


For at finde den rigtige netværksmodel, sammenligne alle mulige historier
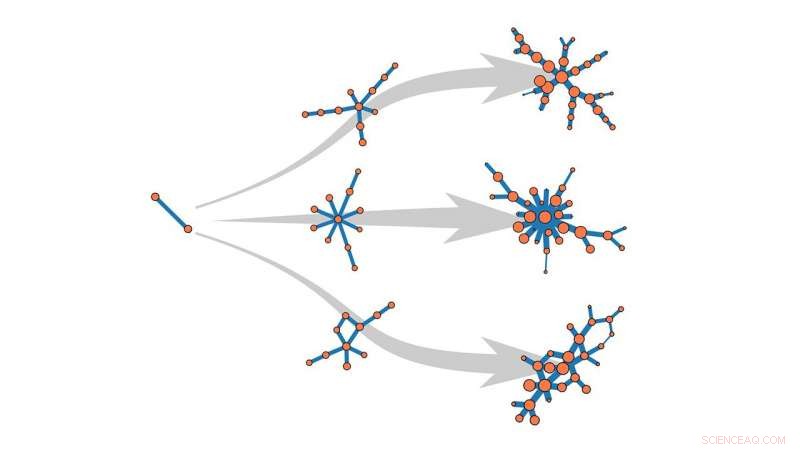
Kredit:Jean-Gabriel Young
To familiemedlemmer tester positive for COVID-19 – hvordan ved vi, hvem der har smittet hvem? I en perfekt verden, netværksvidenskab kunne give et sandsynligt svar på sådanne spørgsmål. Det kunne også fortælle arkæologer, hvordan et skår af græsk keramik kom til at blive fundet i Egypten, eller hjælpe evolutionære biologer med at forstå, hvordan en forlængst uddød forfader metaboliserede proteiner.
Som verden er, videnskabsmænd har sjældent de historiske data, de har brug for, for at se præcis, hvordan noder i et netværk blev forbundet. Men et nyt blad udgivet i Fysisk gennemgangsbreve giver håb om at rekonstruere den manglende information, ved hjælp af en ny metode til at evaluere de regler, der genererer netværksmodeller.
"Netværksmodeller er som impressionistiske billeder af dataene, " siger fysiker George Cantwell, en af undersøgelsens forfattere og en postdoc-forsker ved Santa Fe Institute. "Og der har været en række debatter om, hvorvidt de rigtige netværk ligner disse modeller nok til, at modellerne er gode eller nyttige."
Normalt når forskere forsøger at modellere et voksende netværk - siger, en gruppe individer, der er inficeret med en virus - de bygger modelnetværket op fra bunden, følge et sæt matematiske instruktioner for at tilføje et par noder ad gangen. Hver knude kunne repræsentere et inficeret individ, og hver kant en forbindelse mellem disse individer. Når klyngerne af noder i modellen ligner de data, der er hentet fra de virkelige tilfælde, modellen anses for at være repræsentativ - en problematisk antagelse, når det samme mønster kan være resultatet af forskellige sæt instruktioner.
Cantwell og medforfatterne Guillaume St-Onge (University Laval, Quebec) og Jean-Gabriel Young (University of Vermont) ønskede at bringe et skud statistisk stringens til modelleringsprocessen. I stedet for at sammenligne funktioner fra et øjebliksbillede af netværksmodellen med funktionerne fra data fra den virkelige verden, de udviklede metoder til at beregne sandsynligheden for hver mulig historie for et voksende netværk. Givet konkurrerende regelsæt, som kunne repræsentere processer i den virkelige verden, såsom kontakt, dråbe, eller luftbåren transmission, forfatterne kan anvende deres nye værktøj til at bestemme sandsynligheden for, at specifikke regler resulterer i det observerede mønster.
"I stedet for bare at spørge 'ligner dette billede mere den ægte vare?'" siger Cantwell, "Vi kan nu stille materielle spørgsmål som, 'voksede det efter disse regler?'" Når den mest sandsynlige netværksmodel er fundet, den kan spole tilbage for at besvare spørgsmål som f.eks. hvem der blev smittet først.
I deres nuværende papir, forfatterne demonstrerer deres algoritme på tre simple netværk, der svarer til tidligere dokumenterede datasæt med kendte historier. De arbejder nu på at anvende værktøjet til mere komplicerede netværk, som kunne finde applikationer på tværs af et vilkårligt antal komplekse systemer.
 Varme artikler
Varme artikler
-
 Forskere forklarer, hvorfor nogle origami ikke kan foldes under presVidenskabsmænd og ingeniører er fascineret af selvfoldende strukturer. Forestil dig mulighederne:hjertestents, der folder sig ud på det rigtige sted eller pop-up telte, der samles ved et tryk på en kn
Forskere forklarer, hvorfor nogle origami ikke kan foldes under presVidenskabsmænd og ingeniører er fascineret af selvfoldende strukturer. Forestil dig mulighederne:hjertestents, der folder sig ud på det rigtige sted eller pop-up telte, der samles ved et tryk på en kn -
 Kvantenegativitet kan give ultrapræcise målingerKvantelaserlys skinner på et kemisk molekyle, som vi ønsker at måle. Så passerer lyset vores magiske kvantefilter. Dette filter kasserer meget lys, samtidig med at al nyttig information kondenseres i
Kvantenegativitet kan give ultrapræcise målingerKvantelaserlys skinner på et kemisk molekyle, som vi ønsker at måle. Så passerer lyset vores magiske kvantefilter. Dette filter kasserer meget lys, samtidig med at al nyttig information kondenseres i -
 In-situ-diagnostik af femtosekund-lasersondeimpulser til ultrahurtige billeddannelsesapplikationerKoncept og eksperimentel opsætning - (a) Koncept af det transiente gitter induceret af den formede infrarøde pumpeimpuls i et transparent dielektrikum. Probesignalet, der diffrakteres af det transient
In-situ-diagnostik af femtosekund-lasersondeimpulser til ultrahurtige billeddannelsesapplikationerKoncept og eksperimentel opsætning - (a) Koncept af det transiente gitter induceret af den formede infrarøde pumpeimpuls i et transparent dielektrikum. Probesignalet, der diffrakteres af det transient -
 Forskere udvikler laserbaseret proces til 3-D-print af detaljerede glasobjekterForskere har udviklet en ny laserbaseret proces til 3D-printning af indviklede dele lavet af glas. Den bruger multifotonpolymerisering til at skabe objektet direkte i et 3D-volumen. Kredit:Laurent Gal
Forskere udvikler laserbaseret proces til 3-D-print af detaljerede glasobjekterForskere har udviklet en ny laserbaseret proces til 3D-printning af indviklede dele lavet af glas. Den bruger multifotonpolymerisering til at skabe objektet direkte i et 3D-volumen. Kredit:Laurent Gal
- Hvad er valensen af hydrogen?
- Havets optagelse af kuldioxid kan falde, efterhånden som kulstofemissionerne reduceres
- Drivkraft af vulkanske superfarer afdækket
- Håbets by rejser sig fra Madagaskars affaldsplads
- Forskere undersøger kemien i en enkelt batterielektrodepartikel både inde og ude
- Livscyklus for en Acorn Seedling ind i et træ