


Open source-software behandler hurtigt spektrale data, identificerer og kvantificerer lipidarter nøjagtigt
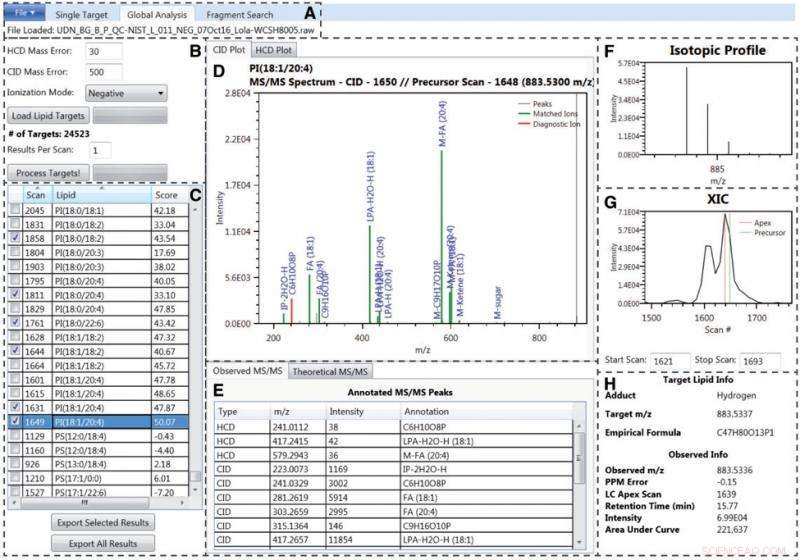
LIQUID-grænsefladen. Kredit:Pacific Northwest National Laboratory
Lipider spiller en nøglerolle i mange stofskiftesygdomme, herunder hypertension, diabetes, og slagtilfælde. Så det er vigtigt at have en komplet profil af kroppens lipider - dens "lipidom".
Lipidomiske undersøgelser er ofte baseret på væskekromatografi kombineret med tandem massespektrometri (LC-MS/MS). Men forskere har svært ved at behandle data hurtigt nok, og de er ude af stand til sikkert at identificere og nøjagtigt kvantificere de påviste lipidarter.
Forkerte identifikationer kan resultere i vildledende biologiske fortolkninger. Alligevel er eksisterende værktøjer ikke designet til storvolumen verifikation af identifikationer og skal verificeres manuelt for at sikre nøjagtighed. Da forskere i stigende grad ønsker større lipidomiske undersøgelser, analytikere har brug for forbedret software til at identificere lipider.
Et nyligt papir af hovedforfatter Jennifer E. Kyle og otte medforfattere ved Pacific Northwest National Laboratory (PNNL) introducerer en open source lipididentifikationssoftware, Lipidkvantificering og -identifikation (LIQUID). Scoringen kan trænes, søgedatabasen kan tilpasses, og flere bevislinjer vises, giver mulighed for sikker identifikation. LIQUID gør også enkelt- og globale søgninger tilgængelige, samt fragment-mønstersøgninger. Alt dette gør det muligt for forskere at spore lignende og gentagne mønstre af MS/MS-spektre.
Sammenlignet med anden frit tilgængelig software, der almindeligvis bruges til at identificere lipider og andre små molekyler, LIQUID har en hurtig behandlingstid, der kan generere et højere antal validerede lipididentifikationer hurtigere. Dens referencedatabase omfatter mere end 21, 200 unikke lipidmål på tværs af seks lipidkategorier, 24 klasser, og 63 underklasser.
LIQUID er i stand til sikkert at identificere flere lipidarter med en hurtigere kombineret behandlings- og valideringstid end nogen anden software inden for sit felt.
Hvad er det næste?
Udviklere af LIQUID vil øge referencebiblioteket til at inkludere lipider, der kan være unikke for bestemte sygdomstilstande eller for organismer fra udvalgte miljønicher. Dette betyder, at forskere vil være i stand til at karakterisere en mere mangfoldig række af prøver og derfor øge forståelsen af biologiske og miljømæssige systemer af interesse.
 Varme artikler
Varme artikler
-
 Meget effektiv, langtidsholdbar elektrokatalysator for at øge produktionen af brintbrændstofKrystalstruktur af iltrig metallegering på overfladen (øverst til venstre). Ilt og brint dannes under en vandelektrolysereaktion (øverst til højre). Den designede katalysator udviser den bedste oxygen
Meget effektiv, langtidsholdbar elektrokatalysator for at øge produktionen af brintbrændstofKrystalstruktur af iltrig metallegering på overfladen (øverst til venstre). Ilt og brint dannes under en vandelektrolysereaktion (øverst til højre). Den designede katalysator udviser den bedste oxygen -
 Hvad er en homolog serie?I kemi er en homolog serie en gruppe af forbindelser, der deler den samme basiske kemiske sammensætning, men adskiller sig i antallet af iterationer af et bestemt aspekt af deres struktur. Homologe se
Hvad er en homolog serie?I kemi er en homolog serie en gruppe af forbindelser, der deler den samme basiske kemiske sammensætning, men adskiller sig i antallet af iterationer af et bestemt aspekt af deres struktur. Homologe se -
 Forbedring af limningen af plast i højpræcisions mikrofluidchipsMikrofluidchips gør det muligt at analysere en dråbe blod næsten øjeblikkeligt og har potentialet til at revolutionere sundhedsvæsenet. Kredit:A*STAR Singapore Institute of Manufacturing Technology
Forbedring af limningen af plast i højpræcisions mikrofluidchipsMikrofluidchips gør det muligt at analysere en dråbe blod næsten øjeblikkeligt og har potentialet til at revolutionere sundhedsvæsenet. Kredit:A*STAR Singapore Institute of Manufacturing Technology -
 Dynamiske katalysatorer til ren luft i byenEn bils katalysator omdanner giftigt kulilte (CO) til giftfri kuldioxid (CO2) og består af cerium (Ce), ilt (O), og platin (Pt). Kredit:Gänzler/KIT Reduktion af forurenende emissioner af køretøjer
Dynamiske katalysatorer til ren luft i byenEn bils katalysator omdanner giftigt kulilte (CO) til giftfri kuldioxid (CO2) og består af cerium (Ce), ilt (O), og platin (Pt). Kredit:Gänzler/KIT Reduktion af forurenende emissioner af køretøjer
- Google opdaterer rapportering om uredelighed på grund af medarbejdernes utilfredshed
- De seks dele af et eksperimentelt videnskabsprojekt
- Data-relæsatellit klar til service
- Sådan fungerer Tweet-A-Watt
- Hvordan man opbygger en mumie Diorama til en sjette klasse projekt
- Nanorør nøglen til mikroskopisk mekanik