


Brugen af deep learning til fasegenopretning
Lys, som et elektromagnetisk felt, har to væsentlige komponenter:amplitude og fase. Optiske detektorer, der normalt er afhængige af foton-til-elektron-konvertering (såsom ladningskoblede enhedssensorer og det menneskelige øje), kan dog ikke fange lysfeltets fase på grund af deres begrænsede prøvetagningsfrekvens.
Heldigvis, når lysfeltet udbreder sig, forårsager faseforsinkelsen også ændringer i amplitudefordelingen; derfor kan vi registrere amplituden af det udbredte lysfelt og derefter beregne den tilsvarende fase, kaldet fasegendannelse.
Nogle almindelige fasegendannelsesmetoder omfatter holografi/interferometri, Shack-Hartmann-bølgefrontføling, transport af intensitetsligning og optimeringsbaserede metoder (fasegenfinding). De har deres egne mangler med hensyn til rumlig-tidsmæssig opløsning, beregningsmæssig kompleksitet og anvendelsesområde.
I de seneste år, som et vigtigt skridt mod ægte kunstig intelligens (AI), har dyb læring, ofte implementeret gennem dybe neurale netværk, opnået en hidtil uset ydeevne i fasegendannelse.
I et reviewpapir offentliggjort i Light:Science &Applications , videnskabsmænd fra The University of Hong Kong, Northwestern Polytechnical University, The Chinese University of Hong Kong, Guangdong University of Technology og Massachusetts Institute of Technology har gennemgået forskellige metoder til gendannelse af deep learning fase ud fra følgende fire perspektiver:
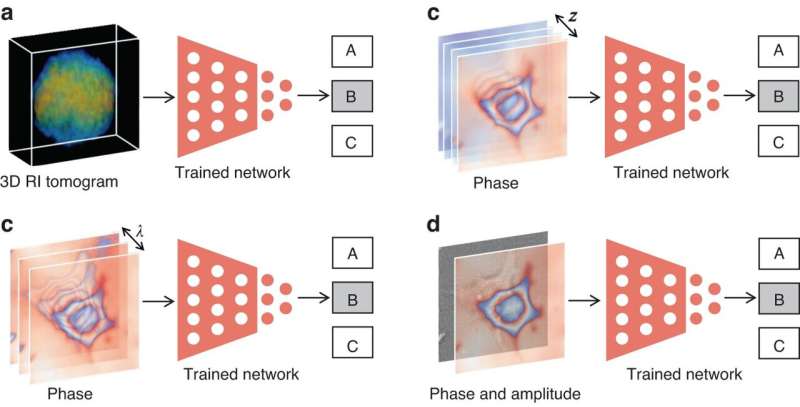
- Deep-learning-pre-processing til fasegendannelse:Det neurale netværk udfører en vis forbehandling af intensitetsmålingen før fasegendannelse, såsom pixel super-opløsning, støjreduktion, hologramgenerering og autofokusering.
- Deep-learning-in-processing til fasegendannelse:Det neurale netværk udfører direkte fasegendannelse eller deltager i processen med fasegendannelse sammen med den fysiske model eller fysikbaserede algoritme ved overvågede eller ikke-overvågede indlæringstilstande.
- Deep-learning-post-processing til fasegendannelse:Det neurale netværk udfører efterbehandling efter fasegendannelse, såsom støjreduktion, opløsningsforbedring, aberrationskorrektion og faseudpakning.
- Dyb læring til fasebehandling:Det neurale netværk bruger den genvundne fase til specifikke applikationer, såsom segmentering, klassificering og billeddannelse modal transformation.
For at lade læserne lære mere om fasegendannelse præsenterede de også en live-opdateringsressource (https://github.com/kqwang/phase-recovery).
Når dyb læring anvendes på forskellige processer af fasegendannelse, bringer det ikke kun hidtil usete effekter, men introducerer også nogle uforudsigelige risici. Nogle metoder kan se ens ud, men der er forskelle, som er svære at opdage. Disse videnskabsmænd påpeger forskellene og forbindelserne mellem nogle lignende metoder og gav forslag til, hvordan man får mest muligt ud af dyb læring og fysiske modeller til fasegendannelse:
"Det skal bemærkes, at uPD (utrænet fysik-drevet) skemaet er fri for talrige intensitetsbilleder som en forudsætning, men kræver adskillige iterationer for hver inferens; mens tPD (trained physics-driven) skemaet fuldender inferensen kun passerer gennem trænet neurale netværk én gang, men kræver et stort antal intensitetsbilleder til fortræning."
"zf er en fast vektor, hvilket betyder, at input fra det neurale netværk er uafhængigt af prøven, og derfor kan det neurale netværk ikke fortrænes som PD-tilgangen," sagde de, da de introducerede den strukturelle tidligere netværk-i-fysik strategi. .
"Læringsbaserede dybe neurale netværk har et enormt potentiale og effektivitet, mens konventionelle fysikbaserede metoder er mere pålidelige. Vi opfordrer således til inkorporering af fysiske modeller med dybe neurale netværk, især for dem, der godt modellerer fra den virkelige verden, snarere end at lade dybe neurale netværk udfører alle opgaver som en 'sort boks'," sagde forskerne.
Flere oplysninger: Kaiqiang Wang et al., Om brugen af dyb læring til fasegendannelse, Light:Science &Applications (2024). DOI:10.1038/s41377-023-01340-x
Journaloplysninger: Lys:Videnskab og applikationer
Leveret af Light Publishing Center, Changchun Institute of Optics, Fine Mechanics And Physics, CAS
 Varme artikler
Varme artikler
-
 Strukturen af sten fra fossile brændstoffer er endelig afkodetVed hjælp af et system med høj opløsning kaldet elektron tomografi, forskere undersøgte en lille prøve af kerogen for at bestemme dens indre struktur. Til venstre, prøven set udefra, og til højre, det
Strukturen af sten fra fossile brændstoffer er endelig afkodetVed hjælp af et system med høj opløsning kaldet elektron tomografi, forskere undersøgte en lille prøve af kerogen for at bestemme dens indre struktur. Til venstre, prøven set udefra, og til højre, det -
 Skræddersyet lys inspireret af naturenFremstillingsproceduren for en ikke -fraktion af et lysfelt ved hjælp af en ønsket tværgående ætsende. Kredit:WWU - Alessandro Zannotti Moderne applikationer som f.eks. Højopløselig mikroskopi ell
Skræddersyet lys inspireret af naturenFremstillingsproceduren for en ikke -fraktion af et lysfelt ved hjælp af en ønsket tværgående ætsende. Kredit:WWU - Alessandro Zannotti Moderne applikationer som f.eks. Højopløselig mikroskopi ell -
 Makroskopiske fænomener styret af mikroskopisk fysikFigur:Billeddannelse af plasmaemission viser de plasmoid- og cusp-lignende træk, der er typiske for magnetiske genforbindelser. Kredit:Osaka University Det har været svært at få mikro- og makrosko
Makroskopiske fænomener styret af mikroskopisk fysikFigur:Billeddannelse af plasmaemission viser de plasmoid- og cusp-lignende træk, der er typiske for magnetiske genforbindelser. Kredit:Osaka University Det har været svært at få mikro- og makrosko -
 Ur -sorte huller kan have hjulpet med at smede tunge elementerKunstnerens skildring af en neutronstjerne. Kredit:NASA Astronomer kan lide at sige, at vi er biprodukter af stjerner, stjerneovne, der for længe siden smeltede brint og helium sammen til de grund
Ur -sorte huller kan have hjulpet med at smede tunge elementerKunstnerens skildring af en neutronstjerne. Kredit:NASA Astronomer kan lide at sige, at vi er biprodukter af stjerner, stjerneovne, der for længe siden smeltede brint og helium sammen til de grund
- Ny sproglig analyse finder, at den dravidiske sprogfamilie er cirka 4, 500 år gammel
- Højstyrke pultruderede termoplastiske kompositter lavet af nyt råmateriale
- National undersøgelse af nanomaterialetoksicitet sætter scenen for politikker til håndtering af s…
- Ny algoritme finder det optimale bindingsbrudpunkt for enkelte molekyler
- Luftforurening er fortsat lav, da europæerne bliver hjemme
- Blandt par, pandemien fortsætter med at påvirke kvinder uforholdsmæssigt