


Brug af neurale netværk til at forudsige resultaterne af organisk kemi
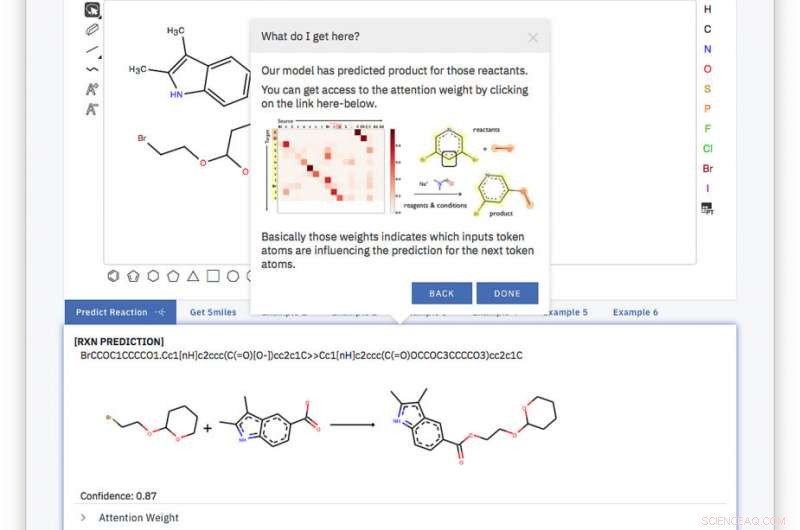
Det webbaserede værktøj er enkelt, og modellen er uddannet fra ende til anden, fuldt datadrevet og uden hjælp til forespørgsel i en database eller yderligere eksterne oplysninger. Kredit:IBM
I mere end 200 år har syntesen af organiske molekyler er fortsat en af de vigtigste opgaver inden for organisk kemi. Kemikeres arbejde har videnskabelige og kommercielle konsekvenser, der spænder fra produktionen af aspirin til Nylon. Endnu, lidt er gjort for dramatisk at ændre alder gamle metoder og tillade en ny æra af produktivitet baseret på banebrydende kunstig intelligens (AI) videnskab og teknologier.
Udfordringen for organiske kemikere inden for områder som kemi, materialevidenskab, olie og gas, og biovidenskab er, at der er hundredtusinder af reaktioner og, mens det er overskueligt at huske et par dusin inden for et snævert specialistområde, det er umuligt at være ekspert generalist.
For at imødegå dette spurgte vi os selv kan vi bruge dyb læring og kunstig intelligens til at forudsige reaktioner af organiske forbindelser?
Først, siden vi studerede teknik og materialevidenskab, men ikke organisk kemi, vi måtte ramme bøgerne. Det var ikke længe, før vi begyndte at se organisk kemi overalt - morgen, middag og nat. Atomer dukkede op i stedet for bogstaver, molekyler materialiseret fra ord og, derefter, der skete noget utroligt:en idé blev født.
Vi indså, at organiske kemidatasæt og sprogdatasæt har meget tilfælles:de er begge afhængige af grammatik, på langdistanceafhængigheder, og en lille partikel eller et ord som "ikke" kan ændre hele betydningen af en sætning ligesom stereokemien kan gøre Thalidomide til enten en medicin eller en dødelig gift.
Som ikke-indfødte engelsktalende kender vi begge online oversættelsesværktøjer, som var værker for at gøre engelsk til fransk, og tysk til engelsk, så hvorfor ikke prøve at bruge dem til at omdanne tilfældige kemikalier til funktionelle forbindelser?
På NIPS 2017-konferencen præsenterer vi vores resultater:en webbaseret app, der tager ideen om at knytte organisk kemi til et sprog og anvender state-of-the-art neurale maskinoversættelsesmetoder til at gå fra at designe materialer til at generere produkter ved hjælp af sekvens- to-sequence (seq2seq) modeller.
Kemi 101
Tilbage i gymnasiet, vi måtte tegne sekskanter og femkanter i hånden og alle de forskellige linjer, der repræsenterer bindinger af organiske molekyler. Nu har vi bragt et system op, der tager præcis den samme repræsentation og kan forudsige, hvordan molekyler vil reagere inden for et klik.
Det overordnede værktøj er enkelt, og modellen er uddannet fra ende til anden, fuldt datadrevet og uden hjælp til forespørgsel i en database eller yderligere eksterne oplysninger. Med denne tilgang, vi overgår nuværende løsninger ved hjælp af deres egne trænings- og testsæt ved at opnå en top-1-nøjagtighed på 80,3 procent og sætter en første score på 65,4 procent på et støjende datasæt med enkelte produktreaktioner udvundet af amerikanske patenter.
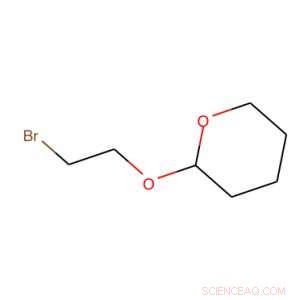
Brug af SMILES, dette molekyle oversættes til BrCCOC1OCCCC1. Kredit:IBM
Hemmeligheden bag vores værktøj er det, der kaldes et forenklet molekylært input line-entry system eller SMILES. SMILES repræsenterer et molekyle som en sekvens af karakter. For eksempel, billedet til højre, bliver BrCCOC1OCCCC1.
Vi trænede vores model ved hjælp af et åbent tilgængeligt kemisk reaktionsdatasæt, hvilket svarer til 1 million patentreaktioner.
I fremtiden, vi sigter mod at forbedre modellen og forbedre vores nøjagtighed ved at udvide vores datasæt. I øjeblikket er vores data hentet fra oplysninger, der er offentligt tilgængelige i amerikanske patenter, der er offentliggjort online, men der er ingen grund til, at værktøjet ikke kunne trænes i data fra andre kilder, såsom kemi lærebøger og videnskabelige publikationer.
Vi planlægger også at gøre dette værktøj gratis offentligt tilgængeligt på skyen i begyndelsen af 2018.
Tilmeld dig på www.zurich.ibm.com/foundintranslation for at modtage en advarsel, når webværktøjet er klar.
 Varme artikler
Varme artikler
-
 Smart blæk tilføjer nye dimensioner til 3D-udskrivningEt eksempel fra forskningen viser, hvordan et 3D-printet objekt sammensat af hydrogel (G1) kan ændre størrelse efter udskrivning. Selvom dette eksempel tjener til at demonstrere resultatet, andre obje
Smart blæk tilføjer nye dimensioner til 3D-udskrivningEt eksempel fra forskningen viser, hvordan et 3D-printet objekt sammensat af hydrogel (G1) kan ændre størrelse efter udskrivning. Selvom dette eksempel tjener til at demonstrere resultatet, andre obje -
 Hvad er et matchhoved lavet af?Kampe har eksisteret i en overraskende lang tid. De første svovlbaserede tændstikker dukkede op i 1200-tallet, og en måde at slå dem på ved hjælp af fosfor-gennemvædet papir blev udtænkt i 1600erne
Hvad er et matchhoved lavet af?Kampe har eksisteret i en overraskende lang tid. De første svovlbaserede tændstikker dukkede op i 1200-tallet, og en måde at slå dem på ved hjælp af fosfor-gennemvædet papir blev udtænkt i 1600erne -
 De bedste isolatorer til at holde vandet varmtDe korrekte isoleringsmaterialer holder væske varm i lange perioder. Uanset om det er til vandkedlen derhjemme eller en kolbe kaffe, reflekterer en god isolator enten varmen tilbage til kilden eller s
De bedste isolatorer til at holde vandet varmtDe korrekte isoleringsmaterialer holder væske varm i lange perioder. Uanset om det er til vandkedlen derhjemme eller en kolbe kaffe, reflekterer en god isolator enten varmen tilbage til kilden eller s -
 Forskere udvikler en ny clip-on-enhed til smartphones til analyse af sædcellerKredit:Lukasz Pawel Szczepanski, Shutterstock Mandlig infertilitetstest udføres i øjeblikket udelukkende i laboratorier, kræver flere besøg og flere dage for at få et resultat. Det EU-finansierede
Forskere udvikler en ny clip-on-enhed til smartphones til analyse af sædcellerKredit:Lukasz Pawel Szczepanski, Shutterstock Mandlig infertilitetstest udføres i øjeblikket udelukkende i laboratorier, kræver flere besøg og flere dage for at få et resultat. Det EU-finansierede
- Koralrev nær ækvator mindre påvirket af havets opvarmning
- Transformerende magnetisk lagring kan stamme fra visionen om kvante
- Hvad er forskellen mellem et monosaccharid og et disaccharid?
- Topologiske bølger kan hjælpe med at forstå plasmasystemer
- Samsung Electronics flag 56% fald i driftsresultatet i 3. kvartal
- Folk er mere sikre på vacciner i lande, hvor tilliden til videnskaben er høj