


Chipdesign reducerer dramatisk den energi, der er nødvendig for at beregne med lys
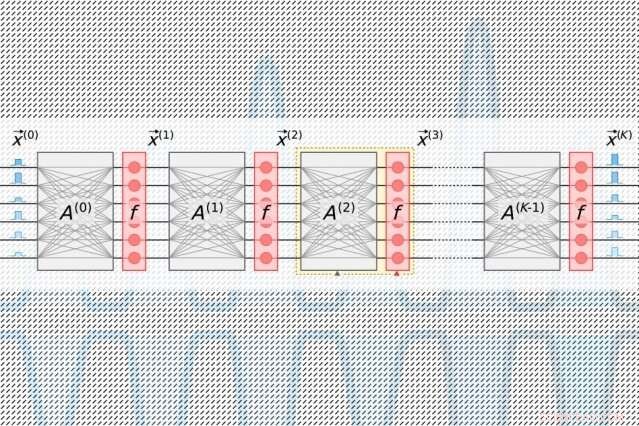
Et nyt fotonisk chipdesign reducerer drastisk energi, der er nødvendig for at beregne med lys, med simuleringer, der tyder på, at det kunne køre optiske neurale netværk 10 millioner gange mere effektivt end dets elektriske modstykker. Kredit:MIT News
MIT-forskere har udviklet en ny "fotonisk" chip, der bruger lys i stedet for elektricitet - og bruger relativt lidt strøm i processen. Chippen kan bruges til at behandle massive neurale netværk millioner af gange mere effektivt end nutidens klassiske computere gør.
Neurale netværk er maskinlæringsmodeller, der er meget brugt til opgaver som robotobjektidentifikation, naturlig sprogbehandling, udvikling af lægemidler, medicinsk billeddannelse, og driver førerløse biler. Nye optiske neurale netværk, som bruger optiske fænomener til at fremskynde beregningen, kan køre meget hurtigere og mere effektivt end deres elektriske modstykker.
Men efterhånden som traditionelle og optiske neurale netværk bliver mere komplekse, de spiser tonsvis af strøm. For at løse det problem, forskere og store teknologivirksomheder – inklusive Google, IBM, og Tesla – har udviklet "AI-acceleratorer, " specialiserede chips, der forbedrer hastigheden og effektiviteten af træning og test af neurale netværk.
For elektriske chips, inklusive de fleste AI-acceleratorer, der er en teoretisk minimumsgrænse for energiforbrug. For nylig, MIT-forskere er begyndt at udvikle fotoniske acceleratorer til optiske neurale netværk. Disse chips udfører størrelsesordener mere effektivt, men de er afhængige af nogle omfangsrige optiske komponenter, der begrænser deres brug til relativt små neurale netværk.
I et blad udgivet i Fysisk gennemgang X , MIT forskere beskriver en ny fotonisk accelerator, der bruger mere kompakte optiske komponenter og optiske signalbehandlingsteknikker, at reducere både strømforbrug og chipareal drastisk. Det gør det muligt for chippen at skalere til neurale netværk adskillige størrelsesordener større end dens modstykker.
Simuleret træning af neurale netværk på MNIST billedklassificeringsdatasættet antyder, at acceleratoren teoretisk kan behandle neurale netværk mere end 10 millioner gange under energiforbrugsgrænsen for traditionelle elektrisk-baserede acceleratorer og ca. 000 gange under grænsen for fotoniske acceleratorer. Forskerne arbejder nu på en prototype-chip for eksperimentelt at bevise resultaterne.
"Folk leder efter teknologi, der kan beregne ud over de grundlæggende grænser for energiforbrug, " siger Ryan Hamerly, en postdoc i Forskningslaboratoriet for Elektronik. "Fotoniske acceleratorer er lovende ... men vores motivation er at bygge en [fotonisk accelerator], der kan skalere op til store neurale netværk."
Praktiske anvendelser for sådanne teknologier omfatter reduktion af energiforbruget i datacentre. "Der er en stigende efterspørgsel efter datacentre til drift af store neurale netværk, og det bliver mere og mere beregningsmæssigt uoverskueligt, efterhånden som efterspørgslen vokser, " siger medforfatter Alexander Sludds, en kandidatstuderende i Forskningslaboratoriet for Elektronik. Målet er "at imødekomme beregningsmæssig efterspørgsel med neuralt netværkshardware ... for at løse flaskehalsen med energiforbrug og latens."
Sammen med Sludds og Hamerly på papiret er:medforfatter Liane Bernstein, en RLE kandidatstuderende; Marin Soljacic, en MIT-professor i fysik; og Dirk Englund, en MIT lektor i elektroteknik og datalogi, en forsker i RLE, og leder af Quantum Photonics Laboratory.
Kompakt design
Neurale netværk behandler data gennem mange beregningslag, der indeholder indbyrdes forbundne noder, kaldet "neuroner, " for at finde mønstre i dataene. Neuroner modtager input fra deres opstrøms naboer og beregner et udgangssignal, der sendes til neuroner længere nedstrøms. Hvert input er også tildelt en "vægt, " en værdi baseret på dens relative betydning for alle andre input. Når dataene forplanter sig "dybere" gennem lag, netværket lærer gradvist mere kompleks information. Til sidst, et outputlag genererer en forudsigelse baseret på beregningerne gennem alle lagene.
Alle AI-acceleratorer sigter mod at reducere den nødvendige energi til at behandle og flytte rundt på data under et specifikt lineært algebra-trin i neurale netværk, kaldet "matrix multiplikation". der, neuroner og vægte kodes ind i separate tabeller med rækker og kolonner og kombineres derefter for at beregne output.
I traditionelle fotoniske acceleratorer, pulserende lasere kodet med information om hver neuron i et lag strømmer ind i bølgeledere og gennem stråledelere. De resulterende optiske signaler føres ind i et gitter af firkantede optiske komponenter, kaldet "Mach-Zehnder interferometre, " som er programmeret til at udføre matrixmultiplikation. Interferometrene, som er kodet med information om hver vægt, bruge signalinterferensteknikker, der behandler de optiske signaler og vægtværdier for at beregne et output for hver neuron. Men der er et skaleringsproblem:For hver neuron skal der være en bølgeleder og, for hver vægt, der skal være et interferometer. Fordi antallet af vægte er i kvadrat med antallet af neuroner, disse interferometre fylder meget i fast ejendom.
"Du indser hurtigt, at antallet af inputneuroner aldrig kan være større end 100 eller deromkring, fordi du ikke kan passe så mange komponenter på chippen, " siger Hamerly. "Hvis din fotoniske accelerator ikke kan behandle mere end 100 neuroner pr. lag, så gør det det vanskeligt at implementere store neurale netværk i den arkitektur."
Forskernes chip er afhængig af en mere kompakt, energieffektiv "optoelektronisk" ordning, der koder data med optiske signaler, men bruger "balanceret homodyne detektion" til matrix multiplikation. Det er en teknik, der producerer et målbart elektrisk signal efter at have beregnet produktet af amplituderne (bølgehøjderne) af to optiske signaler.
Lysimpulser kodet med information om input- og outputneuronerne for hvert neurale netværkslag - som er nødvendige for at træne netværket - strømmer gennem en enkelt kanal. Separate impulser kodet med information om hele rækker af vægte i matrix multiplikationstabellen strømmer gennem separate kanaler. Optiske signaler, der bærer neuron- og vægtdataene, blæser ud til gitteret af homodyne fotodetektorer. Fotodetektorerne bruger amplituden af signalerne til at beregne en outputværdi for hver neuron. Hver detektor føder et elektrisk udgangssignal for hver neuron ind i en modulator, som omdanner signalet tilbage til en lysimpuls. Det optiske signal bliver input til det næste lag, og så videre.
Designet kræver kun én kanal pr. input og output neuron, og kun så mange homodyne fotodetektorer, som der er neuroner, ikke vægte. Fordi der altid er langt færre neuroner end vægte, dette sparer betydelig plads, så chippen er i stand til at skalere til neurale netværk med mere end en million neuroner pr. lag.
At finde det søde sted
Med fotoniske acceleratorer, der er en uundgåelig støj i signalet. Jo mere lys der føres ind i chippen, jo mindre støj og større nøjagtighed - men det bliver temmelig ineffektivt. Mindre inputlys øger effektiviteten, men påvirker det neurale netværks ydeevne negativt. Men der er et "sweet spot, Bernstein siger, der bruger minimal optisk effekt, samtidig med at nøjagtigheden bevares.
Det søde punkt for AI-acceleratorer måles i, hvor mange joule det tager at udføre en enkelt operation med at gange to tal - såsom under matrixmultiplikation. Lige nu, traditionelle acceleratorer måles i picojoule, eller en trilliontedel af en joule. Fotoniske acceleratorer måler i attojoule, hvilket er en million gange mere effektivt.
I deres simuleringer, forskerne fandt ud af, at deres fotoniske accelerator kunne fungere med sub-attojoule effektivitet. "Der er et minimum af optisk strøm, du kan sende ind, før du mister nøjagtigheden. Den grundlæggende grænse for vores chip er meget lavere end traditionelle acceleratorer ... og lavere end andre fotoniske acceleratorer, " siger Bernstein.
Denne historie er genudgivet med tilladelse fra MIT News (web.mit.edu/newsoffice/), et populært websted, der dækker nyheder om MIT-forskning, innovation og undervisning.
 Varme artikler
Varme artikler
-
 Disorder inducerer topologisk Anderson -isolatorKunstnerens skildring af en lidelsesinduceret overgang til den topologiske Anderson-isolatorfase. En flod, der flyder langs en lige sti, ændres af uorden i det underliggende landskab. Efter at have ge
Disorder inducerer topologisk Anderson -isolatorKunstnerens skildring af en lidelsesinduceret overgang til den topologiske Anderson-isolatorfase. En flod, der flyder langs en lige sti, ændres af uorden i det underliggende landskab. Efter at have ge -
 Forskere udvikler en hurtig, automatiseres, chip-baseret platform til at analysere levende cellerEt diagram af on-chip fluorescens-billeddannelsesplatformen, der viser, hvordan den ultra-tynde glasbund mikrofluidisk chip sidder på toppen af kontakt CMOS fluorescens imager. Kredit:Takehara et al
Forskere udvikler en hurtig, automatiseres, chip-baseret platform til at analysere levende cellerEt diagram af on-chip fluorescens-billeddannelsesplatformen, der viser, hvordan den ultra-tynde glasbund mikrofluidisk chip sidder på toppen af kontakt CMOS fluorescens imager. Kredit:Takehara et al -
 Science Fair Ideer, der involverer SportsVidenskabelige fair-projekter, der involverer sport, byder på mange muligheder. Ligesom ethvert videnskabsprojekt vil du først bestemme din hypotese og derefter indsamle, analysere data og opsummere d
Science Fair Ideer, der involverer SportsVidenskabelige fair-projekter, der involverer sport, byder på mange muligheder. Ligesom ethvert videnskabsprojekt vil du først bestemme din hypotese og derefter indsamle, analysere data og opsummere d -
 For første gang, forskere måler kræfter, der justerer krystaller og hjælper dem med at snappe sa…Lille bitte, slebne stykker af et titanoxidmineral kaldet rutil - øverst til venstre, nederst til højre - ansigtet inden for et mikroskop med høj opløsning forbedret med evnen til at måle små kræfter
For første gang, forskere måler kræfter, der justerer krystaller og hjælper dem med at snappe sa…Lille bitte, slebne stykker af et titanoxidmineral kaldet rutil - øverst til venstre, nederst til højre - ansigtet inden for et mikroskop med høj opløsning forbedret med evnen til at måle små kræfter
- Heling af brændte poter med fiskeskind
- Forskere udvikler ny metode til at kontrollere nanoenheder
- Nogle planter bliver større – og slemmere – når de klippes, undersøgelse finder
- Volkswagen står over for første kæmpe diesel-retssag på hjemmebane
- Teleskop i Chile fanger en dødsdømt galakse, der falder ind i hjertet af Fornax-klyngen
- Forskellen mellem Sucralose & Fructose