


AI-teknik udfører dobbelt pligt, der spænder over kosmiske og subatomare skalaer
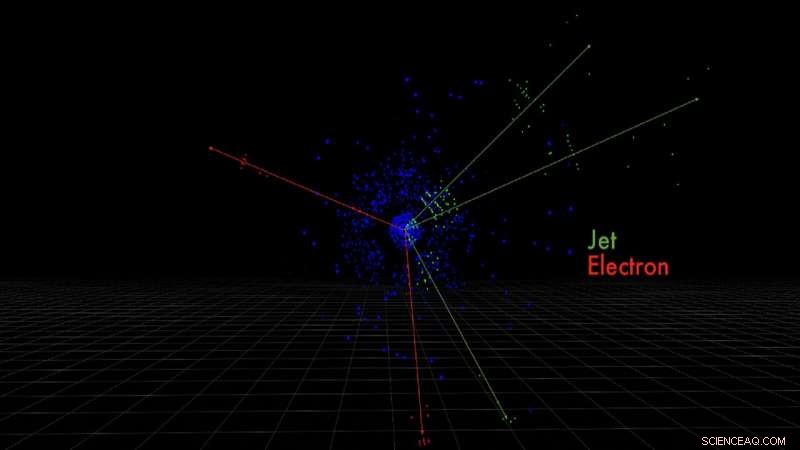
Disse er detektorpixel for elektroner og kvarkstråler produceret af en simuleret protonkollision, målt af ATLAS-detektoren. Kredit:Taylor Childers
Mens højenergifysik og kosmologi ser ud til at være verdener adskilt i forhold til ren skala, fysikere og kosmologer ved Argonne bruger lignende maskinlæringsmetoder til at løse klassifikationsproblemer for både subatomære partikler og galakser.
Højenergifysik og kosmologi ser ud til at være verdener adskilt med hensyn til ren og skær skala, men de usynlige komponenter, der udgør feltet af den ene, informerer om sammensætningen og dynamikken af den anden - kollapsende stjerner, stjernefødende tåger og, måske, mørkt stof.
I årtier, de teknikker, hvormed forskere i begge felter studerede deres domæner, virkede næsten uforenelige, såvel. Højenergifysik var afhængig af acceleratorer og detektorer for at få lidt indsigt fra partiklernes energetiske interaktioner, mens kosmologer kiggede gennem alverdens teleskoper for at afsløre universets hemmeligheder.
Selvom ingen af dem har opgivet det grundlæggende udstyr inden for deres særlige område, fysikere og kosmologer ved U.S. Department of Energy's (DOE) Argonne National Laboratory angriber komplekse multi-skala problemer ved hjælp af forskellige former for en kunstig intelligens teknik kaldet machine learning.
Allerede brugt på mange områder, maskinlæring kan hjælpe med at identificere skjulte mønstre ved at lære af inputdata og gradvist forbedre forudsigelser om nye data. Det kan anvendes til visuelle klassifikationsopgaver eller til hurtig gengivelse af komplicerede og beregningsmæssigt dyre beregninger.
Med potentialet til radikalt at transformere, hvordan videnskab udføres, disse AI-teknikker vil hjælpe os med at få en bedre forståelse af fordelingen af galakser i hele universet eller bedre visualisere dannelsen af nye partikler, hvorfra vi kan udlede ny fysik.
"I løbet af årtierne, vi har udviklet traditionelle algoritmer, der rekonstruerer signaturerne af de forskellige partikler, som vi er interesserede i, " sagde Taylor Childers, en partikelfysiker og en datalog med Argonne Leadership Computing Facility (ALCF), en DOE Office of Science brugerfacilitet.
"Det har taget meget lang tid at udvikle dem, og de er meget præcise, " tilføjede han. "Men på samme tid, det ville være interessant at vide, om billedklassificeringsteknikker fra maskinlæring, som er blevet brugt med succes af Google og Facebook, kan forenkle eller forkorte udviklingen af algoritmer, der identificerer partikelsignaturer i vores 3-D-detektorer."
Childers arbejder med Argonne højenergifysikere, som alle er medlemmer af ATLAS eksperimentelle samarbejde på CERNs Large Hadron Collider (LHC), den største og kraftigste partikelkolliderer i verden. Ønsker at løse en bred vifte af fysikproblemer, ATLAS-detektoren er otte etager høj og 150 fod lang på et punkt omkring LHC's 17-mile omkreds kolliderring, hvor den måler produkterne af protoner, der kolliderer med hastigheder, der nærmer sig lysets hastighed.
Ifølge ATLAS hjemmeside, "over en milliard partikelinteraktioner finder sted i ATLAS-detektoren hvert sekund, en datahastighed svarende til 20 samtidige telefonsamtaler afholdt af hver person på jorden."
Selvom kun en lille procent af disse kollisioner anses for at være værdige til undersøgelse - omkring en million i sekundet - giver det stadig et bjerg af data, som videnskabsmænd kan undersøge.
Disse højhastigheds-partikelkollisioner skaber nye partikler i deres kølvand, som elektroner eller kvarkbyger, hver efterlader en unik signatur i detektoren. Det er disse signaturer, som Childers gerne vil identificere gennem maskinlæring.
Blandt udfordringerne er at fange disse energisignaturer som billeder i et komplekst 3D-rum. Et billede, for eksempel, er i det væsentlige en 2-D repræsentation af 3-D data med lodrette og vandrette positioner. Pixeldata, farverne i billedet, er rumligt orienteret og har rumlig information indkodet i dem - f.eks. en kats øjne er ved siden af næsen, og ørerne er over til venstre og højre.
"Så deres rumlige orientering er vigtig. Det samme gælder for de billeder, vi tager ved LHC. Når en partikel krydser vores detektor, det efterlader en energisignatur i rumlige mønstre, der er specifikke for de forskellige partikler, " forklarede Childers.
Læg dertil mængden af data, der er kodet i ikke kun signaturerne, men 3D-rummet omkring dem. Hvor traditionelle maskinlæringseksempler til billedgenkendelse - de katte, igen – beskæftige dig med hundredtusindvis af pixels, ATLAS' billeder indeholder hundredvis af millioner af detektorpixel.
Så ideen, han sagde, er at behandle detektorbillederne som traditionelle billeder. Ved at bruge en maskinlæringsteknik kaldet konvolutionelle neurale netværk - som lærer, hvordan data er rumligt relateret - kan de udtrække 3D-rummet for lettere at identificere specifikke partikeltræk.

Billedet viser en Einstein-ring (midt til højre) dannet ved gravitationslinser af en stjernedannende galakse (blå) af en massiv lysende rød galakse (orange). Dette system blev først opdaget af Sloan Digital Sky Survey i 2007; billederne er fra Hubble-rumteleskopet. Kredit:NASA
Childers håber, at disse maskinlæringsalgoritmer med tiden vil erstatte de traditionelle håndlavede algoritmer, reducerer i høj grad den tid, det tager at behandle lignende mængder af data, samt forbedrer præcisionen af de målte resultater.
"Vi kan også erstatte den årtilange udvikling, der er nødvendig for nye detektorer og reducere det med nye træningsmodeller for fremtidige detektorer, " han sagde.
Et større rum
Argonne-kosmologer bruger lignende maskinlæringsmetoder til at løse klassifikationsproblemer, men i meget større skala.
"Problemet med kosmologi er, at de objekter, vi ser på, er komplicerede og uklare, " sagde Salman Habib, Divisionsdirektør for Argonnes Computational Science-afdeling og midlertidig vicedirektør for dens High Energy Physics-division. "Så det bliver meget svært at beskrive data på en enklere måde."
Han og hans kolleger udnytter supercomputere hos Argonne og andre DOE nationale laboratorier til at rekonstruere universets detaljer, galakse for galakse. De skaber meget detaljerede simulerede galaksekataloger, der kan bruges til sammenligning med rigtige data taget fra undersøgelsesteleskoper, ligesom Large Synoptic Survey Telescope, et partnerskab mellem DOE og National Science Foundation.
Men for at gøre disse aktiver værdifulde for forskere, de skal være så tæt på virkeligheden som muligt.
Maskinlæringsalgoritmer, Habib sagde, er meget gode til at udvælge funktioner, der let kan karakteriseres ved geometri - som de katte. Endnu, svarende til advarslen på køretøjets spejle, genstande i himlen er ikke altid, som de ser ud.
Tag fænomenet stærk gravitationslinser; forvrængning af en baggrundslyskilde - en galakse eller en galaksehob - af en mellemliggende masse. Afbøjningen af lysstrålernes baner fra kilden på grund af tyngdekraften fører til en forvrængning af baggrundskildens form, position og orientering; denne forvrængning giver information om massefordelingen af det mellemliggende objekt. Den faktiske observationssituation er ikke så ligetil, imidlertid.
En helt rund klat, der er linset, for eksempel, kan virke strakt i den ene eller anden retning, mens en runde, Et diskformet objekt uden linse kan se elliptisk ud, hvis det ses delvist på kanten.
"Så hvordan ved du, om det objekt, du ser på, ikke er et rundt objekt, der er blevet roteret, eller en, der er blevet lenset?" spurgte Habib. "Det er den slags vanskelige ting, som maskinlæring skal kunne finde ud af."
At gøre dette, forskere laver en træningsprøve af millioner af realistisk udseende objekter, hvoraf halvdelen er linse. Maskinlæringsalgoritmerne går derefter i gang med arbejdet med at forsøge at lære forskellene mellem de linsede og uopnåede objekter. Resultaterne er verificeret i forhold til et kendt sæt af syntetiske og ulinsede genstande.
Men resultaterne fortæller kun halvdelen af historien – hvor godt algoritmerne fungerer på testdata. For yderligere at fremme deres nøjagtighed for rigtige data, forskere blander en vis procentdel af syntetiske data med tidligere observerede data og kører algoritmerne, igen, sammenligne, hvor godt de valgte linseobjekter i træningsprøven versus kombinationsdataene.
"Til sidst, du kan finde ud af, at det gør det rimeligt godt, men måske ikke så godt som du ønsker, " forklarede Habib. "Du kan måske sige 'OK, denne information i sig selv vil ikke være tilstrækkelig, Jeg skal samle mere ind.' Det er en ret lang og kompleks proces."
To primære mål for moderne kosmologi, han sagde, er at forstå, hvorfor universets udvidelse accelererer, og hvad det mørke stofs natur er. Mørkt stof er omkring fem gange så rigeligt som normalt stof, men dens ultimative oprindelse forbliver mystisk. For at komme tæt på et svar, videnskaben skal være meget bevidst, meget præcist.
"På det nuværende stadie, Jeg tror ikke, vi kan løse alle vores problemer med maskinlæringsapplikationer, " indrømmede Habib. "Men jeg vil sige, at maskinlæring vil være meget vigtig for alle aspekter af præcisionskosmologi i den nærmeste fremtid."
Efterhånden som maskinlæringsteknikker udvikles og forfines, deres anvendelighed til både højenergifysik og kosmologi vil helt sikkert vokse eksponentielt, giver håb om nye opdagelser eller nye fortolkninger, der ændrer vores forståelse af verden på flere skalaer.
Sidste artikelHolder køligt med kvantebrønde
Næste artikelKombinerer spintronik og kvantetermodynamik for at høste energi ved stuetemperatur
 Varme artikler
Varme artikler
-
 Forskere skaber optiske præcisionskomponenter med inkjet-printForskere udviklede en to-trins inkjet printteknik, der kan lave optiske komponenter kendt som bølgeledere (a). En række dråber kaldet pinning caps udskrives først (hvide). Væskebroer mellem stifthætte
Forskere skaber optiske præcisionskomponenter med inkjet-printForskere udviklede en to-trins inkjet printteknik, der kan lave optiske komponenter kendt som bølgeledere (a). En række dråber kaldet pinning caps udskrives først (hvide). Væskebroer mellem stifthætte -
 At opnå metaloverflader med ultralav reflektivitetDen sorte prøve fremstillet af den cirkulært polariserede laser og dens morfologi. Kredit:XIOPM At fremstille mikro/nano strukturer på metaloverflader, forskellige teknologier er blevet foreslået,
At opnå metaloverflader med ultralav reflektivitetDen sorte prøve fremstillet af den cirkulært polariserede laser og dens morfologi. Kredit:XIOPM At fremstille mikro/nano strukturer på metaloverflader, forskellige teknologier er blevet foreslået, -
 Enkelte fotoner fra en siliciumchipSkematisk fremstilling af en enkelt defekt i en siliciumskive skabt ved implantation af carbonatomer, som udsender enkelte fotoner i telekom-O-båndet (bølgelængdeområde:1260 til 1360 nanometer) koblet
Enkelte fotoner fra en siliciumchipSkematisk fremstilling af en enkelt defekt i en siliciumskive skabt ved implantation af carbonatomer, som udsender enkelte fotoner i telekom-O-båndet (bølgelængdeområde:1260 til 1360 nanometer) koblet -
 Frugtfluer og elektroner:Forskere bruger fysik til at forudsige mængdenes adfærdElektroner, der suser rundt om hinanden og mennesker, der er stappet sammen ved et politisk stævne, synes ikke at have meget tilfælles, men forskere på Cornell forbinder prikkerne. De har udviklet en
Frugtfluer og elektroner:Forskere bruger fysik til at forudsige mængdenes adfærdElektroner, der suser rundt om hinanden og mennesker, der er stappet sammen ved et politisk stævne, synes ikke at have meget tilfælles, men forskere på Cornell forbinder prikkerne. De har udviklet en