


Maskinlæringsteknologi til at spore ulige hændelser blandt LHC-data
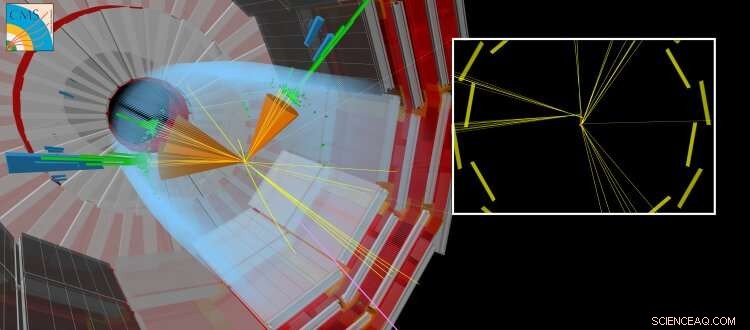
En simuleret CMS-kollision, hvor en langlivet partikel produceres sammen med andre 'almindelige' jetfly. Den langlivede partikel rejser en kort afstand, før den henfalder, skaber partikler, der ser ud til at være forskudt fra det punkt, hvor LHC-strålerne kolliderede. Kredit:CERN
I dag, kunstige neurale netværk har indflydelse på mange områder af vores daglige liv. De bruges til en lang række komplekse opgaver, som at køre bil, udfører talegenkendelse (f.eks. Siri, Cortana, Alexa), foreslår shopping varer og trends, eller forbedring af visuelle effekter i film (f.eks. animerede figurer som Thanos fra filmen Infinity War af Marvel).
Traditionelt, Algoritmer er håndlavede til at løse komplekse opgaver. Dette kræver, at eksperter bruger en betydelig mængde tid på at identificere de optimale strategier for forskellige situationer. Kunstige neurale netværk – inspireret af indbyrdes forbundne neuroner i hjernen – kan automatisk lære af data en tæt på optimal løsning til det givne mål. Tit, den automatiserede læring eller "træning", der kræves for at opnå disse løsninger, "overvåges" ved brug af supplerende information leveret af en ekspert. Andre tilgange er "uovervåget" og kan identificere mønstre i dataene. Den matematiske teori bag kunstige neurale netværk har udviklet sig over flere årtier, men først for nylig har vi udviklet vores forståelse af, hvordan man træner dem effektivt. De påkrævede beregninger minder meget om dem, der udføres af standard videografikkort (som indeholder en grafikprocessor eller GPU), når de gengiver tredimensionelle scener i videospil. Evnen til at træne kunstige neurale netværk på relativt kort tid er muliggjort ved at udnytte de massivt parallelle computeregenskaber i GPU'er til generelle formål. Den blomstrende videospilsindustri har drevet udviklingen af GPU'er. Dette fremskridt, sammen med de betydelige fremskridt inden for maskinlæringsteori og den stadigt stigende mængde af digitaliseret information, har været med til at indvarsle en tidsalder med kunstig intelligens og "deep learning".
Inden for højenergifysik, brugen af maskinlæringsteknikker, såsom simple neurale netværk eller beslutningstræer, har været i brug i flere årtier. For nylig, teorien og eksperimentelle fællesskaber henvender sig i stigende grad til de avancerede teknikker, såsom "dybe" neurale netværksarkitekturer, at hjælpe os med at forstå den grundlæggende natur af vores univers. Standardmodellen for partikelfysik er en sammenhængende samling af fysiske love - udtrykt i matematikkens sprog - der styrer de grundlæggende partikler og kræfter, som igen forklarer naturen af vores synlige univers. På CERN LHC, mange videnskabelige resultater fokuserer på søgen efter nye "eksotiske" partikler, som ikke forudsiges af standardmodellen. Disse hypotetiske partikler er manifestationerne af nye teorier, der har til formål at besvare spørgsmål som:hvorfor består universet overvejende af stof snarere end antistof, eller hvad er mørkt stofs natur?
-

Figur 1:Skematisk over netværksarkitekturen. De øverste (orange og blå) sektioner af diagrammet illustrerer komponenterne i netværket, der bruges til at skelne stråler produceret i henfald af langlivede partikler fra stråler produceret på anden måde, trænet med simulerede data. Den nederste (grønne) del af diagrammet viser de komponenter, der trænes ved hjælp af reelle kollisionsdata. Kredit:CERN
-
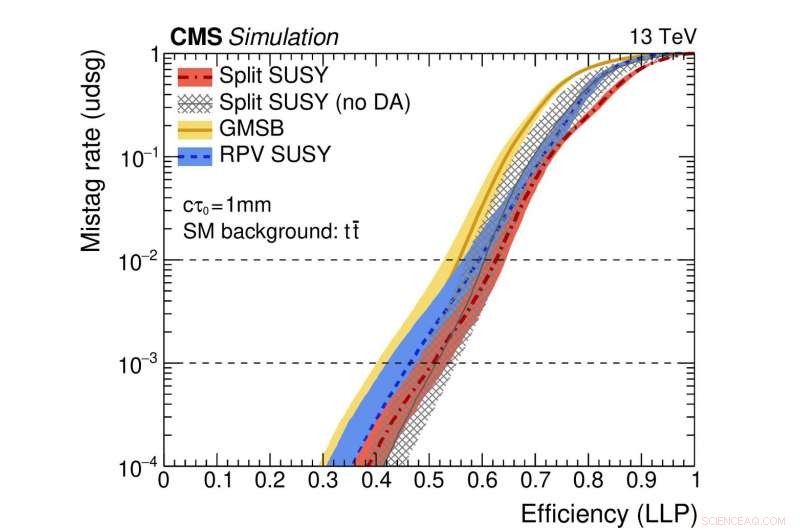
Figur 2:En illustration af netværkets ydeevne. De farvede kurver repræsenterer ydeevnen af forskellige teoretiske supersymmetriske modeller. Den vandrette akse giver effektiviteten til korrekt at identificere et langlivet partikelhenfald (dvs. den sand-positive hastighed). Den lodrette akse viser den tilsvarende falsk-positive rate, som er den del af standardstråler, der fejlagtigt identificeres som stammende fra henfaldet af en langlivet partikel. Som et eksempel, vi bruger et punkt på den røde kurve, hvor andelen af ægte langlivede partikler, der er korrekt identificeret, er 0,5 (dvs. 50 %). Denne metode fejlidentificerer kun én regulær jet ud af tusind fejlagtigt som stammende fra et langlivet partikelhenfald. Kredit:CERN
For nylig, søgninger efter nye partikler, der eksisterer i mere end et flygtigt øjeblik, før de henfalder til almindelige partikler, har fået særlig opmærksomhed. Disse "langlivede" partikler kan rejse målbare afstande (brøkdele af millimeter eller mere) fra proton-proton-kollisionspunktet i hvert LHC-eksperiment, før de henfalder. Tit, teoretiske forudsigelser antager, at den langlivede partikel er uopdagelig. I det tilfælde, kun partiklerne fra henfaldet af den uopdagede partikel vil efterlade spor i detektorsystemerne, fører til den ret atypiske eksperimentelle signatur af partikler, der tilsyneladende dukker op fra ingenting og er forskudt fra kollisionspunktet.
Et nyt aspekt af denne undersøgelse involverer brugen af data fra virkelige kollisionshændelser, samt simulerede hændelser, at træne netværket. Denne tilgang bruges, fordi simuleringen - selv om den er meget sofistikeret - ikke udtømmende gengiver alle detaljerne i de virkelige kollisionsdata. I særdeleshed, de jetfly, der stammer fra langlivede partikelhenfald, er udfordrende at simulere nøjagtigt. Effekten af at anvende denne teknik, kaldet "domænetilpasning, " er, at informationen fra det neurale netværk stemmer overens med et højt niveau af nøjagtighed for både reelle og simulerede kollisionsdata. Denne adfærd er et afgørende træk for algoritmer, der vil blive brugt ved søgninger efter sjældne nyfysiske processer, da algoritmerne skal demonstrere robusthed og pålidelighed, når de anvendes på data.
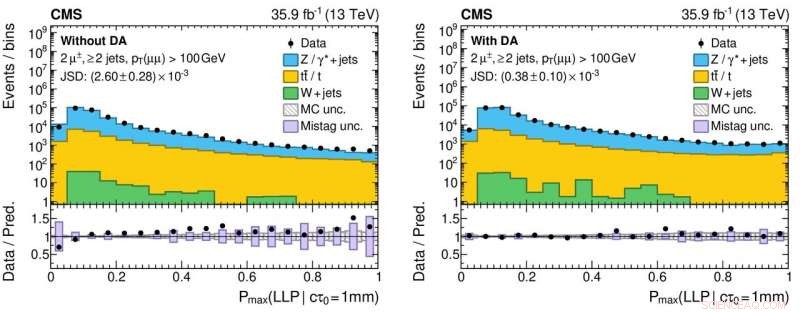
Figur 3:Histogrammer af outputværdierne fra det neurale netværk for reelle (sorte cirkulære markører) og simulerede (farvede fyldte histogrammer) proton-proton kollisionsdata uden (venstre panel) og med (højre panel) anvendelse af domænetilpasning. De nederste paneler viser forholdet mellem antallet af reelle data og simulerede hændelser opnået fra hver histogrambakke. Forholdene er væsentligt tættere på enhed for det rigtige panel, hvilket indikerer en forbedret forståelse af det neurale netværks ydeevne for reelle kollisionsdata, hvilket er afgørende for at reducere falsk positive (og falsk negative!) videnskabelige resultater, når man søger efter eksotiske nye partikler. Kredit:CERN
CMS Collaboration vil implementere dette nye værktøj som en del af dets igangværende søgen efter eksotiske, langlivede partikler. Denne undersøgelse er en del af en større, koordineret indsats på tværs af alle LHC-eksperimenterne for at bruge moderne maskinteknikker til at forbedre, hvordan de store dataprøver registreres af detektorerne og den efterfølgende dataanalyse. For eksempel, brugen af domænetilpasning kan gøre det lettere at implementere robuste maskinlærte modeller som en del af fremtidige resultater. Erfaringerne fra disse typer undersøgelser vil øge fysikpotentialet under løb 3, fra 2021, og videre med High Luminosity LHC.
Sidste artikelForskere forhindrer kritisk sammenbrud af højereordens solitoner
Næste artikelForskere ser på støjende kvantecomputer
 Varme artikler
Varme artikler
-
 Lagdeling i cafe lattes giver indsigt i teknik, medicin og miljøPrinceton -forskere undersøger arten af lagdelte væsker, såsom cafe latte. Kredit:Sameer Khan/Fotobuddy For alle, der har undret sig over de rigt farvede lag i en cafe latte, du er ikke alene. P
Lagdeling i cafe lattes giver indsigt i teknik, medicin og miljøPrinceton -forskere undersøger arten af lagdelte væsker, såsom cafe latte. Kredit:Sameer Khan/Fotobuddy For alle, der har undret sig over de rigt farvede lag i en cafe latte, du er ikke alene. P -
 Mikroskopisystemer, der anvender skræddersyede chips, kan udvide identifikation af patogener på st…Struktur og drift af mikrofluidchippen. Kredit:Viri et al. Udvikling af omkostningseffektive, bærbare mikroskopienheder ville i høj grad udvide deres anvendelse i fjerntliggende felter og på stede
Mikroskopisystemer, der anvender skræddersyede chips, kan udvide identifikation af patogener på st…Struktur og drift af mikrofluidchippen. Kredit:Viri et al. Udvikling af omkostningseffektive, bærbare mikroskopienheder ville i høj grad udvide deres anvendelse i fjerntliggende felter og på stede -
 Superakologisk fotoakustisk billeddannelse kan give forskere mulighed for at se blodkar med forbedre…Disse billeder sammenligner billeddannelsen af blod, der strømmer gennem fem kanaler med forskellige tilgange. Øverst er enkelte fotoakustiske billeder fra den billedstak, forskerne analyserede. Ned
Superakologisk fotoakustisk billeddannelse kan give forskere mulighed for at se blodkar med forbedre…Disse billeder sammenligner billeddannelsen af blod, der strømmer gennem fem kanaler med forskellige tilgange. Øverst er enkelte fotoakustiske billeder fra den billedstak, forskerne analyserede. Ned -
 Næste generations teknologi kommer til en selvkørende bil nær digProfessor Jayakanth Ravichandran og ph.d.-studerende Shanyuan Niu i laboratoriet, hvor de udvikler næste generations teknologier. Kredit:Valentina Suarez, Foto leveret af:Jayakanth Ravichandran Ty
Næste generations teknologi kommer til en selvkørende bil nær digProfessor Jayakanth Ravichandran og ph.d.-studerende Shanyuan Niu i laboratoriet, hvor de udvikler næste generations teknologier. Kredit:Valentina Suarez, Foto leveret af:Jayakanth Ravichandran Ty
- Sådan laver du en EDTA-løsning
- Et første glimt dybt under en ultralavspredende mid-ocean højderyg
- Fire hårde tiltag, der ville hjælpe med at bekæmpe den globale plastikkrise
- Nanoskala visualisering af fordelingen og optisk adfærd af dopingmiddel i GaN
- Rekordstor solceller gør klar til masseproduktion
- New Australia massefiskdødsfald i centrale flodsystem