


Succes ved bedrag

Kredit:Public Domain
Teoretiske fysikere fra ETH Zürich vildlede bevidst intelligente maskiner, og dermed forfinet processen med maskinlæring. De skabte en ny metode, der gør det muligt for computere at kategorisere data - selv når mennesker ikke aner, hvordan denne kategorisering kan se ud.
Når computere uafhængigt identificerer vandområder og deres konturer i satellitbilleder, eller slå verdens bedste professionelle spillere i brætspillet Go, så arbejder adaptive algoritmer i baggrunden. Programmerere forsyner disse algoritmer med kendte eksempler i en træningsfase:billeder af vand- og landområder, eller sekvenser af Go -træk, der har ført til succes eller fiasko i turneringer. På samme måde som hvordan vores hjernens nerveceller producerer nye netværk under læreprocesser, de særlige algoritmer tilpasser sig i læringsfasen baseret på eksemplerne, der præsenteres for dem. Dette fortsætter, indtil de er i stand til at differentiere vandmasser fra land på ukendte fotos, eller vellykkede sekvenser af træk fra mislykkede.
Indtil nu, disse kunstige neurale netværk er blevet brugt i maskinindlæring med et kendt beslutningskriterium:vi ved, hvad en vandmasse er, og hvilke sekvenser af træk, der var vellykkede i Go-turneringer.
Adskillelse af hvede fra agn
Nu, en gruppe forskere, der arbejder under Sebastian Huber, Professor i kondenseret teori og kvanteoptik ved ETH Zürich, har udvidet applikationerne til disse neurale netværk ved at udvikle en metode, der ikke kun tillader kategorisering af data, men anerkender også, om komplekse datasæt overhovedet indeholder kategorier.
Sådanne spørgsmål opstår inden for videnskaben:f.eks. metoden kan være nyttig til analyse af målinger fra partikelacceleratorer eller astronomiske observationer. Fysikere kunne således filtrere de mest lovende målinger ud af deres ofte uoverskuelige mængder måledata. Farmakologer kunne udtrække molekyler med en vis sandsynlighed for at have en bestemt farmaceutisk effekt eller bivirkning fra store molekylære databaser. Og datavidenskabsfolk kunne sortere enorme masser af uordnede datakrydsninger og opnå brugbar information (data mining).
Søg efter en grænse
ETH -forskerne anvendte deres metode til et intensivt undersøgt fænomen af teoretisk fysik:et mangekroppssystem af interagerende magnetiske dipoler, der aldrig når en ligevægtstilstand - selv på lang sigt. Sådanne systemer er blevet beskrevet for nylig, men det vides endnu ikke i detaljer, hvilke kvantefysiske egenskaber, der forhindrer et mangekroppssystem i at komme ind i en ligevægtstilstand. I særdeleshed, det er uklart, hvor præcis grænsen ligger mellem systemer, der når ligevægt, og dem, der ikke gør det.
For at lokalisere denne grænse, forskerne udviklede "handle som om" -princippet:at tage data fra kvantesystemer, de etablerede en vilkårlig grænse baseret på en parameter og brugte den til at opdele dataene i to grupper. De trænede derefter et kunstigt neuralt netværk ved at lade som om, at den ene gruppe nåede en ligevægtstilstand, mens den anden ikke gjorde det. Dermed, forskerne handlede som om de vidste, hvor grænsen var.
Forskere forvirrede systemet
De trænede netværket utallige gange generelt, med en anden grænse hver gang, og testede netværkets evne til at sortere data efter hver session. Resultatet var, at i mange tilfælde, netværket kæmpede for at klassificere dataene som forskerne havde. Men i nogle tilfælde, opdelingen i de to grupper var meget præcis.
Forskerne kunne vise, at denne sorteringsydelse afhænger af grænsens placering. Evert van Nieuwenburg, en doktorand i Hubers gruppe, forklarer dette således:"Ved at vælge at træne med en grænse langt væk fra den egentlige grænse (som jeg ikke kender), Jeg er i stand til at vildlede netværket. I sidste ende træner vi netværket forkert - og forkert uddannede netværk er meget dårlige til at klassificere data. "Dog, hvis der tilfældigt vælges en grænse tæt på den egentlige grænse, der produceres en yderst effektiv algoritme. Ved at bestemme algoritmens ydeevne, forskerne var i stand til at spore grænsen mellem kvantesystemer, der når ligevægt, og dem, der ikke gør det:Grænsen er placeret, hvor netværkets sorteringsydelse er højest.
Forskerne demonstrerede også mulighederne for deres nye metode ved hjælp af to yderligere spørgsmål fra teoretisk fysik:topologiske faseovergange i endimensionelle faste stoffer og Ising-modellen, som beskriver magnetisme inde i faste stoffer.
Kategorisering uden forudgående viden
Den nye metode kan også illustreres i forenklet form med et tankeeksperiment, hvor vi vil klassificere rødt, rødlig, blålige og blå kugler i to grupper. Vi antager, at vi ikke har nogen idé om, hvordan en sådan klassificering med rimelighed kan se ud.
Hvis et neuralt netværk trænes ved at fortælle det, at skillelinjen ligger et sted i den røde region, så vil dette forvirre netværket. "Du prøver at lære netværket, at blå og rødlige kugler er de samme og beder det skelne mellem røde og røde kugler, hvilket den simpelthen ikke kan, "siger Huber.
På den anden side, hvis du placerer grænsen i det violette farvespektrum, netværket lærer en reel forskel og sorterer boldene i røde og blå grupper. Imidlertid, man behøver ikke på forhånd at vide, at skillelinjen skal være i det violette område. Ved at sammenligne sorteringsydelsen ved en række valgte grænser, denne grænse kan findes uden forudgående viden.
Sidste artikelNæste generations mørke stofdetektor i et kapløb om målstregen
Næste artikelVil androider drømme om kvantefår?
 Varme artikler
Varme artikler
-
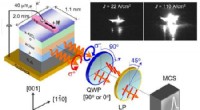 Overraskende spinadfærd ved stuetemperaturde højre og venstrehåndede EL-komponenter er angivet med de røde og blå cirkler, henholdsvis. QWP, LP, og MCS repræsenterer en kvartbølgeplade, en lineær polarisator, og et multikanalspektrometer, hen
Overraskende spinadfærd ved stuetemperaturde højre og venstrehåndede EL-komponenter er angivet med de røde og blå cirkler, henholdsvis. QWP, LP, og MCS repræsenterer en kvartbølgeplade, en lineær polarisator, og et multikanalspektrometer, hen -
 Ny indsigt i kvantemålingerKredit:CC0 Public Domain Forskere fra University of Bristol har kastet nyt lys over processen med kvantemåling, en af de definerende, og de fleste kvantetræk ved kvantemekanikken. Som rapporter
Ny indsigt i kvantemålingerKredit:CC0 Public Domain Forskere fra University of Bristol har kastet nyt lys over processen med kvantemåling, en af de definerende, og de fleste kvantetræk ved kvantemekanikken. Som rapporter -
 Sådan laver du et elektroskop til et videnskabsprojektAt lave et elektroskop til et videnskabsprojekt er ikke kun spændende, men nemt. Et elektroskop er et videnskabeligt måleinstrument, som detekterer tilstedeværelsen af en elektrisk ladning. Når et e
Sådan laver du et elektroskop til et videnskabsprojektAt lave et elektroskop til et videnskabsprojekt er ikke kun spændende, men nemt. Et elektroskop er et videnskabeligt måleinstrument, som detekterer tilstedeværelsen af en elektrisk ladning. Når et e -
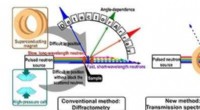 Verdens første observation af spin -arrangementer ved hjælp af neutronoverførselSammenligning af en konventionel metode, hvor en række detektorer bruges til at måle diffrakterede neutroner i forskellige vinkler (venstre) og den nyudviklede metode, hvor den tid, det tager for neut
Verdens første observation af spin -arrangementer ved hjælp af neutronoverførselSammenligning af en konventionel metode, hvor en række detektorer bruges til at måle diffrakterede neutroner i forskellige vinkler (venstre) og den nyudviklede metode, hvor den tid, det tager for neut
- Forskning finder, at aboriginals boede i den vestlige ørken 50, 000 år siden
- Glacialteknik kan begrænse havniveaustigningen, hvis vi får vores emissioner under kontrol
- Chicago synker. Her er, hvad det betyder for Lake Michigan og Midtvesten
- Nyt solinduceret klorofylfluorescensprodukt har til formål at forbedre forskningen i CO2-neutralite…
- Spanien ser ud til at indføre digital skat, som har gjort USA vred
- Udvider palasmen til plasmoniske malere