


En ny tilgang til modellering af centrale mønstergeneratorer (CPG'er) i forstærkningslæring
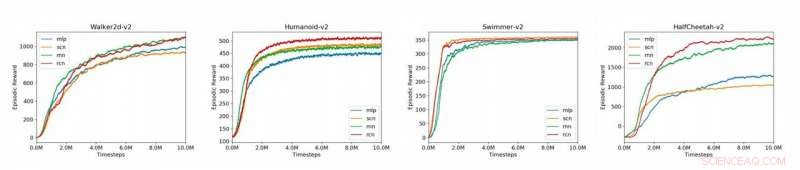
Plots, der sammenligner basislinjemodellerne (MLP, SCN, RNN, RCN) for de 4 MuJoCo-miljøer, der præsenteres i papiret (Humanoid-v2, HalfCheetah-v2, Walker2d-v2, Svømmer-v2). Kredit:Liu et al.
Centrale mønstergeneratorer (CPG'er) er biologiske neurale kredsløb, der kan producere koordinerede rytmiske output uden at kræve rytmiske input. CPG'er er ansvarlige for de fleste rytmiske bevægelser observeret i levende organismer, såsom at gå, vejrtrækning eller svømning.
Værktøjer til effektiv modellering af rytmiske output, når de gives arytmiske input, kan have vigtige anvendelser inden for en række områder, herunder neurovidenskab, robotik og medicin. I forstærkende læring, de fleste eksisterende netværk, der bruges til at modellere lokomotivopgaver, såsom multilayer perceptron (MLP) baseline modeller, undlader at generere rytmiske output i fravær af rytmiske input.
Nylige undersøgelser har foreslået brugen af arkitekturer, der kan opdele et netværks politik i lineære og ikke-lineære komponenter, såsom strukturerede kontrolnet (SCN'er), som viste sig at overgå MLP'er i en række forskellige miljøer. Et SCN omfatter en lineær model for lokal kontrol og et ikke-lineært modul til global kontrol, hvis output kombineres for at producere den politiske handling. Bygger på tidligere arbejde med tilbagevendende neurale netværk (RNN'er) og SCN'er, et team af forskere ved Stanford University har for nylig udtænkt en ny tilgang til modellering af CPG'er i forstærkende læring.
"CPG'er er biologiske neurale kredsløb, der er i stand til at producere rytmiske output i fravær af rytmisk input, "Ademi Adeniji, en af de forskere, der har udført undersøgelsen, fortalte Tech Xplore. "Eksisterende tilgange til modellering af CPG'er i forstærkningslæring inkluderer multilayer perceptron (MLP), en enkel, fuldt tilsluttet neurale netværk, og det strukturerede kontrolnet (SCN), som har separate moduler til lokal og global kontrol. Vores forskningsmål var at forbedre disse basislinjer ved at lade modellen fange tidligere observationer, gør den mindre tilbøjelig til at fejle fra inputstøj."

Skærmbillede af HalfCheetah-miljøet. Kredit:Liu et al.
Det tilbagevendende kontrolnet (RCN) udviklet af Adeniji og hans kolleger adopterer arkitekturen af et SCN, men bruger en vanilje RNN til global kontrol. Dette giver modellen mulighed for at erhverve lokale, global og tidsafhængig kontrol.
"Som SCN, vores RCN opdeler informationsstrømmen i lineære og ikke-lineære moduler, " Nathaniel Lee, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "Intuitivt, det lineære modul, faktisk en lineær transformation, lærer lokale interaktioner, hvorimod det ikke-lineære modul lærer globale interaktioner."
SCN-tilgange bruger en MLP som deres ikke-lineære modul, mens den RCN, som forskerne har udtænkt, erstatter dette modul med en RNN. Som resultat, deres model får en 'hukommelse' af tidligere observationer, kodet af RNN's skjulte tilstand, som den derefter bruger til at generere fremtidige handlinger.
Forskerne evaluerede deres tilgang på OpenAI Gym platformen, et fysikmiljø for forstærkningslæring, samt på multi-joint dynamik med kontrakt (Mu-JoCo) opgaver. Deres RCN matchede eller overgik andre baseline MLP'er og SCN'er i alle testede miljøer, effektivt at lære lokal og global kontrol, samtidig med at man tilegner sig mønstre fra tidligere sekvenser.

Skærmbillede af det menneskelige miljø. Kredit:Liu et al.
"CPG'er er ansvarlige for et stort antal rytmiske biologiske mønstre, "Jason Zhao, en anden forsker involveret i undersøgelsen, sagde. "Evnen til at modellere CPG-adfærd kan med succes anvendes på områder som medicin og robotteknologi. Vi håber også, at vores forskning vil fremhæve effektiviteten af lokal/global kontrol såvel som tilbagevendende arkitekturer til modellering af central mønstergenerering i forstærkningslæring."
Resultaterne indsamlet af forskerne bekræfter potentialet i SCN-lignende strukturer til at modellere CPG'er til forstærkende læring. Deres undersøgelse tyder også på, at RNN'er er særligt effektive til modellering af lokomotivopgaver, og at adskillelse af lineære og ikke-lineære kontrolmoduler kan forbedre en models ydeevne betydeligt.
"Indtil nu, vi trænede kun vores model ved hjælp af evolutionære strategier (ES), en off-gradient optimizer, " sagde Vincent Liu, en af forskerne involveret i undersøgelsen. "I fremtiden, vi planlægger at udforske dens ydeevne, når vi træner den med proksimal politikoptimering (PPO), en on-gradient optimizer. Derudover fremskridt inden for naturlig sprogbehandling har vist, at konvolutionelle neurale netværk er effektive erstatninger for tilbagevendende neurale netværk, både i ydelse og beregning. Vi kunne derfor overveje at eksperimentere med en tidsforsinkelse neural netværksarkitektur, som anvender 1-D foldning langs tidsaksen for tidligere observationer."
© 2019 Science X Network
Sidste artikelForskere skaber 3-D-printede bløde mesh-robotter
Næste artikelBA-ejer siger ikke vil byde på Norwegian
 Varme artikler
Varme artikler
-
 Fem ting at vide om selfie-økonomienSelfie-spots er blevet en del af turistindustrien, med nogle turarrangører, der lover de bedste steder at snappe dig selv Længe afvist som et symptom på narcissistisk ungdomskultur, den knap så yd
Fem ting at vide om selfie-økonomienSelfie-spots er blevet en del af turistindustrien, med nogle turarrangører, der lover de bedste steder at snappe dig selv Længe afvist som et symptom på narcissistisk ungdomskultur, den knap så yd -
 Robotter kan lære at støtte lærere i klassesessionerEt barn interagerer med robotvejlederen, mens en lærer giver vejledning. Forskning viste, at robotten derefter var i stand til at støtte børnene i den samme aktivitet selvstændigt. Kredit:University o
Robotter kan lære at støtte lærere i klassesessionerEt barn interagerer med robotvejlederen, mens en lærer giver vejledning. Forskning viste, at robotten derefter var i stand til at støtte børnene i den samme aktivitet selvstændigt. Kredit:University o -
 Juryen bestemmer, at Apple skylder Qualcomm $ 31 millioner for patentkrænkelseI denne 3. januar, 2019, filfoto vises Apple -logoet i Apple -butikken i Brooklyn -bydelen New York. En jury meddelte dommen fredag, 15. marts, at Apple skulle betale 31 millioner dollars i erstatning
Juryen bestemmer, at Apple skylder Qualcomm $ 31 millioner for patentkrænkelseI denne 3. januar, 2019, filfoto vises Apple -logoet i Apple -butikken i Brooklyn -bydelen New York. En jury meddelte dommen fredag, 15. marts, at Apple skulle betale 31 millioner dollars i erstatning -
 Har Facebook-data hjulpet Trump? Great Hack udforsker skandaleDenne 19. feb. 2014, fil foto, viser WhatsApp- og Facebook-appikoner på en smartphone i New York. Er Big Tech på vej mod et stort brud? Føderale tilsynsmyndigheder er allerede i gang med at undersøge
Har Facebook-data hjulpet Trump? Great Hack udforsker skandaleDenne 19. feb. 2014, fil foto, viser WhatsApp- og Facebook-appikoner på en smartphone i New York. Er Big Tech på vej mod et stort brud? Føderale tilsynsmyndigheder er allerede i gang med at undersøge
- Fysikere måler van der Waals kræfter fra individuelle atomer for første gang
- Orkanen Ida kan være en af de bedst observerede landfaldende orkaner
- Hvordan Comcast forsøger at ændre kabelspillet
- Switch-in-a-celle elektrificerer livet
- Sådan mærkes et histogram
- For blinde, en enhed på bilruden giver en haptisk oplevelse af naturskøn udsigt