


Neurale netværk muliggør læring af fejlkorrigeringsstrategier for kvantecomputere
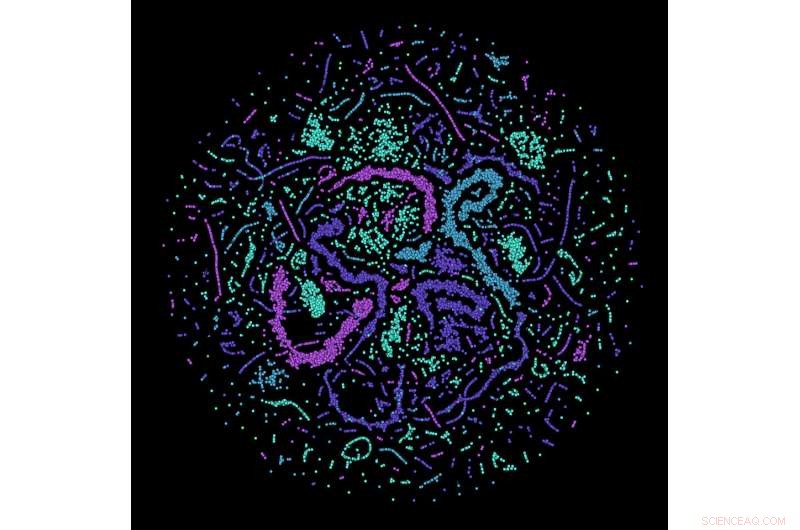
Læring af kvantefejlkorrektion:billedet visualiserer aktiviteten af kunstige neuroner i Erlangen -forskernes neurale netværk, mens det løser sin opgave. Kredit:Max Planck Institute for the Science of Light
Kvantecomputere kunne løse komplekse opgaver, der ligger ud over konventionelle computers muligheder. Imidlertid, kvantetilstandene er ekstremt følsomme over for konstant interferens fra deres omgivelser. Planen er at bekæmpe dette ved hjælp af aktiv beskyttelse baseret på kvantefejlkorrektion. Florian Marquardt, Direktør ved Max Planck Institute for the Science of Light, og hans team har nu præsenteret et kvantefejlkorrektionssystem, der er i stand til at lære takket være kunstig intelligens.
I 2016, computerprogrammet AlphaGo vandt fire ud af fem Go -kampe mod verdens bedste menneskelige spiller. I betragtning af at et spil Go har flere kombinationer af træk, end der skønnes at være atomer i universet, dette krævede mere end bare ren behandlingskraft. Hellere, AlphaGo brugte kunstige neurale netværk, som kan genkende visuelle mønstre og endda er i stand til at lære. I modsætning til et menneske, programmet var i stand til at øve hundredtusindvis af spil på kort tid, til sidst overgår den bedste menneskelige spiller. Nu, de Erlangen-baserede forskere bruger neurale netværk af denne art til at udvikle fejlkorrigerende læring til en kvantecomputer.
Kunstige neurale netværk er computerprogrammer, der efterligner adfærden hos sammenkoblede nerveceller (neuroner) - i tilfælde af forskningen i Erlangen, omkring to tusinde kunstige neuroner er forbundet med hinanden. "Vi tager de nyeste ideer fra datalogi og anvender dem på fysiske systemer, "forklarer Florian Marquardt." Ved at gøre det, vi tjener på hurtige fremskridt inden for kunstig intelligens. "
Kunstige neurale netværk kunne overgå andre strategier for fejlkorrektion
Det første anvendelsesområde er kvantecomputere, som det fremgår af det seneste papir, som inkluderer et betydeligt bidrag fra Thomas Fösel, en doktorand ved Max Planck Institute i Erlangen. I avisen, teamet demonstrerer, at kunstige neurale netværk med en AlphaGo-inspireret arkitektur er i stand til-selv at lære-hvordan de udfører en opgave, der vil være afgørende for driften af fremtidige kvantecomputere:kvantefejlkorrektion. Der er endda udsigt til, at med tilstrækkelig uddannelse, denne tilgang vil overgå andre strategier for fejlkorrektion.
For at forstå, hvad det indebærer, du skal se på, hvordan kvantecomputere fungerer. Grundlaget for kvanteinformation er kvantebitten, eller qubit. I modsætning til konventionelle digitale bits, en qubit kan ikke kun vedtage de to tilstande nul og en, men også superpositioner af begge stater. I en kvantecomputers processor, der er endda flere qubits overlejret som en del af en fælles tilstand. Denne sammenfiltring forklarer kvantecomputers enorme processorkraft, når det kommer til at løse visse komplekse opgaver, hvor konventionelle computere er dømt til at mislykkes. Bagsiden er, at kvanteinformation er meget følsom over for støj fra omgivelserne. Denne og andre særegenheder i kvanteverdenen betyder, at kvanteinformation skal regelmæssigt repareres - det vil sige, korrektion af kvantefejl. Imidlertid, de operationer, som dette kræver, er ikke kun komplekse, men skal også efterlade selve kvanteinformationen intakt.
Kvantfejlkorrektion er som et spil Go med mærkelige regler
"Du kan forestille dig, at elementerne i en kvantecomputer er ligesom et Go -bord, "siger Marquardt, komme til kerneidéen bag sit projekt. Qubitsne er fordelt over brættet som stykker. Imidlertid, der er visse vigtige forskelle fra et konventionelt spil Go:alle brikkerne er allerede fordelt rundt på brættet, og hver af dem er hvid på den ene side og sort på den anden. En farve svarer til tilstanden nul, den anden til den ene, og et træk i et spil Quantum Go indebærer at vende brikker. Ifølge kvanteverdenens regler, stykkerne kan også vedtage grå blandede farver, som repræsenterer superposition og sammenfiltring af kvantetilstande.
Når det kommer til at spille spillet, en spiller - vi kalder hende Alice - foretager træk, der har til formål at bevare et mønster, der repræsenterer en bestemt kvantetilstand. Disse er kvantefejlkorrektionsoperationer. I mellemtiden, hendes modstander gør alt, hvad de kan for at ødelægge mønsteret. Dette repræsenterer den konstante støj fra den overflod af interferens, som ægte qubits oplever fra deres miljø. Ud over, et spil Quantum Go gøres særlig vanskeligt af en ejendommelig kvanteregel:Alice må ikke se på brættet under spillet. Ethvert glimt, der afslører qubit -stykkernes tilstand for hende, ødelægger den følsomme kvantetilstand, som spillet i øjeblikket indtager. Spørgsmålet er:hvordan kan hun lave de rigtige skridt på trods af dette?
Auxiliary qubits afslører defekter i kvantecomputeren
I kvantecomputere, dette problem løses ved at placere yderligere qubits mellem de qubits, der gemmer den faktiske kvanteinformation. Lejlighedsvise målinger kan foretages for at overvåge tilstanden af disse hjælpe -qubits, gør det muligt for kvantecomputerens controller at identificere, hvor fejl ligger og udføre korrektion på de informationsbærende qubits i disse områder. I vores spil Quantum Go, hjælpekvitterne ville blive repræsenteret af yderligere brikker fordelt mellem de faktiske spilstykker. Alice får lov til at se lejlighedsvis, men kun ved disse hjælpestykker.
I Erlangen -forskernes arbejde, Alices rolle udføres af kunstige neurale netværk. Tanken er, at gennem træning, netværkene bliver så gode til denne rolle, at de endda kan overgå korrektionsstrategier, der er udtænkt af intelligente menneskelige sind. Imidlertid, da teamet studerede et eksempel på fem simulerede qubits, et tal, der stadig kan håndteres for konventionelle computere, de var i stand til at vise, at et kunstigt neuralt netværk alene ikke er nok. Da netværket kun kan indsamle små mængder information om kvantebiternes tilstand, eller rettere spillet Quantum Go, det kommer aldrig ud over stadiet med tilfældige forsøg og fejl. Ultimativt, disse forsøg ødelægger kvantetilstanden i stedet for at gendanne den.
Et neuralt netværk bruger sin forudgående viden til at træne et andet
Løsningen kommer i form af et ekstra neuralt netværk, der fungerer som lærer til det første netværk. Med sin forudgående viden om kvantecomputeren, der skal styres, dette lærernetværk er i stand til at træne det andet netværk - dets elev - og dermed guide dets forsøg på succesfuld kvantekorrektion. Først, imidlertid, lærernetværket selv skal lære nok om kvantecomputeren eller den komponent i den, der skal kontrolleres.
I princippet, kunstige neurale netværk trænes ved hjælp af et belønningssystem, ligesom deres naturlige modeller. Den faktiske belønning ydes for succesfuld gendannelse af den oprindelige kvantetilstand ved kvantefejlkorrektion. "Imidlertid, hvis kun opnåelsen af dette langsigtede mål gav en belønning, det ville komme på et for sent tidspunkt i de mange korrekturforsøg, "Forklarer Marquardt. De Erlangen-baserede forskere har derfor udviklet et belønningssystem, der, selv på uddannelsesstadiet, tilskynder lærerens neurale netværk til at vedtage en lovende strategi. I spillet Quantum Go, dette belønningssystem ville give Alice en indikation af spillets generelle tilstand på et givet tidspunkt uden at give detaljerne væk.
Elevnetværket kan overgå sin lærer gennem sine egne handlinger
"Vores første mål var, at lærernetværket lærte at udføre succesfulde kvantefejlkorrektionsoperationer uden yderligere menneskelig bistand, "siger Marquardt. I modsætning til skoleelevnetværket, lærernetværket kan gøre dette baseret ikke kun på måleresultater, men også på computerens overordnede kvantetilstand. Elevnetværket, der er uddannet af lærernetværket, vil så først være lige godt, men kan blive endnu bedre gennem sine egne handlinger.
Ud over fejlkorrektion i kvantecomputere, Florian Marquardt forestiller sig andre applikationer til kunstig intelligens. Efter hans mening, fysik tilbyder mange systemer, der kan drage fordel af brugen af mønstergenkendelse af kunstige neurale netværk.
 Varme artikler
Varme artikler
-
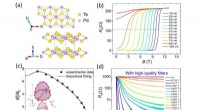 En usædvanlig superleder(a) Gitterstrukturen af PdTe 2 , indikerer, at det er et centrosymmetrisk system. (b) Den magnetiske feltafhængige plademodstand i planet ved forskellige temperaturer for 6-ML PdTe 2 film. (c) T
En usædvanlig superleder(a) Gitterstrukturen af PdTe 2 , indikerer, at det er et centrosymmetrisk system. (b) Den magnetiske feltafhængige plademodstand i planet ved forskellige temperaturer for 6-ML PdTe 2 film. (c) T -
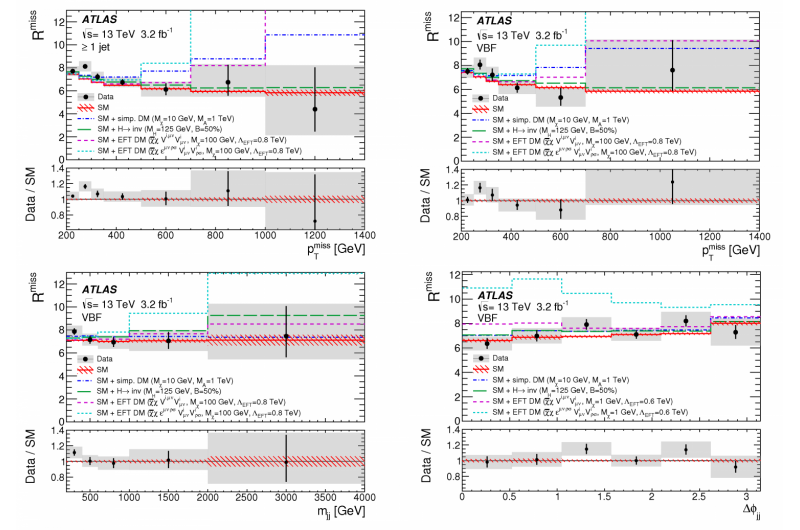 Søger efter usynlige partikler med ATLAS -eksperimentetFigur 1:Målte data sammenlignet med forudsigelsen fra standardmodellen (rød rød linje), og fra standardmodellen plus en række nye usynlige fænomener nær grænsen for ATLAS -følsomhed (stiplede/stiplede
Søger efter usynlige partikler med ATLAS -eksperimentetFigur 1:Målte data sammenlignet med forudsigelsen fra standardmodellen (rød rød linje), og fra standardmodellen plus en række nye usynlige fænomener nær grænsen for ATLAS -følsomhed (stiplede/stiplede -
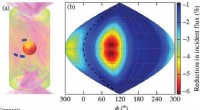 Inertial indeslutning fusion implosioner har betydelige 3-D asymmetrierFigur a:Model af kapslen i et laserbestrålet hohlraum fra synsvinkel (65°, 120 °). Typisk størrelse og placering af diagnostiske vinduer er vist i blåt. Figur (b):Beregnet reduktion af strålingsflux p
Inertial indeslutning fusion implosioner har betydelige 3-D asymmetrierFigur a:Model af kapslen i et laserbestrålet hohlraum fra synsvinkel (65°, 120 °). Typisk størrelse og placering af diagnostiske vinduer er vist i blåt. Figur (b):Beregnet reduktion af strålingsflux p -
 Bedre end mælk på morgenmadsprodukter:Ny præcisionsbelægningsmetode til industrielt granulatAntændt plasma - søstjerneformede racerbaner Afsætning af en tyndfilmskatalysator med en forudsagt tykkelse på overfladen af nye hydrogenlagermikroperler hjælper med at frigive hydrogen. Som en
Bedre end mælk på morgenmadsprodukter:Ny præcisionsbelægningsmetode til industrielt granulatAntændt plasma - søstjerneformede racerbaner Afsætning af en tyndfilmskatalysator med en forudsagt tykkelse på overfladen af nye hydrogenlagermikroperler hjælper med at frigive hydrogen. Som en
- Sådan finder du Relative Humidity
- Strategisk formulering af almindelig cement kan have stor indflydelse på vandrensning
- Hvordan dopamin hjælper med at få nogle madvarer Addicting
- Hvad er forskellene mellem Litmus Paper & pH Strips?
- Forskere udvikler billig chip til at detektere tilstedeværelse og mængde af COVID-19 antistoffer
- Optisk databehandling drager fordel af ny form for mobilitet