


Automatisering af kunstig intelligens til medicinsk beslutningstagning
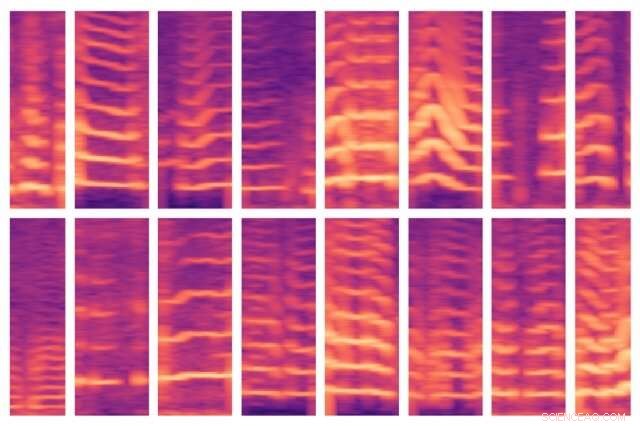
En ny MIT-udviklet model automatiserer et kritisk trin i brug af AI til medicinsk beslutningstagning, hvor eksperter normalt identificerer vigtige funktioner i massive patientdatasæt i hånden. Modellen var i stand til automatisk at identificere stemmemønstre for mennesker med stemmebåndsknuder (vist her) og, på tur, bruge disse funktioner til at forudsige, hvilke mennesker der gør og ikke har lidelsen. Kredit:Massachusetts Institute of Technology
MIT dataloger håber at fremskynde brugen af kunstig intelligens for at forbedre medicinsk beslutningstagning, ved at automatisere et nøgletrin, der normalt udføres i hånden – og det bliver mere besværligt, efterhånden som visse datasæt bliver stadig større.
Området prædiktiv analyse har et stigende løfte om at hjælpe klinikere med at diagnosticere og behandle patienter. Maskinlæringsmodeller kan trænes til at finde mønstre i patientdata for at hjælpe med sepsisbehandling, designe sikrere kemoterapiregimer, og forudsige en patients risiko for at få brystkræft eller dø på ICU, for blot at nævne nogle få eksempler.
Typisk, træningsdatasæt består af mange syge og raske forsøgspersoner, men med relativt få data for hvert emne. Eksperter skal så finde netop de aspekter - eller "funktioner" - i datasættene, der vil være vigtige for at lave forudsigelser.
Denne "feature engineering" kan være en besværlig og dyr proces. Men det bliver endnu mere udfordrende med stigningen i bærbare sensorer, fordi forskere nemmere kan overvåge patienters biometri over lange perioder, sporing af søvnmønstre, gangart, og stemmeaktivitet, for eksempel. Efter kun en uges overvågning, eksperter kunne have flere milliarder dataprøver for hvert emne.
I et papir, der præsenteres på Machine Learning for Healthcare-konferencen i denne uge, MIT-forskere demonstrerer en model, der automatisk lærer funktioner, der forudsiger stemmebåndsforstyrrelser. Funktionerne stammer fra et datasæt på omkring 100 emner, hver med omkring en uges stemmeovervågningsdata og adskillige milliarder prøver – med andre ord, et lille antal emner og en stor mængde data pr. emne. Datasættet indeholder signaler hentet fra en lille accelerometersensor monteret på emnernes hals.
I eksperimenter, modellen brugte funktioner, der automatisk blev ekstraheret fra disse data til at klassificere, med høj nøjagtighed, patienter med og uden stemmebåndsknuder. Disse er læsioner, der udvikler sig i strubehovedet, ofte på grund af stemmemønstre som f.eks. at bælte sange eller råbe. Vigtigt, modellen klarede denne opgave uden et stort sæt håndmærkede data.
"Det bliver mere og mere nemt at indsamle datasæt i lange tidsserier. Men du har læger, der skal bruge deres viden til at mærke datasættet, "siger hovedforfatter Jose Javier Gonzalez Ortiz, en ph.d. studerende i MIT Computer Science and Artificial Intelligence Laboratory (CSAIL). "Vi ønsker at fjerne den manuelle del for eksperterne og overføre al funktionsteknik til en maskinlæringsmodel."
Modellen kan tilpasses til at lære mønstre af enhver sygdom eller tilstand. Men evnen til at opdage de daglige stemmebrugsmønstre forbundet med stemmebåndsknuder er et vigtigt skridt i udviklingen af forbedrede metoder til at forebygge, diagnosticere, og behandle lidelsen, siger forskerne. Det kunne omfatte at designe nye måder at identificere og advare folk om potentielt skadelig vokal adfærd.
Tilslutning til Gonzalez Ortiz på papiret er John Guttag, Dugald C. Jackson professor i datalogi og elektroteknik og leder af CSAIL's Data Driven Inference Group; Robert Hillman, Jarrad Van Stan, og Daryush Mehta, hele Massachusetts General Hospitals Center for Laryngeal Surgery and Voice Rehabilitation; og Marzyeh Ghassemi, en assisterende professor i datalogi og medicin ved University of Toronto.
Tvunget funktionsindlæring
Årevis, MIT -forskerne har arbejdet med Center for strubehovedkirurgi og stemmerehabilitering for at udvikle og analysere data fra en sensor for at spore emnestemmeforbrug i alle vågne timer. Sensoren er et accelerometer med en node, der klæber til halsen og er forbundet til en smartphone. Mens personen taler, smartphonen samler data fra forskydningerne i accelerometeret.
I deres arbejde, forskerne indsamlede en uges værdi af disse data - kaldet "tidsseriedata" - fra 104 forsøgspersoner, halvdelen var diagnosticeret med stemmebåndsknuder. For hver patient, der var også en matchende kontrol, betyder et sundt forsøgsperson af samme alder, køn, beskæftigelse, og andre faktorer.
Traditionelt set eksperter skal manuelt identificere funktioner, der kan være nyttige for en model til at opdage forskellige sygdomme eller tilstande. Det hjælper med at forhindre et almindeligt maskinlæringsproblem i sundhedsvæsenet:overfitting. Det var da, i træning, en model "memoriserer" emnedata i stedet for kun at lære de klinisk relevante funktioner. Ved testning, disse modeller undlader ofte at skelne lignende mønstre i tidligere usete emner.
"I stedet for at lære funktioner, der er klinisk signifikante, en model ser mønstre og siger, "Dette er Sarah, og jeg ved, at Sarah er sund, og dette er Peter, der har en stemmebåndsknude." Så, det er bare at huske emner. Derefter, når den ser data fra Andrew, som har et nyt vokalbrugsmønster, det kan ikke finde ud af, om disse mønstre matcher en klassifikation, " siger Gonzalez Ortiz.
Den største udfordring, derefter, forhindrede overmontering, mens automatisering af manuel funktionsteknik. Til det formål, forskerne tvang modellen til at lære funktioner uden emneinformation. Til deres opgave, det betød at fange alle øjeblikke, hvor personer taler, og intensiteten af deres stemmer.
Mens deres model gennemgår et emnes data, det er programmeret til at lokalisere stemmesegmenter, som kun udgør omkring 10 procent af dataene. For hvert af disse stemmevinduer, modellen beregner et spektrogram, en visuel repræsentation af spektret af frekvenser, der varierer over tid, som ofte bruges til talebehandlingsopgaver. Spektrogrammerne gemmes derefter som store matricer med tusinder af værdier.
Men de matricer er enorme og svære at bearbejde. Så, en autoencoder – et neuralt netværk optimeret til at generere effektive datakodninger fra store mængder data – komprimerer først spektrogrammet til en kodning på 30 værdier. Det dekomprimerer derefter den kodning til et separat spektrogram.
I bund og grund, modellen skal sikre, at det dekomprimerede spektrogram ligner det oprindelige spektrogram input. Derved, det er tvunget til at lære den komprimerede repræsentation af hvert spektrogramsegment-input over hvert emnes hele tidsseriedata. De komprimerede repræsentationer er de funktioner, der hjælper med at træne maskinlæringsmodeller til at komme med forudsigelser.
Kortlægning af normale og unormale træk
I træning, modellen lærer at kortlægge disse funktioner til "patienter" eller "kontroller". Patienter vil have flere stemmemønstre end kontroller. I test på tidligere usete emner, modellen kondenserer på samme måde alle spektrogramsegmenter til et reduceret sæt funktioner. Derefter, det er flertalsregler:Hvis motivet for det meste har unormale stemmesegmenter, de er klassificeret som patienter; hvis de for det meste har normale, de er klassificeret som kontroller.
I eksperimenter, modellen udførte lige så præcist som avancerede modeller, der kræver manuel funktionsteknik. Vigtigt, forskernes model udført præcist i både træning og test, indikerer, at det lærer klinisk relevante mønstre fra dataene, ikke fagspecifik information.
Næste, forskerne ønsker at overvåge, hvordan forskellige behandlinger - såsom kirurgi og vokalterapi - påvirker vokaladfærd. Hvis patienters adfærd ændrer sig fra unormalt til normal over tid, de er højst sandsynligt i bedring. De håber også at kunne bruge en lignende teknik på elektrokardiogramdata, som bruges til at spore hjertets muskelfunktioner.
Denne historie er genudgivet med tilladelse fra MIT News (web.mit.edu/newsoffice/), et populært websted, der dækker nyheder om MIT-forskning, innovation og undervisning.
 Varme artikler
Varme artikler
-
 Facebook ansætter den britiske vicepremierminister som chef for globale anliggenderStorbritanniens tidligere vicepremierminister Nick Clegg flytter til Californien for sin nye rolle som Facebooks chef for globale anliggender Den britiske tidligere vicepremierminister Nick Clegg,
Facebook ansætter den britiske vicepremierminister som chef for globale anliggenderStorbritanniens tidligere vicepremierminister Nick Clegg flytter til Californien for sin nye rolle som Facebooks chef for globale anliggender Den britiske tidligere vicepremierminister Nick Clegg, -
 Sådan vælges en ny adgangskode, nu hvor Twitter vil have enDenne 26. april, 2017, filfoto viser Twitter -ikonet på en mobiltelefon, i Philadelphia. Twitter siger, at det opdagede en fejl, der lagrede adgangskoder i en intern log i en ubeskyttet form. Selvom T
Sådan vælges en ny adgangskode, nu hvor Twitter vil have enDenne 26. april, 2017, filfoto viser Twitter -ikonet på en mobiltelefon, i Philadelphia. Twitter siger, at det opdagede en fejl, der lagrede adgangskoder i en intern log i en ubeskyttet form. Selvom T -
 Konvoj, appen Uber for Trucking, scorer $ 400 millioner i ny finansieringsrundeKredit:CC0 Public Domain Konvoj, det Seattle-baserede selskab, hvis app lover at gøre fragtprocessen mere pålidelig og effektiv, sagde, at det har skaffet 400 millioner dollars i sin seneste finan
Konvoj, appen Uber for Trucking, scorer $ 400 millioner i ny finansieringsrundeKredit:CC0 Public Domain Konvoj, det Seattle-baserede selskab, hvis app lover at gøre fragtprocessen mere pålidelig og effektiv, sagde, at det har skaffet 400 millioner dollars i sin seneste finan -
 Kriseramte Nissan koteletter prognoser, nettooverskuddet værste i et årtiNissan er blevet ramt af svag efterspørgsel i USA, Europa og Japan Den kriseramte japanske bilproducent Nissan har tirsdag sænket sin helårsprognose for både salg og overskud, da den kæmper med sv
Kriseramte Nissan koteletter prognoser, nettooverskuddet værste i et årtiNissan er blevet ramt af svag efterspørgsel i USA, Europa og Japan Den kriseramte japanske bilproducent Nissan har tirsdag sænket sin helårsprognose for både salg og overskud, da den kæmper med sv
- UAE annoncerer de første astronauter til at gå til rummet (Opdatering)
- De fleste virksomheder forsømte at inkludere pandemi i årlige risikovurderinger på trods af advar…
- Mælkevejsgalaksen har en klumpet glorie
- Er valmuefrø dårligt for fugle?
- Klæbemidler og kompositmaterialer fremstillet af schweizisk træbark
- Origami:Ikke kun til papir længere