


AlphaZero AI-system i stand til at lære sig selv at spille spil, spille på højeste niveau

Startende fra tilfældigt spil og uden domæneviden undtagen spillereglerne, AlphaZero besejrede overbevisende et verdensmesterprogram i spillene skak og shogi (japansk skak) samt Go. Kredit:DeepMind Technologies Ltd
Et team af forskere med DeepMind-gruppen og University College, både i U.K., har udviklet et AI-system, der er i stand til at lære sig selv at spille og mestre tre svære brætspil. I deres papir offentliggjort i tidsskriftet Videnskab , gruppen beskriver deres nye system og forklarer, hvorfor de mener, at det repræsenterer endnu et stort skridt fremad i udviklingen af AI-systemer. Murray Campbell med T.J Watson Research Center i USA tilbyder et perspektiv på arbejdet udført af teamet i samme tidsskriftsudgave.
Det er over 20 år siden, at en supercomputer kendt som Deep Blue slog verdensskakmesteren Gary Kasparov, viser verden, hvor langt AI computing var kommet. I årene siden, computere er blevet stadig smartere og slår nu mennesker i spil som skak, shogi og Go. Men sådanne systemer er alle blevet tweaket for at gøre dem rigtig gode til kun ét spil. I denne nye indsats, forskerne har skabt et AI-system, der ikke kun er godt til mere end ét spil, men får en sådan ekspertise på egen hånd.
Det nye system, kaldet AlphaZero, er et forstærkende læringssystem, hvilken, som navnet antyder, betyder, at det lærer ved gentagne gange at spille et spil og lære af dets erfaringer. Dette er, selvfølgelig, meget lig, hvordan mennesker lærer. Et grundlæggende sæt regler er fastlagt, og derefter spiller computeren spillet - med sig selv. Det behøver ikke engang at spille med andre partnere. Det spiller sig selv gentagne gange, at bemærke, hvilke spil der udgør gode træk og dermed vinde, og som udgør dårlige træk og tab. Over tid, det forbedres. Til sidst, det bliver så godt, at det ikke kun kan slå mennesker, men andre dedikerede brætspil AI-systemer. Systemet brugte også en søgemetode kendt som Monte Carlo træsøgning. Ved at kombinere de to teknologier kan systemet lære sig selv at blive bedre til at spille. Forskerne gav deres testsystem en masse kraft, såvel, ved at ansætte 5000 tensorbehandlingsenheder, hvilket sætter den på niveau med store supercomputere.
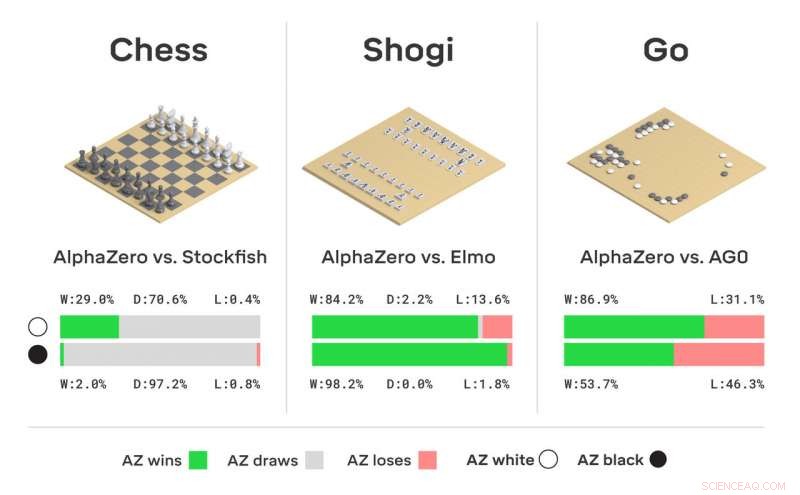
Turneringsevaluering af AlphaZero i skak, shogi, og gå, som spil vundet, tegnet eller tabt fra AlphaZeros perspektiv, i kampe mod Stockfish, Elmo, og AlphaGo Zero (AG0), der blev trænet i tre dage. Kredit:DeepMind Technologies Ltd
Så langt, AlphaZero har mestret skak, shogi og Go - spil, der er særligt velegnede til AI-applikationer. Campbell foreslår, at det næste skridt for sådanne systemer kan være at forgrene sig til spil som poker, eller endda populære videospil.
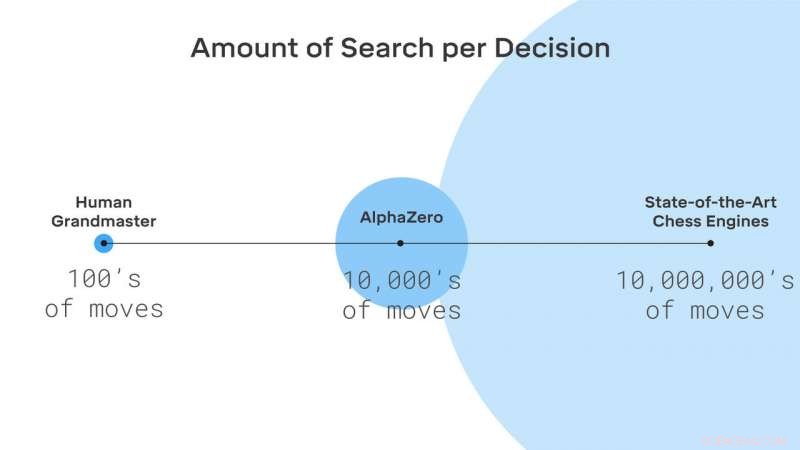
AlphaZero søger kun en lille brøkdel af de positioner, som traditionelle skakmotorer betragter. Kredit:DeepMind Technologies Ltd
© 2018 Science X Network
 Varme artikler
Varme artikler
-
 Russisk vagthund indleder administrative procedurer mod Facebook, TwitterStatens tilsynsmyndighed har gentagne gange advaret Facebook og Twitter om, at de kan blive forbudt, hvis de ikke overholder en lov fra 2014 Ruslands medievagthund Roskomnadzor indledte administra
Russisk vagthund indleder administrative procedurer mod Facebook, TwitterStatens tilsynsmyndighed har gentagne gange advaret Facebook og Twitter om, at de kan blive forbudt, hvis de ikke overholder en lov fra 2014 Ruslands medievagthund Roskomnadzor indledte administra -
 Vil du slukke for internettet? Det kan ske, hvis en solstorm rammer JordenRøntgenstråler strømmer ud af solen i dette billede, der viser observationer fra NASAs Nuclear Spectroscopic Telescope Array, eller NuSTAR, overlejret på et billede taget af NASAs Solar Dynamics Obser
Vil du slukke for internettet? Det kan ske, hvis en solstorm rammer JordenRøntgenstråler strømmer ud af solen i dette billede, der viser observationer fra NASAs Nuclear Spectroscopic Telescope Array, eller NuSTAR, overlejret på et billede taget af NASAs Solar Dynamics Obser -
 Bayer bekræfter prognoserne, efterhånden som Monsanto-integrationen skrider fremDen tyske kemikalie- og medicinalgigant Bayer bekræftede sine helårsprognoser efter en solid præstation i firmaets første hele kvartal med integration af amerikanske frø- og pesticidproducent Monsanto
Bayer bekræfter prognoserne, efterhånden som Monsanto-integrationen skrider fremDen tyske kemikalie- og medicinalgigant Bayer bekræftede sine helårsprognoser efter en solid præstation i firmaets første hele kvartal med integration af amerikanske frø- og pesticidproducent Monsanto -
 Britisk farm går ind i ny teknologi med 5G-halsbånd på køerPå dette billede taget i onsdags, 28. august, 2019, projektleder Duncan Forbes holder en smartphone, der viser biometriske data om sine køer i Agri-EPI Centre, et mejeriudviklingscenter i Shepton Mall
Britisk farm går ind i ny teknologi med 5G-halsbånd på køerPå dette billede taget i onsdags, 28. august, 2019, projektleder Duncan Forbes holder en smartphone, der viser biometriske data om sine køer i Agri-EPI Centre, et mejeriudviklingscenter i Shepton Mall
- Quibi håber, at quick bite-tv til smartphones vinder seerne
- Kæmpe uddød gravende flagermus opdaget i New Zealand
- Hvorfor orkaner ødelægger nogle steder igen og igen:En meteorolog forklarer
- Hydrauliske System Ulemper
- At gå videre med standardiserede test kan forårsage flere problemer, end det løser
- Hvad er levetiden på hudceller?