk. "En af de dyreste og mest tidskrævende processer til at dokumentere sprog er at indsamle og transskribere det. Vi ser på at tage dybe netværk og måske ændre arkitekturen, lave nogle syntetiske data for at skabe flere data, men hvordan får man det til at fungere i deep learning? Hvordan udvider du data, du allerede har?"
Processen med at opnå data bliver koordineret af et vidtfavnende team, der inkluderer Jimerson; projektets hovedefterforsker Emily Prud'hommeaux, assisterende professor i datalogi ved Boston College og forskningsfakultet i RIT's College of Liberal Arts; Ray Ptucha, assisterende professor i computerteknik ved RIT's Kate Gleason College of Engineering og ekspert i deep learning-systemer og -teknologier; og Karen Michaelson, professor i lingvistik, State University of New York i Buffalo. Forskerholdet blev tildelt $181, 682 i finansiering over fire år fra National Science Foundation for "Collaborative Research:Deep learning talegenkendelse til dokument Seneca og andre akut ressourcesvage sprog."
"Dette er et spændende projekt, fordi det samler mennesker fra så mange discipliner og baggrunde, fra ingeniørvidenskab og datalogi til lingvistik og sprogpædagogik, " sagde Prud'hommeaux. "Ud over at gøre det muligt for os at udvikle banebrydende teknologi, dette projekt støtter bachelor- og kandidatstuderende og engagerer medlemmer af et oprindeligt samfund, som få mennesker ved er lige her i det vestlige New York."
Forskerne startede projektet i slutningen af juni, samle fællesskabets medlemmer og lingvister til dataindsamling – erhverve og oversætte nuværende og nye, originale optagelser af Seneca-samtaler, der derefter konverterer data til tekstoutput ved hjælp af deep learning-modeller.
"Det, du virkelig prøver at gøre, er at finde den linje mellem de nye data, du kan få, og ændringen af arkitekturen i et netværk, " forklarede Jimerson.
Siden sommeren har holdet har lidt over 50 timers optaget materiale med folk, der arbejder fuld tid på oversættelserne, som inkluderer at opdele sproget i individuelle fonetiske symboler og bruge disse oplysninger til at begynde at træne modellerne.
"Vi bruger en proces kaldet transfer learning, som starter med en model trænet med let tilgængelig engelsk tale for at få det grundlæggende, indledende uddannelse til systemet, så genoptræner vi de neurale netværk og finjusterer det mod Seneca-sproget. Vi får meget gode resultater, " sagde Ptucha, som er ekspert i deep learning systemer og teknologier. Deep learning teknologi består af flere lag af kunstige neuroner, organiseret i et mere og mere abstrakt hierarki. Disse arkitekturer har produceret state-of-the-art resultater på alle typer mønstergenkendelsesproblemer, herunder billed- og talegenkendelsesapplikationer.
"Ingen har virkelig prøvet dette før, træning af en automatiseret talegenkendelsesmodel på noget så ressourcebegrænset som Seneca. Robbie er eksperten i at transskribere Seneca og træne de andre i, hvordan man gør dette. Han er en ret sjælden fyr, " sagde Ptucha,
Dette nuværende projekt er en fortsættelse af Jimersons arbejde med at udvide de sproglige ressourcer, der er tilgængelige for hans samfund. I 2013 mens han var kandidatstuderende på RIT's Golisano College of Computing and Information Sciences, han udviklede en online Seneca sprogoversættelsesordbog til Seneca Language Revitalization Program. Projektet blev finansieret af Seneca Nation og tildelt RIT's Future Steward's Program.
 Varme artikler
Varme artikler
-
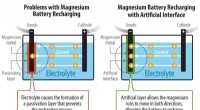 Forskning overvinder store tekniske forhindringer i magnesium-metal-batterierIllustration viser, hvordan NREL-forskere har adresseret problemet med at lave et genopladeligt magnesiumbatteri. Kredit:John Frenzl / NREL Forskere ved Department of Energys National Renewable En
Forskning overvinder store tekniske forhindringer i magnesium-metal-batterierIllustration viser, hvordan NREL-forskere har adresseret problemet med at lave et genopladeligt magnesiumbatteri. Kredit:John Frenzl / NREL Forskere ved Department of Energys National Renewable En -
 Bliver brintdrevne biler gradvist mainstream i Europa?Kredit:VoodooDot, Shutterstock Et EU -initiativ vil anvende brændstofcelleelektriske køretøjer i tre europæiske hovedstæder som taxaer, privatudlejning og politibiler. Trækket vil fremskynde deres
Bliver brintdrevne biler gradvist mainstream i Europa?Kredit:VoodooDot, Shutterstock Et EU -initiativ vil anvende brændstofcelleelektriske køretøjer i tre europæiske hovedstæder som taxaer, privatudlejning og politibiler. Trækket vil fremskynde deres -
 Huawei flytter forskning fra fjendtlige USA til Canada:grundlæggerHuaweis center for forskning og udvikling vil blive flyttet ud af USA og vil blive flyttet til Canada, fortalte virksomhedens grundlægger og administrerende direktør Ren Zhengfei til avisen Globe and
Huawei flytter forskning fra fjendtlige USA til Canada:grundlæggerHuaweis center for forskning og udvikling vil blive flyttet ud af USA og vil blive flyttet til Canada, fortalte virksomhedens grundlægger og administrerende direktør Ren Zhengfei til avisen Globe and -
 Thyssenkrupp CEO trækker sig efter Tata-fusionsaftaleHeinrich Hiesinger, administrerende direktør for den tyske industrikoncern ThyssenKrupp, har meddelt sin afgang efter fusionen af stålfremstillingsvirksomheder med Indiens Tata Den tyske industr
Thyssenkrupp CEO trækker sig efter Tata-fusionsaftaleHeinrich Hiesinger, administrerende direktør for den tyske industrikoncern ThyssenKrupp, har meddelt sin afgang efter fusionen af stålfremstillingsvirksomheder med Indiens Tata Den tyske industr
- spanske romaer, COVID-19 og ulighederne ved en pandemi
- Forskere undersøger, hvordan musikere kommunikerer non-verbalt under optræden
- Sådan opløses Iron
- Undersøgelse kortlægger by-landlige oplande og peger på måder at optimere politik- og planlægni…
- Forladte landbrugsområder kan spille en vigtig rolle i genoprettelse af tropiske regnskove
- Første storstilet markedsanalyse af underjordisk cyberkriminalitetsøkonomi