


Automatisk databaseoprettelse til materialeopdagelse:Innovation fra frustration
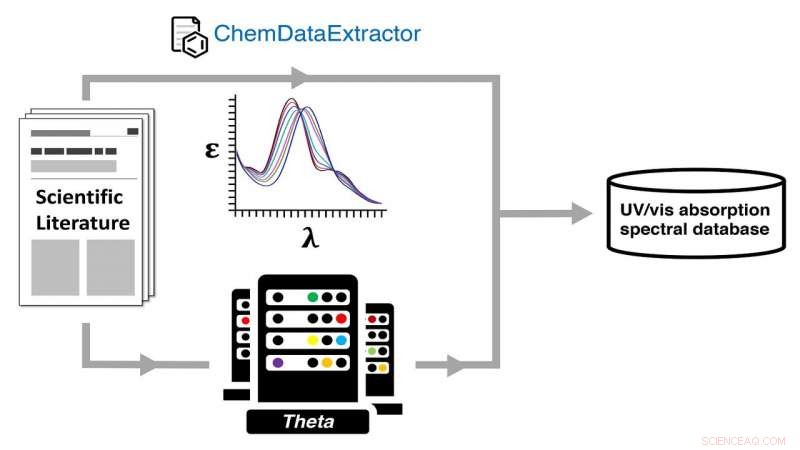
Autogenerering af en ultraviolet-synlig (UV-vis) absorptionsspektral database via en dobbelt eksperimentel og beregningsmæssig kemisk datavej ved hjælp af ALCF's Theta-supercomputer. Kredit:Jacqueline Cole og Ulrich Mayer / University of Cambridge
Et samarbejde mellem University of Cambridge og Argonne har udviklet en teknik, der genererer automatiske databaser til at understøtte specifikke videnskabsområder ved hjælp af kunstig intelligens og højtydende computing.
At søge gennem bunkevis af videnskabelig litteratur efter bits og bytes af information for at understøtte en idé eller finde nøglen til at løse et specifikt problem har længe været en kedelig affære for forskere, selv efter begyndelsen af datadrevet opdagelse.
Jacqueline Cole kender øvelsen, alt for godt. Leder af Molekylær Engineering ved University of Cambridge, Det Forenede Kongerige, hun har brugt meget af sin karriere på at søge efter materialer med optiske egenskaber, der egner sig til mere effektiv lysindsamling, som farvestofmolekyler, der en dag kan drive solcellevinduer.
"Jeg vidste, at meget af informationen blev holdt i meget fragmenteret form på tværs af litteraturen, " husker hun. "Men hvis du har samlet på tværs af tusinder og atter tusinder af dokumenter, så kunne du danne din egen database."
Så Cole og kolleger ved Cambridge og det amerikanske energiministeriums (DOE) Argonne National Laboratory gjorde netop det, udlægning af processen i journalen Videnskabelige data .
Papiret, siger Cole, er en beskrivelse af, hvordan man opbygger en database ved hjælp af naturlig sprogbehandling (NLP) og højtydende databehandling, meget af sidstnævnte udførte på Argonne Leadership Computing Facility (ALCF), en DOE Office of Science brugerfacilitet.
Blandt de faktorer, der gør databasen unik, er projektets omfang og det faktum, at det omfatter både eksperimentelle og beregnede data om begge materialestrukturer, som beskriver det atomare eller kemiske grundlag for en ting, og materialeegenskaber, den funktionalitet, som de forskellige strukturer giver.
"Det er formentlig den første sådan kompilering af en database i så massiv en skala, med 5, 380 like-for-like-par af eksperimentelle og beregnede data, " siger Cole. "Og fordi det er så stort et beløb, det fungerer som et depot i sig selv og åbner virkelig døren til at forudsige nye materialer."
Mange nye, store databaser er udelukkende bygget på beregninger, en iboende ulempe er, at de ikke valideres af eksperimentelle data. Det sidste, måske det vigtigste, giver et nøjagtigt billede af materialets ophidsede tilstande, som definerer elektronernes dynamiske tilstand og bruges til at beregne et materiales funktionelle egenskaber - optiske egenskaber, I dette tilfælde.
Dette spirende katalog over ophidsede tilstande kan så hjælpe med at beregne egenskaberne af materialer, der endnu ikke er blevet udtænkt, yderligere udvidelse af databasen.
"Forestil dig, at man ønsker at opdage en ny type optisk materiale, der passer til en skræddersyet funktionel applikation, og vores database indeholder ikke den særlige optiske egenskab, " forklarer Cole. "Vi beregner den optiske egenskab af interesse fra de ophidsede stater, der er tilgængelige for hver ejendom i vores database, og skab et materiale med skræddersyede funktioner."
Holdet udførte kvantekemiske beregninger på hver struktur, for hvilken de havde udtrukket data om optiske materialer, ved at bruge ALCF's Theta supercomputer, dermed skabe databasen af parrede eksperimentelle og beregnede strukturer og deres optiske egenskaber.
"En af de største udfordringer var at udvinde kemiske kandidater, der kunne tjene som farvestoffer til solceller fra 400, 000 videnskabelige artikler, " siger Álvaro Vázquez-Mayagoitia, en computational scientist i Argonnes Computational Science division. "Vi udviklede en distribueret ramme til at anvende kunstig intelligens metoder, såsom dem, der bruges i naturlig sprogbehandling, på ALCF's supercomputere i verdensklasse."
For automatisk at udtrække disse oplysninger og deponere dem i databasen, holdet henvendte sig til den nye datamining-applikation kaldet ChemDataExtractor. Et NLP-værktøj, det blev designet til at mine tekst specifikt fra kemi- og materialelitteratur, hvor, Cole siger, "informationen er spredt ud over mange tusinde papirer og er til stede i stærkt fragmenterede og ustrukturerede former."
Ikke én til manuel artikelsøgning, Cole beskriver drivkraften til at udvikle applikationen som innovation fra frustration. I første omgang, hun prøvede mere generiske NLP-pakker, men bemærkede, at "de fejler ikke bare, de fejler spektakulært."
Problemet ligger i oversættelsen, ikke så meget fra en menneskelig sprogholdning, men fra videnskabens sprog, selvom der er nogle ligheder.
En forfatter, for eksempel, kan bruge et talegenkendelsesprogram, en form for NLP, at transskribere noter eller interviews. Programmet træner hovedsageligt på forfatterens stemme, opfange mønstre og nuancer, og begynder at transskribere ret præcist. Indsæt nu et interview med et emne med en fremmed accent, og tingene begynder at blive skæve.
I Coles verden, fremmedsproget er videnskab, hvert domæne et andet land. I øjeblikket, du skal træne programmet på kun ét "sprog, "Sig kemi, og selv da, du skal lære at videnskabens særlige dialekter.
Uorganiske kemikere kan udgøre en formel ved hjælp af ukendte repræsentationer af de velkendte kemiske grundstofsymboler, hvorimod organiske kemikere foretrækker kemiske skitser nummereret i en illustrationsboks. Oplysningerne fra begge viser sig typisk at være for svære for de fleste mineprogrammer at udtrække.
"Og det er bare i en lille smule kemi, " bemærker Cole. "Fordi den måde folk beskriver ting på er så forskellig, mangfoldighed i domænespecificitet er absolut kritisk."
Til det formål, holdets database er en af ultraviolet-synlige (UV/vis) absorptionsspektrale attributter, som giver en åbent tilgængelig ressource for brugere, der søger at finde materialer med foretrukne spektrale farver.
Mens holdet bruger den nye database til at fjerne organiske farvestoffer, der kan erstatte traditionelle metal-organiske farvestoffer i solceller, de har allerede målrettet bredere fronter til brugen af det.
Nyttig som kilde til træningsdata til maskinlæringsmetoder, der forudsiger nye optiske materialer, det kan også bevise en simpel datahentningsmulighed for brugere af UV/vis absorptionsspektroskopi, et værktøj, der er meget brugt på tværs af forskningslaboratorier rundt om i verden som en kerneteknik til at karakterisere nye materialer.
"Protokollerne brugt i dette projekt er allerede ved at blive implementeret til lignende typer projekter, " tilføjer Vázquez-Mayagoitia. "F.eks. holdet har for nylig udnyttet ChemDataExtractor og ALCF computerressourcer til at producere ekspansive databaser med potentielle batterikemikalier, og magnetiske og superledende forbindelser."
Den optiske materialedatabaseforskning vises i artiklen "Comparative dataset of experimental and computational attributes of UV/vis absorption spectra" i Scientific Data. Yderligere forfattere omfatter Edward J. Beard fra University of Cambridge, og Ganesh Sivaraman og Venkatram Vishwanath fra Argonne National Laboratory.
Et papir, der beskriver deres arbejde med magnetiske og superledende materialer, er blevet offentliggjort i npj Beregningsmaterialer . Batterimaterialedatabasen, der indeholder over 290, 000 dataposter er blevet offentliggjort i Videnskabelige data .
 Varme artikler
Varme artikler
-
 Opdeling af vand til prisen for et nikkelEt elektronmikroskopbillede af en nikkelanode (til højre), der øger ilt-udviklingsreaktionen, der er vigtig for vandspaltning (til venstre). Kredit:KAUST En teknik til at skabe et materiale til om
Opdeling af vand til prisen for et nikkelEt elektronmikroskopbillede af en nikkelanode (til højre), der øger ilt-udviklingsreaktionen, der er vigtig for vandspaltning (til venstre). Kredit:KAUST En teknik til at skabe et materiale til om -
 Et forsøg foreslået af en ph.d. elev kan omskrive kemi lærebøgerSolvatiserede elektroner (grønne) i hullerne mellem ammoniakmolekyler (blå og hvide) begynder at smelte sammen til et par, efterhånden som en opløsning bevæger sig mod at blive metallisk. Kredit:Ryan
Et forsøg foreslået af en ph.d. elev kan omskrive kemi lærebøgerSolvatiserede elektroner (grønne) i hullerne mellem ammoniakmolekyler (blå og hvide) begynder at smelte sammen til et par, efterhånden som en opløsning bevæger sig mod at blive metallisk. Kredit:Ryan -
 Udvikling af fibrilleret cellulose som et bæredygtigt teknologisk materialeKredit:Dr.Hua Xie for University of Maryland, College Park Nanocellulose beklæder planters cellevægge, træer, alger og bakterier bestående af glukoseringe, der kæder sammen som en kæde og giver de
Udvikling af fibrilleret cellulose som et bæredygtigt teknologisk materialeKredit:Dr.Hua Xie for University of Maryland, College Park Nanocellulose beklæder planters cellevægge, træer, alger og bakterier bestående af glukoseringe, der kæder sammen som en kæde og giver de -
 Gennemsigtig keramisk rustning giver overlegen ballistisk beskyttelse over traditionelle glaslaminat…Army UH-60M helikopterplatforme bruger gennemsigtige rustningssystemer monteret bag piloterne. Kredit:Air Force Office of Scientific Research Gennemsigtig aluminium, en teknologi, der først blev f
Gennemsigtig keramisk rustning giver overlegen ballistisk beskyttelse over traditionelle glaslaminat…Army UH-60M helikopterplatforme bruger gennemsigtige rustningssystemer monteret bag piloterne. Kredit:Air Force Office of Scientific Research Gennemsigtig aluminium, en teknologi, der først blev f
- NASA tester Webb-teleskopernes kommunikationsevner
- Skinnende fiskeskind inspirerer til lysreflektorer i nanoskala
- Lasere oplyser neutrongenerering til radiografi
- Krokodiller og fugle var forhistoriske sengekammerater
- Oversvømmelser lukker lufthavnen i det indiske turisthotspot i Kerala
- Grafen er nøglen til at låse op for skabelsen af bærbare elektroniske enheder