


CruzAffect:en funktionsrig tilgang til at karakterisere lykke
Kredit:CC0 Public Domain
Et team af forskere ved UC Santa Cruz har for nylig udviklet en ny maskinlæringstilgang til at karakterisere lykke, kaldet CruzAffect. Deres tilgang, præsenteret i et papir, der er forudgivet på arXiv, kan anvendes på forskellige modeller for affektiv indholdsklassificering, inklusiv både traditionelle klassifikatorer og deep learning convolutional neurale netværk (CNN).
Denne nylige undersøgelse bygger på tidligere forskning, der undersøgte, hvordan mennesker formidler førstepersonspåvirkning og lykke. I en undersøgelse, de samme forskere fandt ud af, at folk har en tendens til at beskrive situationer, såsom 'min ven købte blomster til mig', eller 'Jeg har fået en parkeringsbøde', hvorfra andre mennesker let kan udlede deres implicitte affektive reaktioner. De konkluderede, at kompositorisk semantik kan give stærke beviser for den følelse, der er forbundet med en given begivenhed.

Kredit:Wu et al.
I en anden undersøgelse, forskerne forsøgte at basere folks sproglige beskrivelser af begivenheder på teorier om trivsel og lykke. Ved at analysere et korpus af private mikroblogs udtrukket fra en applikation kaldet Echo, de undersøgte, i hvilket omfang forskellige teoretiske beretninger kunne forklare variansen i de lykkescore, som Echo-brugere gav til daglige begivenheder i deres liv.
"Det er udfordrende at generalisere en affektiv begivenhed og forbinde den med teorier om velvære, " Jiaqi Wu, en af forskerne, der gennemførte undersøgelsen, fortalte TechXplore. "I vores tidligere forskning, vi bemærkede, at der ikke er en eneste teori, der kan forudsige følelsen af alle affektive begivenheder. Målet med vores seneste arbejde var at identificere specifik kompositorisk semantik, der karakteriserer følelsen af begivenheder og forsøge at modellere lykke på et højere generaliseringsniveau. Imidlertid, Det er stadig en udfordring at finde generiske egenskaber til modellering af velvære."
Det primære formål med den nylige undersøgelse udført af Wu og hendes kolleger var at undersøge effektiviteten af funktionsrige traditionelle maskinlæringsmetoder og deep learning-metoder til affektiv indholdsklassificering. For at opnå dette, de identificerede en række træk, der karakteriserer lykke i affektivt indhold og anvendte dem på en traditionel klassificering, XGBoostet skov, og en CNN.
"Vores projekt, kaldet CruzAffect, omfatter udvikling af to forskellige modeller:en traditionel maskinlæringsmetode (dvs. XGBoosted forest) og en deep learning CNN med GloVe-indlejring, " sagde Wu. "Vi bruger syntaktiske funktioner, følelsesmæssige træk, og profilfunktioner, og deres ydeevne er stabil for forskellige affektive indholdsklassificeringsopgaver."
I det væsentlige, forskerne evaluerede ydeevnen af to forskellige maskinlæringsmodeller til affektiv indholdsklassificering (XGBoosted forest og en CNN), som begge analyserede indhold baseret på de funktioner, som de tidligere havde identificeret. Disse omfatter:
- Syntaktiske egenskaber:del af tale, navneord, verber, adjektiver og adverbier, brug af spørgsmål, spændings- og aspektinformation.
- Følelsesmæssige egenskaber:Sproglig undersøgelse og ordtælling (LIWC) v2007, følelsesleksikon, subjektivitetsleksikon, niveau af faktuelt og følelsesmæssigt sprog.
- Ordindlejring:GloVe 100 dimensions ordvektorer til ordrepræsentation.
- Profilfunktioner:alder, Land, køn, Civilstand, forældreskab, etc.
Disse funktioner gjorde det muligt for forskerne at afdække væsentlige indikatorer for social involvering og kontrol, som forskellige mennesker kan udøve i lykkelige øjeblikke. I deres undersøgelse, de trænede både XGBoosted- og CNN-modellen med overvåget læring på et datasæt på 10, 000 mærkede tekstuddrag. De trænede også modellerne til at generere pseudo-labels for 70, 000 umærkede uddrag ved hjælp af en bootstappet semi-overvåget tilgang, da dette gav dem mulighed for at udvide deres datasæt. Alle disse tekstuddrag blev udtrukket fra HappyDB-databasen.

CNN arkitektur. Kredit:Wu et al.
"De meningsfulde resultater af vores undersøgelse inkluderer de interessante syntaktiske mønstre, der gentager sig over forskellige domæner, " sagde Wu. "Sådanne sproglige mønstre vil sandsynligvis være forbundet med teorier om velvære. Vi finder også, at de funktioner, der inkluderer ekspertviden, såsom LIWC-ordbog kan forbedre ydeevnen af traditionel model såvel som den dybe læringsmodel i de affektive indholdsklassificeringsopgaver."
Forskerne evaluerede XGBoosted-skoven og CNN-modellerne på den binære klassificering af agentur og sociale mærker, samt på multi-klasse forudsigelse af koncept etiketter. Deres evalueringer gav lovende resultater, hvilket tyder på, at de egenskaber, de identificerer, er særligt effektive til at klassificere affektivt indhold. Selvom den CNN-baserede model klarede sig bedre på multi-class klassifikationsopgaver, den traditionelle maskinlæringsmodel opnåede sammenlignelige resultater ved at bruge de funktioner, som de tidligere havde identificeret.
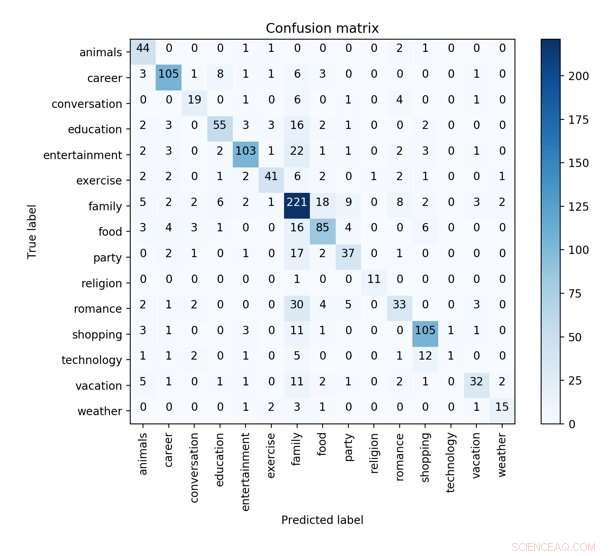
Forvirringsmatricen af den bedste CNN-model med syntaktisk, følelses- og profiltræk i 10-fold krydsvalidering for at forudsige de karakteristiske begreber. Kredit:Wu et al.
Undersøgelsen udført af Wu og hendes kolleger afdækkede generelle temaer, der går igen i folks beskrivelser af lykkelige øjeblikke. I fremtiden, deres resultater kunne danne grundlag for udviklingen af nye modeller for affektive klassifikationsopgaver, giver forskere mulighed for effektivt at forudsige trivsel og lykke ved at analysere indholdet af tekstuddrag.
"Jeg vil nu udforske den affektive begivenhedsanalyse på tværs af domæner, og undersøge en bedre model til at basere de sproglige beskrivelser af begivenheder, som brugerne oplever, i teorier om trivsel og lykke, " sagde Wu. "Efter at have forstået forholdet mellem det affektive indhold og teorier om velvære, vi kan muligvis indsamle generelle affektive begivenheder, der er stærkt relateret til velvære."

Holdet af forskere, der har udført undersøgelsen. Kredit:Wu et al.
© 2019 Science X Network
Sidste artikelForbedring af solcelleeffektiviteten med en spand vand
Næste artikelNBA udvider Kinas partnerskab med Alibaba-platforme
 Varme artikler
Varme artikler
-
 Regeringen ønsker ikke, at Facebook krypterer dine beskeder:Her er hvorforKredit:CC0 Public Domain Det amerikanske justitsministerium ønsker ikke, at Facebook krypterer beskeder på WhatsApp og dets andre beskedtjenester, uden at give retshåndhævelse bagdør adgang til så
Regeringen ønsker ikke, at Facebook krypterer dine beskeder:Her er hvorforKredit:CC0 Public Domain Det amerikanske justitsministerium ønsker ikke, at Facebook krypterer beskeder på WhatsApp og dets andre beskedtjenester, uden at give retshåndhævelse bagdør adgang til så -
 Nyt taktilt display ved hjælp af computerstyret overfladeadhæsionFig. 1. StickyTouch—Området under pegefingeren bliver klistret. Kredit:Osaka University En gruppe forskere ved Osaka University udviklede et nyt todimensionelt (2-D) grafisk taktil display, hvorti
Nyt taktilt display ved hjælp af computerstyret overfladeadhæsionFig. 1. StickyTouch—Området under pegefingeren bliver klistret. Kredit:Osaka University En gruppe forskere ved Osaka University udviklede et nyt todimensionelt (2-D) grafisk taktil display, hvorti -
 Talent til alle formål inden for flyproduktionDen mobile robot behandler halefinnen på et Airbus 320-fly. Kredit:Fraunhofer IFAM I flyfremstilling, meget af fræsningen, boring og montering foregår stadig i hånden. Dette skyldes, at råkomponen
Talent til alle formål inden for flyproduktionDen mobile robot behandler halefinnen på et Airbus 320-fly. Kredit:Fraunhofer IFAM I flyfremstilling, meget af fræsningen, boring og montering foregår stadig i hånden. Dette skyldes, at råkomponen -
 Nyt system tillader ubundet højkvalitets multi-player VRPurdue University-forskere har skabt en ny tilgang til VR, der vil give flere spillere mulighed for at interagere med den samme VR-app på smartphones og give nye muligheder for uddannelse, sundhedsple
Nyt system tillader ubundet højkvalitets multi-player VRPurdue University-forskere har skabt en ny tilgang til VR, der vil give flere spillere mulighed for at interagere med den samme VR-app på smartphones og give nye muligheder for uddannelse, sundhedsple
- Hvordan gør vaskebønner Mark Territory?
- Sådan konverteres centimeter til firkantede fødder
- Bronzealderens sværd bærer præg af dygtige kæmpere
- Seneste lavastrøm ødelægger 4 hjem, gnister evakuering forberedelse
- Kvanteprikker forbedrer lys-til-strøm konvertering i lagdelte halvledere
- Gala åbner nedtællingen til 50 -årsdagen for 1. månelanding