


AI lokaliserer lokale forureningshotspots ved hjælp af satellitbilleder

En ny AI-algoritme valgte disse satellitbilleder i byblokstørrelse som lokale hotspots (øverst) og kølige steder (nederst) for luftforurening i Beijing. Kredit:Tongshu Zheng, Duke University
Forskere ved Duke University har udviklet en metode, der bruger maskinlæring, satellitbilleder og vejrdata til autonomt at finde hotspots med kraftig luftforurening, byblok for byblok.
Teknikken kan være en velsignelse for at finde og afbøde kilder til farlige aerosoler, at studere virkningerne af luftforurening på menneskers sundhed, og gøre bedre informeret, socialt retfærdige offentlige politiske beslutninger.
"Før nu, forskere, der forsøger at måle fordelingen af luftforurenende stoffer i en by, ville enten prøve at bruge det begrænsede antal eksisterende monitorer eller køre sensorer rundt i en by i køretøjer, " sagde Mike Bergin, professor i civil- og miljøteknik ved Duke. "Men opsætning af sensornetværk er tidskrævende og dyrt, og det eneste, at køre en sensor rundt virkelig fortæller dig, er, at vejene er store kilder til forurenende stoffer. At kunne finde lokale hotspots af luftforurening ved hjælp af satellitbilleder er enormt fordelagtigt."
De specifikke luftforurenende stoffer, som Bergin og hans kolleger er interesserede i, er små luftbårne partikler kaldet PM2.5. Disse er partikler, der har en diameter på mindre end 2,5 mikrometer - omkring tre procent af diameteren af et menneskehår - og har vist sig at have en dramatisk effekt på menneskers sundhed på grund af deres evne til at rejse dybt ned i lungerne.
Global Burden of Disease-undersøgelsen rangerede PM2.5 på femtepladsen på sin liste over dødelighedsrisikofaktorer i 2015. Undersøgelsen viste, at PM2.5 på et år var ansvarlig for omkring 4,2 millioner dødsfald og 103,1 millioner leveår mistet eller levet med handicap. En nylig undersøgelse fra Harvard University T.H. Chan School of Public Health fandt også, at områder med højere PM2.5-niveauer er forbundet med højere dødsrater på grund af COVID-19.
Men Harvard-forskerne kunne kun få adgang til PM2.5-data på amt-for-amt-niveau i USA. Selvom det er et værdifuldt udgangspunkt, Forureningsstatistikker på amtsniveau kan ikke bore ned til et kvarter ved siden af et kulfyret kraftværk i forhold til et ved siden af en park, der er 30 miles op mod vinden. Og de fleste lande uden for den vestlige verden har ikke det niveau af luftkvalitetsovervågning.
"Jordstationer er dyre at bygge og vedligeholde, så selv store byer vil sandsynligvis ikke have mere end en håndfuld af dem, " sagde Bergin. "Så selvom de måske giver en generel idé om mængden af PM2,5 i luften, de kommer ikke i nærheden af at give en sand fordeling for de mennesker, der bor i forskellige områder i den by."
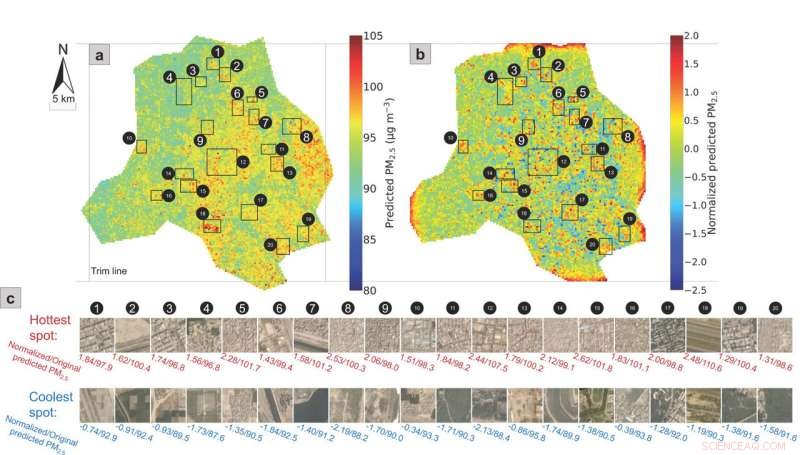
Den nye AI-algoritme udvalgte flere luftforureningshotspots og kølige steder i Delhi. Kredit:Duke University School of Nursing
I tidligere arbejde med ph.d.-studerende Tongshu Zheng og kollega David Carlson, assisterende professor i civil- og miljøteknik ved Duke, forskerne viste, at satellitbilleder, vejrdata og maskinlæring kunne give PM2.5-målinger i lille skala.
At bygge videre på det arbejde og fokusere på Beijing, holdet har nu forbedret deres metoder og lært algoritmen til automatisk at finde hotspots og kølige steder med luftforurening med en opløsning på 300 meter - omtrent på længden af en New York City-blok.
Fremgangen skete ved at bruge en teknik kaldet residual learning. Algoritmen estimerer først niveauerne af PM2.5 alene ved hjælp af vejrdata. Den måler derefter forskellen mellem disse estimater og de faktiske niveauer af PM2.5 og lærer sig selv at bruge satellitbilleder til at gøre sine forudsigelser bedre.
"Når forudsigelser først laves med vejret, og så tilføjes satellitdata senere for at finjustere dem, det gør det muligt for algoritmen at drage fuld fordel af informationen i satellitbilleder, " sagde Zheng.
Forskerne brugte derefter en algoritme, der oprindeligt var designet til at justere ujævn belysning i et billede for at finde områder med høje og lave niveauer af luftforurening. Kaldes lokal kontrast normalisering, Teknikken leder i det væsentlige efter pixels i byblokstørrelse, der har højere eller lavere niveauer af PM2.5 end andre i deres nærhed.
"Disse hotspots er notorisk svære at finde på kort over PM-niveauer, fordi nogle dage er luften bare rigtig dårlig i hele byen, og det er virkelig svært at sige, om der er sande forskelle mellem dem, eller om der bare er et problem med billedkontrasten, " sagde Carlson. "Det er en stor fordel at være i stand til at finde et specifikt kvarter, der har tendens til at forblive højere eller lavere end alle andre steder, fordi det kan hjælpe os med at besvare spørgsmål om sundhedsforskelle og miljømæssig retfærdighed."
Mens de nøjagtige metoder, algoritmen lærer sig selv, ikke kan overføres fra by til by, algoritmen kunne nemt lære sig selv nye metoder forskellige steder. Og mens byer kan udvikle sig over tid i både vejr- og forureningsmønstre, algoritmen burde ikke have nogen problemer med at udvikle sig med dem. Plus, forskerne påpeger, antallet af luftkvalitetssensorer vil kun stige i de kommende år, så de tror på, at deres tilgang kun bliver bedre med tiden.
"Jeg tror, vi vil være i stand til at finde byggede miljøer i disse billeder, der er relateret til de varme og kølige steder, som kan have en enorm miljøretfærdighedskomponent, " sagde Bergin. "Det næste skridt er at se, hvordan disse hotspots er relateret til socioøkonomisk status og hospitalsindlæggelsesrater fra langtidseksponeringer. Jeg tror, at denne tilgang kan bringe os rigtig langt, og de potentielle applikationer er bare fantastiske."
Resultaterne blev vist online 1. april i tidsskriftet Fjernmåling .
 Varme artikler
Varme artikler
-
 Mod en mere omfattende forståelse af ariditetsændringer over globale tørområderFigur 1:Fremtidige tørhedsændringer af atmosfærisk, økohydrologisk, og socioøkonomiske systemer over tørre områder. Kredit:Peking University Globale tørområder oplever en hurtigere opvarmning end
Mod en mere omfattende forståelse af ariditetsændringer over globale tørområderFigur 1:Fremtidige tørhedsændringer af atmosfærisk, økohydrologisk, og socioøkonomiske systemer over tørre områder. Kredit:Peking University Globale tørområder oplever en hurtigere opvarmning end -
 Emissioner af flere ozonnedbrydende kemikalier er større end forventetKredit:CC0 Public Domain I 2016, forskere ved MIT og andre steder observerede de første tegn på helbredelse i det antarktiske ozonlag. Denne miljømæssige milepæl var resultatet af årtiers samordne
Emissioner af flere ozonnedbrydende kemikalier er større end forventetKredit:CC0 Public Domain I 2016, forskere ved MIT og andre steder observerede de første tegn på helbredelse i det antarktiske ozonlag. Denne miljømæssige milepæl var resultatet af årtiers samordne -
 Hvad Jordens klimasystem og topologiske isolatorer har til fællesNy forskning viser, at ækvatorialbølger - impulser af varmt havvand, der spiller en rolle i reguleringen af Jordens klima - er drevet af den samme dynamik som de eksotiske materialer kendt som topol
Hvad Jordens klimasystem og topologiske isolatorer har til fællesNy forskning viser, at ækvatorialbølger - impulser af varmt havvand, der spiller en rolle i reguleringen af Jordens klima - er drevet af den samme dynamik som de eksotiske materialer kendt som topol -
 Hvordan man bekæmper klimaændringer i landbruget og samtidig beskytter arbejdspladserLandbruget er en unik sektor for en retfærdig omstilling. Kredit:Shutterstock Landbrug er blevet en kulstofintensiv bestræbelse. Afgrøde, brugen af husdyr og fossile brændstoffer i landbruget te
Hvordan man bekæmper klimaændringer i landbruget og samtidig beskytter arbejdspladserLandbruget er en unik sektor for en retfærdig omstilling. Kredit:Shutterstock Landbrug er blevet en kulstofintensiv bestræbelse. Afgrøde, brugen af husdyr og fossile brændstoffer i landbruget te
- Sådan bestemmes kogepunkter med tryk <p> <p> "En overvåget gryde koger aldrig" kan virke som den u…
- Plasma fra lasere kan kaste lys over kosmiske stråler, soludbrud
- Beskyttelse af væsentlige forbindelser i en sammenfiltret bane
- Fire grundlæggende bevægelsestyper
- Chrome til Windows med ARM-smag er velsmagende indsats for Microsoft, Google, Qualcomm
- De fleste bærbare computere, der er sårbare over for angreb via perifere enheder, siger forskere