


Tekster som netværk:Hvor mange ord er tilstrækkeligt til at identificere en forfatter?

Forfatteren til en usigneret tekst kan identificeres ved at analysere forholdet mellem blot nogle få ord i teksten, som vist af fysiker-statistikere fra Institute of Nuclear Physics ved det polske videnskabsakademi i Krakow. (Kilde:IFJ PAN) Kredit:IFJ PAN
Folk er mere originale, end de tror - dette foreslås af en litterær tekstanalysemetode til stylometri foreslået af videnskabsmænd fra Institute of Nuclear Physics Polish Academy of Sciences. Forfatterens individualitet kan ses i sammenhænge mellem ikke mere end et dusin ord i en engelsk tekst. Det viser sig, at på slaviske sprog, forfatterskabsidentifikation kræver endnu færre ord, og er mere sikker.
Forskerne søgte en løsning på problemet med at verificere forfatterskabet til historiske tekster, der kun kendes fra fragmenter, identifikation af plagiat, og lignende problemer. I mange tilfælde, traditionelle stilometriske metoder fejler eller fører ikke til tilstrækkeligt pålidelige konklusioner. I Informationsvidenskab , forskere fra Institute of Nuclear Physics ved det polske videnskabsakademi (IFJ PAN) i Krakow præsenterer nu deres eget statistiske værktøj til stilometrisk analyse. Konstrueret ved hjælp af grafer, den analyserer teksternes struktur på en kvalitativt ny måde.
"Konklusionerne af vores forskning er, på den ene side, opmuntrende. De indikerer, at enhver persons individualitet viser sig tydeligt i den måde, de bruger et overraskende lille antal ord på. Men der er også en mørk side. Da det viser sig, at folk er så originale, det bliver nemmere at identificere personer ved deres udsagn, " siger professor Stanislaw Drozdz fra Cracow University of Technology.
Stylometri, videnskaben, der beskæftiger sig med de statistiske karakteristika af tekststilen, er baseret på den observation, at hver person bruger det samme sprog på lidt forskellige måder. Nogle har et bredere ordforråd, andre smallere, nogle foretrækker bestemte sætninger og laver fejl, andre undgår gentagelser og er sproglige purister. Og i skrevet tekst, de adskiller sig også i den måde, de bruger tegnsætning på. I den typiske stilometriske tilgang, de grundlæggende træk ved en tekst undersøges normalt, herunder hyppigheden af forekomsten af individuelle ord, mens tegnsætning ignoreres. Der udføres analyser for den undersøgte tekst og for tekster skrevet af potentielt kendte forfattere. Skaberen anses for at være den person, hvis værker har parametre med de værdier, der er tættest på dem, der opnås for det materiale, der identificeres.
"Vi foreslog, at de karakteristiske træk ved stilen kunne repræsenteres i en netværksrepræsentation af teksten, ved hjælp af grafer, " forklarer Tomasz Stanisz, Ph.D. studerende ved IFJ PAN og udgivelsens første forfatter. "Graffen er en samling af punkter eller knudepunkter på grafen, forbundet med linjer, dvs. grafens kanter. I det enkleste tilfælde - i det såkaldte uvægtede netværk - svarer hjørnerne til individuelle ord og er forbundet med kanter, hvis og kun hvis to givne ord har forekommet ved siden af hinanden mindst én gang i teksten. For eksempel, for sætningen 'Jane er sulten, ' grafen ville have tre spidser, en for hvert ord, men der ville kun være to kanter, en mellem 'Jane' og 'er, ' den anden mellem 'er' og 'sulten'."
Mens de konstruerede deres stilometriske værktøjer, forskerne testede forskellige typer grafer. De bedste resultater blev opnået for vægtede grafer, det er, dem, hvor hver kant bærer information om antallet af forekomster af dens tilsvarende forbindelse mellem ord. To parametre viste sig at være de mest nyttige i sådanne netværk:nodegraden og klyngekoefficienten. Den første beskriver antallet af kanter, der kommer fra en given node og er direkte relateret til antallet af forekomster af et givet ord i teksten. På tur, klyngekoefficienten beskriver sandsynligheden for, at to ord forbundet med en kant med et givet ord også er forbundet med en kant imellem sig.
Ved hjælp af statistiske værktøjer udarbejdet på denne måde, de Krakow-baserede fysikere så på 96 bøger:seks romaner af otte kendte engelske forfattere (Austen, Conrad, Defoe, Dickens, Doyle, Eliot, Orwell og Twain) og otte polske forfattere (Korczak, Kraszewski, Lam, Orzeszkowa, Prus, Reymont, Sienkiewicz og Zeromski). Forfatterne omfattede to vindere af Nobelprisen i litteratur (Wladyslaw Reymont og Henryk Sienkiewicz). Alle teksterne blev hentet fra internetressourcer:Project Gutenberg, Wikisource og Wolne Lektury. Gruppen fra IFJ PAN kontrollerede derefter pålideligheden, hvormed forfatterskabet af 12 tilfældigt udvalgte værker på ét sprog kunne bestemmes, at behandle resten af puljen af værker som sammenlignende materiale.
"I tilfælde af engelske tekster, vi identificerede forfatterne korrekt i næsten 90 procent af tilfældene. Ud over, for at opnå succes, det var nødvendigt at spore forbindelserne mellem kun 10 til 12 ord i den undersøgte tekst. I modsætning til naiv intuition, en yderligere stigning i antallet af undersøgte ord øgede ikke metodens effektivitet væsentligt, " siger Stanisz.
på polsk, bestemmelsen af forfatterskab viste sig at være endnu enklere:Det var kun nødvendigt at analysere fem til seks ord. Især på trods af at puljen af betydningsfulde ord var halvt så mange som på engelsk, sandsynligheden for korrekt identifikation blev øget med op til 95 procent. Sådan høj diagnostisk nøjagtighed, imidlertid, blev kun opnået, når tegnsætningstegn også blev behandlet som separate ord. På begge sprog, udeladelse af tegnsætning resulterede i en betydelig reduktion i antallet af korrekte gæt. Den observerede rolle af tegnsætning er en anden bekræftelse af konklusionerne fra en 2017-publikation af gruppen af prof. Drozdz, hvor det blev vist, at tegnsætning spiller en lige så vigtig rolle i sproget som ordene selv.
"I sammenligning med engelsk, Polsk synes at give større muligheder for at afsløre forfatterens stil. Vi mener, at de andre slaviske sprog er karakteriseret ved lignende træk. Engelsk er et positionssprog, hvilket betyder, at rækkefølgen af ordene i en sætning er vigtig. Denne form for sprog giver mindre plads til en individuel udtryksstil end de slaviske sprog, i hvilken bøjning, eller variation, bestemmer rollen for et ord eller en sætning i en sætning. Dette giver større frihed til at organisere rækkefølgen af ord i en sætning, mens dens betydning forbliver uændret, " siger prof. Drozdz.
 Varme artikler
Varme artikler
-
 Brug af kvantemekanikkens uforudsigelige natur til at generere virkelig tilfældige talKredit:CC0 Public Domain Et team af forskere fra Storbritannien, Tyskland og Rusland har brugt kvantemekanikkens uforudsigelige natur til at skabe en enhed, der er i stand til at generere virkelig
Brug af kvantemekanikkens uforudsigelige natur til at generere virkelig tilfældige talKredit:CC0 Public Domain Et team af forskere fra Storbritannien, Tyskland og Rusland har brugt kvantemekanikkens uforudsigelige natur til at skabe en enhed, der er i stand til at generere virkelig -
 Valgfri kølevæske i morgenBringes ind i et magnetfelt, temperaturen af visse materialer ændrer sig betydeligt. Forskere ønsker at bruge denne effekt til at bygge miljøvenlige køleanordninger. Kredit:HZDR/Juniks Senere i
Valgfri kølevæske i morgenBringes ind i et magnetfelt, temperaturen af visse materialer ændrer sig betydeligt. Forskere ønsker at bruge denne effekt til at bygge miljøvenlige køleanordninger. Kredit:HZDR/Juniks Senere i -
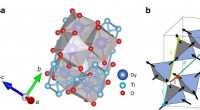 Forskere benytter AI for at sætte et nyt spin på neutronforsøg(a) Atoms struktur af Dy 2 Ti 2 O 7 består af tetraeder af magnetiske dysprosiumioner (blå) og ikke -magnetiske oktaeder af iltioner (røde) omkring titaniumioner (cyan). (b) De magnetiske moment
Forskere benytter AI for at sætte et nyt spin på neutronforsøg(a) Atoms struktur af Dy 2 Ti 2 O 7 består af tetraeder af magnetiske dysprosiumioner (blå) og ikke -magnetiske oktaeder af iltioner (røde) omkring titaniumioner (cyan). (b) De magnetiske moment -
 Forskere søger eksistens af eksotisk kvante -spin -isUndersøgelse af realiseringen af kvantespindis, forskerne Romain Sibille (til venstre) og Nicolas Gauthier er de første brugere til at bruge HYPSPECs opgraderede supermirror -array bygget af deres k
Forskere søger eksistens af eksotisk kvante -spin -isUndersøgelse af realiseringen af kvantespindis, forskerne Romain Sibille (til venstre) og Nicolas Gauthier er de første brugere til at bruge HYPSPECs opgraderede supermirror -array bygget af deres k
- Simuleringer løser revnerne i magnetiske spejle
- Hvorfor lejlighedsboere har brug for indendørs planter
- Næsten halvdelen af amerikanske teenagere, der dater, oplever stalking og chikane
- ESA'er næste satellit drevet af butan
- Hvor fordeles vand under en tørke?
- Foxconn vælger hovedentreprenør, rådgivende Ingeniører