


Mozilla-initiativet hjælper stemmeteknologispillere via multi-sprog datasæt
Det lyder måske som en mundfuld, men det betyder virkelig meget. Mozilla taler om det "største til dato transskriberede stemmedatasæt i det offentlige domæne." Oversættelse:Over 14, 000 mennesker. På 18 sprog. Af næsten 1, 400 timer (1, 368 for at være præcis) af optaget stemme. Velkommen til et initiativ kaldet Common Voice.
Dette er, hvad Mozilla-meddelelsen sagde, i form af en blog torsdag fra George Roter.
"I dag, vi er glade for at dele vores første flersprogede datasæt med 18 sprog repræsenteret, herunder engelsk, Fransk, tysk og mandarin-kinesisk (traditionel), men også for eksempel walisisk og kabylsk. Alt i alt, det nye datasæt omfatter ca. 1, 400 timers stemmeklip fra mere end 42, 000 mennesker."
Bidragydere til projektet har faglige specialer, der spænder fra ph.d.-kandidater i talegenkendelse til maskinlæringsforskere til en professor i computerlingvistik. Som sådan, indsatsen repræsenterer et globalt fællesskab af stemmebidragydere sammen med, hvad Mozilla krediterede som "passionerede frivillige."
Formålet med Common Voice er at hjælpe med at lære maskiner, hvordan rigtige mennesker taler. Kort om, det har udviklet sig til en massiv samling af stemmeklip på snesevis af sprog. Hvad er det næste:Det fulde datasæt vil være tilgængeligt til download på Common Voice-webstedet.
Det ser ud til, at Mozilla-holdets bidragydere også har fundet frem til de uundgåelige smertepunkter. Bloggen nævnte disse punkter. "Folk, der bidrager, ser ikke kun fremskridt pr. sprog i registrering og validering, men har også forbedrede prompter, der varierer fra klip til klip; ny funktionalitet at gennemgå, genindspille, og spring klip over som en integreret del af oplevelsen; evnen til at bevæge sig hurtigt mellem tale og lytte; samt en funktion til at fravælge tale til en session."
Det lyder som sjovt eller en akademisk sandkasse, men faktisk er der mere solide forhåbninger blandt dem, der har bidraget til at opbygge dets korpus.
I 2019, Mariella Moon ind Engadget har bemærket, at rækken af sprog nu inkluderer hollandsk, Hakha-Chin, Esperanto, Farsi, baskisk, Spansk, Fransk, Tysk, Mandarin kinesisk (traditionel), walisisk og kabylsk.
TechRadar Olivia Tambini, sagde, "Ved at tilbyde et enormt bibliotek af menneskelige stemmer på en række sprog gratis, Mozilla åbner muligvis dørene for virksomheder, der ikke har Apples ressourcer, Amazon, og Google, at udvikle deres egne stemmeassistenter."
En anden fordel involverer Mozilla selv. Mariella Moon ind Engadget sagde, "Organisationen selv planlægger at bruge de klip, den indsamler til at forbedre sin tale-til-tekst, Tekst-til-tale- og DeepSpeech-motorer."
Roter sagde, enkelt og greit, "Vores mål er både at frigive stemmeaktiverede produkter selv, samtidig med at de støtter forskere og mindre aktører."
Bemærk, at praleriet tilhører den største, ikke den eneste, datasæt af sin art. Mozilla ønskede, at besøgende på webstedet skulle vide, at det var den største, ikke den eneste, og sagde også, at besøgende på siden med tiden kan "se på denne side som et referencehub for andre open source-taledatasæt."
Hvis du besøger Common Voice-siden, får du beskeden om deres store ambitioner. "Vi bygger, " sagde Mozilla. Og hvad bygger de? En "open source, flersproget datasæt af stemmer, som alle kan bruge til at træne taleaktiverede applikationer."
Bidragydere kan tilmelde sig at levere metadata som deres alder, køn, og accent. Stemmeklip er igen tagget med information, der er nyttig til træning af talemaskiner.
© 2019 Science X Network
Sidste artikelForskere skaber brandsikker, selvdrevet sensor
Næste artikelDa Concorde første gang kom til himlen for 50 år siden
 Varme artikler
Varme artikler
-
 Australien kan fængselsdirektører på sociale medier fange for at have udvist voldAustraliens statsadvokat Christian Porter, venstre, og kommunikationsminister Mitch Fifield holder et pressemøde i parlamentshuset, i Canberra, Onsdag, 4. april kl. 2019. Australiens parlament vedtog
Australien kan fængselsdirektører på sociale medier fange for at have udvist voldAustraliens statsadvokat Christian Porter, venstre, og kommunikationsminister Mitch Fifield holder et pressemøde i parlamentshuset, i Canberra, Onsdag, 4. april kl. 2019. Australiens parlament vedtog -
 Affaldsplast i beton kan understøtte bæredygtigt byggeri i IndienDen Bath-ledede forskning har vist, hvordan udskiftning af 10 procent af sand i beton med affaldsplastik kan bidrage til at reducere de enorme mængder plastikaffald på Indiens gader, og håndtere en na
Affaldsplast i beton kan understøtte bæredygtigt byggeri i IndienDen Bath-ledede forskning har vist, hvordan udskiftning af 10 procent af sand i beton med affaldsplastik kan bidrage til at reducere de enorme mængder plastikaffald på Indiens gader, og håndtere en na -
 Stemmekommando ovne, robotter til kæledyr på udstilling på Berlins IFA tech messeEn Pet Fitness-robot kan holde styr på, hvor meget aktivitet dyret har haft Europas største teknologimesse, Berlins IFA, fremviser en strøm af produktlanceringer indtil onsdag. Her er fem trends o
Stemmekommando ovne, robotter til kæledyr på udstilling på Berlins IFA tech messeEn Pet Fitness-robot kan holde styr på, hvor meget aktivitet dyret har haft Europas største teknologimesse, Berlins IFA, fremviser en strøm af produktlanceringer indtil onsdag. Her er fem trends o -
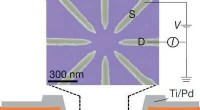 Hjernelignende netværk bruger uorden til at opdage ordenSet ovenfra (scannende elektronmikroskopi) og sidebillede (tegning) af den bor-dopede struktur. Kredit:University of Twente Et uordentligt netværk, der er i stand til at opdage ordnede mønstre:Det
Hjernelignende netværk bruger uorden til at opdage ordenSet ovenfra (scannende elektronmikroskopi) og sidebillede (tegning) af den bor-dopede struktur. Kredit:University of Twente Et uordentligt netværk, der er i stand til at opdage ordnede mønstre:Det
- Ved hjælp af en vulkanudbrudshukommelse til at forudsige farlige opfølgende eksplosioner
- Facebook ansætter højtstående advokat i det amerikanske udenrigsministerium
- Subglacial forvitring ændrer næringscyklusser i Grønland
- To eksperimenter til at hjælpe mennesker med at gå længere/blive længere i rummet
- Ingeniøren er stadig bekymret over forebyggelse af sporing af Safari
- Forskere opdager fedtblokerende effekt af nanofibre