


Er dit maskinlæringstræningssæt forudindtaget? Hvordan man udvikler nye lægemidler baseret på fusionerede datasæt
Maskinlæringsalgoritmer er kun så gode som de data, de er trænet på. Hvis træningssættet er skævt, så vil algoritmen også være skævt. Dette kan føre til unøjagtige forudsigelser og uretfærdige beslutninger.
Der er en række måder, hvorpå et maskinlæringstræningssæt kan blive forudindtaget. Nogle af de mest almindelige årsager omfatter:
* Sampling bias: Dette sker, når træningssættet ikke er repræsentativt for den population, det er trukket fra. For eksempel, hvis du træner en maskinlæringsalgoritme til at forudsige en persons køn, men dit træningssæt kun indeholder data om mænd, så vil algoritmen være forudindtaget i forhold til at forudsige, at folk er mænd.
* Udvalgsbias: Dette sker, når træningssættet ikke er valgt tilfældigt. For eksempel, hvis du træner en maskinlæringsalgoritme til at forudsige en studerendes succes, men du kun inkluderer data om studerende, der allerede er færdiguddannede fra college, så vil algoritmen være forudindtaget i forhold til at forudsige, at eleverne vil få succes.
* Målingsbias: Dette sker, når dataene i træningssættet ikke er nøjagtige eller fuldstændige. For eksempel, hvis du træner en maskinlæringsalgoritme til at forudsige risikoen for, at en patient udvikler en sygdom, men dataene i træningssættet mangler information om patientens livsstil, så vil algoritmen være forudindtaget i forhold til at forudsige, at patienterne er på lavt niveau. risiko.
Det er vigtigt at være opmærksom på potentialet for bias i maskinlæringstræningssæt og at tage skridt til at afbøde denne risiko. Nogle af de ting, du kan gøre for at reducere bias, omfatter:
* Brug et varieret træningssæt: Sørg for, at træningssættet indeholder data fra en række forskellige kilder, og at det er repræsentativt for den befolkning, det er trukket fra.
* Vælg træningssættet tilfældigt: Sørg for, at træningssættet er valgt tilfældigt, så alle datapunkter har lige stor chance for at blive inkluderet.
* Rens og bekræft dataene: Sørg for, at dataene i træningssættet er nøjagtige og fuldstændige.
Ved at følge disse trin kan du være med til at sikre, at dine maskinlæringsalgoritmer ikke er forudindtaget, og at de producerer nøjagtige og retfærdige forudsigelser.
Sådan udvikles nye lægemidler baseret på sammenlagte datasæt
Sammenlægning af datasæt fra forskellige kilder kan være en effektiv måde at udvikle nye lægemidler på. Ved at kombinere data fra forskellige undersøgelser kan forskere identificere nye mønstre og relationer, der kan føre til ny indsigt og opdagelser.
Der er dog en række udfordringer forbundet med sammenlægning af datasæt. Disse udfordringer omfatter:
* Data heterogenitet: Dataene i forskellige datasæt kan indsamles på forskellige måder ved hjælp af forskellige metoder og instrumenter. Dette kan gøre det vanskeligt at flette dataene og sikre, at de er konsistente og nøjagtige.
* Datakvalitet: Kvaliteten af dataene i forskellige datasæt kan variere. Dette kan gøre det vanskeligt at identificere og rette fejl og uoverensstemmelser.
* Databeskyttelse: Dataene i forskellige datasæt kan være underlagt forskellige privatlivsbestemmelser. Dette kan gøre det vanskeligt at dele og flette dataene uden at overtræde disse regler.
På trods af disse udfordringer kan sammenlægning af datasæt være et værdifuldt værktøj til lægemiddeludvikling. Ved omhyggeligt at tage fat på udfordringerne forbundet med datasammensmeltning kan forskere frigøre potentialet i denne kraftfulde teknik og fremskynde udviklingen af nye lægemidler.
Her er nogle tips til udvikling af nye lægemidler baseret på fusionerede datasæt:
* Start med et klart mål. Hvad håber du at opnå ved at slå datasættene sammen? Dette vil hjælpe dig med at identificere de mest relevante data og til at designe en undersøgelse, der vil give de mest brugbare resultater.
* Vælg de rigtige datasæt. De datasæt, du vælger at flette, skal være relevante for dit forskningsspørgsmål og skal være af høj kvalitet. Du bør også overveje dataheterogenitet og databeskyttelsesproblemer, der kan være forbundet med datasættene.
* Rens og klargør dataene. Før du kan flette datasættene, skal du rense og forberede dataene. Dette omfatter fjernelse af fejl, uoverensstemmelser og afvigelser. Du skal muligvis også transformere dataene, så de er i et ensartet format.
* Flet datasættene. Når dataene er rene og forberedte, kan du flette datasættene. Der er en række forskellige måder at flette datasæt på, så du bør vælge den metode, der passer bedst til dit forskningsspørgsmål.
* Analyser dataene. Når datasættene er flettet, kan du analysere dataene for at identificere nye mønstre og relationer. Dette kan involvere brug af statistiske metoder, maskinlæringsalgoritmer eller andre dataanalyseteknikker.
* Fortolk resultaterne. Det sidste trin er at fortolke resultaterne af din dataanalyse. Dette indebærer at drage konklusioner fra dataene og identificere potentielle implikationer for lægemiddeludvikling.
Ved at følge disse tips kan du øge dine chancer for succes med at udvikle nye lægemidler baseret på fusionerede datasæt.
 Varme artikler
Varme artikler
-
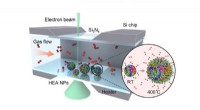 Bedre sammen:Forskere opdager anvendelser af nanopartikler med flere elementerSkematisk af opsætningen brugt til at studere oxidationen af højentropi legering nanopartikler (HEA NP). Indsat viser HEA NP-struktur ved stuetemperatur (RT) og under højtemperaturoxidation. Kredit:
Bedre sammen:Forskere opdager anvendelser af nanopartikler med flere elementerSkematisk af opsætningen brugt til at studere oxidationen af højentropi legering nanopartikler (HEA NP). Indsat viser HEA NP-struktur ved stuetemperatur (RT) og under højtemperaturoxidation. Kredit: -
 Nanopartikler og immunsystemetKredit:Shutterstock (Phys.org) —Nanoteknologi er sådan en ny innovation, at ingen rigtig er sikre på, hvad der kommer ud af det. Forudsigelser spænder fra evnen til at gengive ting som diamanter o
Nanopartikler og immunsystemetKredit:Shutterstock (Phys.org) —Nanoteknologi er sådan en ny innovation, at ingen rigtig er sikre på, hvad der kommer ud af det. Forudsigelser spænder fra evnen til at gengive ting som diamanter o -
 Guld nanopartikler til behandling af kræftGuld nanopartikler absorberer høje niveauer af ioniserende stråling, øge virkningen af strålebehandlinger, der virker ved at beskadige DNA i tumorceller. Et nyt projekt ved National Physical Lab
Guld nanopartikler til behandling af kræftGuld nanopartikler absorberer høje niveauer af ioniserende stråling, øge virkningen af strålebehandlinger, der virker ved at beskadige DNA i tumorceller. Et nyt projekt ved National Physical Lab -
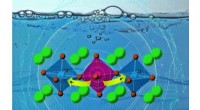 Kontrol af tynde film med atomisk spraymalingHøjpræcisionssyntese og målinger af tynde oxidfilm hjalp forskerne med at bestemme, hvordan jern påvirker den måde, materialet fungerer på, for eksempel i dets evne til at omdanne vand til ilt i en br
Kontrol af tynde film med atomisk spraymalingHøjpræcisionssyntese og målinger af tynde oxidfilm hjalp forskerne med at bestemme, hvordan jern påvirker den måde, materialet fungerer på, for eksempel i dets evne til at omdanne vand til ilt i en br
- Mål spiller til styrke, kombinere digitalt salg og butikker
- Store energibesparelser for små maskiner
- Forskere identificerer en kombination af faktorer for økologisk kakaoudbytte
- Nye 2-D kvantematerialer til nanoelektronik
- Australske minegiganter støtter netto-mål
- Regn giver en let udsættelse fra den største naturbrand i Texas' historie