


En ny tilgang til uovervåget omskrivning uden oversættelse
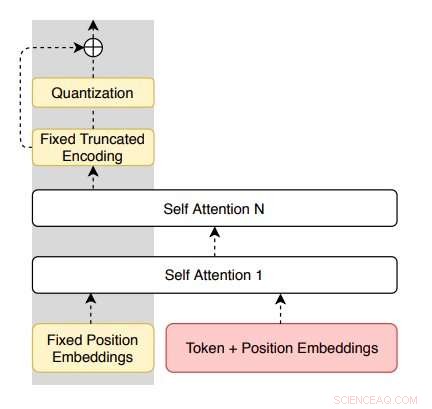
Arkitektur af encoder foreslået af forskerne. Kredit:Roy &Grangier.
I de seneste år, forskere har forsøgt at udvikle metoder til automatisk omskrivning, hvilket i det væsentlige indebærer den automatiserede abstraktion af semantisk indhold fra tekst. Indtil nu, tilgange, der er afhængige af maskinoversættelsesteknikker (MT), har vist sig særligt populære på grund af manglen på tilgængelige mærkede datasæt for parafraserede par.
Teoretisk set oversættelsesteknikker kan virke som effektive løsninger til automatisk omskrivning, da de abstraherer semantisk indhold fra dets sproglige erkendelse. For eksempel, tildeling af den samme sætning til forskellige oversættere kan resultere i forskellige oversættelser og et rigt sæt fortolkninger, hvilket kan være nyttigt ved omskrivning af opgaver.
Selvom mange forskere har udviklet oversættelsesbaserede metoder til automatiseret omskrivning, mennesker behøver ikke nødvendigvis at være tosprogede for at omskrive sætninger. Baseret på denne observation, to forskere ved Google Research har for nylig foreslået en ny parafraseringsteknik, der ikke er afhængig af maskinoversættelsesmetoder. I deres papir, forududgivet på arXiv, de sammenlignede deres ensprogede tilgang med andre teknikker til parafrasering:en overvåget oversættelse og en uovervåget oversættelsesmetode.
"Dette arbejde foreslår kun at lære parafrasering af modeller fra et umærket ensproget korpus, "Aurko Roy og David Grangier, de to forskere, der gennemførte undersøgelsen, skrev i deres papir. "Til det formål, vi foreslår en restvariant af vektor-kvantiseret variation-auto-encoder. "
Den model, som forskerne introducerede, er baseret på vektorkvantiserede auto-encodere (VQ-VAE), der kan omformulere sætninger i en rent ensproget indstilling. Det har også en unik egenskab (dvs. resterende forbindelser parallelt med den kvantiserede flaskehals), hvilket muliggør bedre kontrol over dekoderentropien og letter optimeringen.
"Sammenlignet med kontinuerlige auto-encodere, vores metode tillader generation af forskellige, men semantisk lukke sætninger fra en indgangssætning, "forklarede forskerne i deres papir.
I deres undersøgelse, Roy og Grangier sammenlignede deres models ydeevne med andre MT-baserede metoder til parafrasidentifikation, generation og uddannelsesforøgelse. De sammenlignede det specifikt med en overvåget oversættelsesmetode, der er uddannet i parallelle tosprogede data og en uovervåget oversættelsesmetode, der er uddannet i ikke-parallel tekst på to forskellige sprog. Deres model, på den anden side, kræver kun umærkede data på et enkelt sprog, den, den omskriver sætninger i.
Forskerne fandt ud af, at deres ensprogede tilgang overgik oversættelsesteknikker uden opsyn i alle opgaver. Sammenligninger mellem deres model og overvågede oversættelsesmetoder, på den anden side, gav blandede resultater:den ensprogede tilgang klarede sig bedre i identifikations- og forstørrelsesopgaver, mens den overvågede oversættelsesmetode var overlegen til omskrivning af generationer.
"Samlet set, vi viste, at ensprogede modeller kan udkonkurrere tosprogede modeller til parafrasidentifikation og dataforøgelse gennem parafrasering, "konkluderede forskerne." Vi rapporterede også, at generationskvalitet fra ensprogede modeller kan være højere end modeller baseret på oversættelse uden opsyn, men ikke oversat oversættelse. "
Roy og Grangiers resultater tyder på, at brug af tosprogede parallelle data (dvs. tekster og deres mulige oversættelser til andre sprog) er særlig fordelagtig, når der genereres omskrivninger og fører til bemærkelsesværdig præstation. I situationer, hvor tosprogede data ikke er let tilgængelige, imidlertid, den ensprogede model, de foreslår, kan være en nyttig ressource eller alternativ løsning.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Maryland-lovforslaget søger gennemsigtighed i politiske onlineannoncerI denne lørdag, 7. april, 2018 foto, Maryland Del. Alonzo Washington, D-Prince George County, der sponsorerede lovgivning i Maryland for at øge gennemsigtigheden i online politiske annoncer, sidder på
Maryland-lovforslaget søger gennemsigtighed i politiske onlineannoncerI denne lørdag, 7. april, 2018 foto, Maryland Del. Alonzo Washington, D-Prince George County, der sponsorerede lovgivning i Maryland for at øge gennemsigtigheden i online politiske annoncer, sidder på -
 Brug af fotoplethysmografisignal til matematisk modellering af arterielt blodtrykTidsdiagram over protokoller (NB:Normal vejrtrækning, BH:Hold vejret). Kredit:Soltan zadi et al. Et team af forskere ved University of Texas i Arlington og University of Texas Southwestern har for
Brug af fotoplethysmografisignal til matematisk modellering af arterielt blodtrykTidsdiagram over protokoller (NB:Normal vejrtrækning, BH:Hold vejret). Kredit:Soltan zadi et al. Et team af forskere ved University of Texas i Arlington og University of Texas Southwestern har for -
 Sammenfoldelige krige? Ny patentansøgning tyder på, at Apple er ved at klargøre en foldbar iPhoneEn tegning fra Apples fleksible designpatent viser en enhed bøjet som en pyramide. Det er ekstremt usandsynligt, at du snart vil se en foldbar iPhone, meget mindre i september, hvor Apple sandsynl
Sammenfoldelige krige? Ny patentansøgning tyder på, at Apple er ved at klargøre en foldbar iPhoneEn tegning fra Apples fleksible designpatent viser en enhed bøjet som en pyramide. Det er ekstremt usandsynligt, at du snart vil se en foldbar iPhone, meget mindre i september, hvor Apple sandsynl -
 Er Zuckerberg villig til at handle modigt for at rette op på Facebook-krisen?Denne 5. feb. Filfoto fra 2007 viser Facebooks grundlægger Mark Zuckerberg ved Facebooks hovedkvarter i Palo Alto, Californien Zuckerbergs drengeagtige udseende, selv i dag, er en påmindelse om, hvor
Er Zuckerberg villig til at handle modigt for at rette op på Facebook-krisen?Denne 5. feb. Filfoto fra 2007 viser Facebooks grundlægger Mark Zuckerberg ved Facebooks hovedkvarter i Palo Alto, Californien Zuckerbergs drengeagtige udseende, selv i dag, er en påmindelse om, hvor
- Hvordan man kan være sikker fra hajer i Ocean
- Hvor kan man se Irmas ankomst til Florida, mens det sker
- Projekter på sammensatte materialer
- Naturens murværk:De første trin i, hvordan tynde proteinplader danner polyedriske skaller
- Sved, blegemiddel og luftkvalitet i gymnastiksalen
- MOF co-katalysator tillader selektivitet af forgrenede aldehyder på op til 90 %