


Maskinlæringsassisteret molekylært design til højtydende organiske fotovoltaiske materialer
Brug af maskinlæring til at hjælpe molekylært design. Kredit:Wenbo Sun, Videnskabens fremskridt, doi:10.1126/sciadv.aay4275
At syntetisere højtydende materialer til organisk fotovoltaik (OPV'er), der omdanner solstråling til jævnstrøm, materialeforskere skal på en meningsfuld måde etablere forholdet mellem kemiske strukturer og deres fotovoltaiske egenskaber. I en ny undersøgelse vedr Videnskabens fremskridt , Wenbo Sun og et team med forskere fra School of Energy and Power Engineering, School of Automation, Computer videnskab, Elektroteknik og grøn og intelligent teknologi, etableret en ny database med mere end 1, 700 donormaterialer ved hjælp af eksisterende litteraturrapporter. De brugte overvåget læring med maskinlæringsmodeller til at opbygge struktur-egenskabsrelationer og hurtige OPV-materialer ved hjælp af en række input til forskellige ML-algoritmer.
Brug af molekylære fingeraftryk (som koder for en struktur af et molekyle i binære bits) ud over en længde på 1000 bit Sun et al. opnået høj ML-forudsigelsesnøjagtighed. De verificerede pålideligheden af tilgangen ved at screene 10 nydesignede donormaterialer for overensstemmelse mellem modelforudsigelser og eksperimentelle resultater. ML-resultaterne præsenterede et kraftfuldt værktøj til at forhåndsscreene nye OPV-materialer og accelerere udviklingen af OPV'er inden for materialeteknik.
Organiske fotovoltaiske (OPV) celler kan lette direkte og omkostningseffektiv omdannelse af solenergi til elektricitet med hurtig vækst for nylig, der overstiger strømkonverteringseffektiviteten (PCE). Mainstream OPV-forskning har fokuseret på at opbygge et forhold mellem nye OPV-molekylære strukturer og deres fotovoltaiske egenskaber. Den traditionelle proces involverer typisk design og syntese af fotovoltaiske materialer til montering/optimering af fotovoltaiske celler. Sådanne tilgange resulterer i tidskrævende forskningscyklusser, der kræver nænsom kontrol af kemisk syntese og fremstilling af udstyr, eksperimentelle trin og oprensning. Den eksisterende OPV-udviklingsproces er langsom og ineffektiv med mindre end 2000 OPV-donormolekyler syntetiseret og testet indtil videre. Imidlertid, data indsamlet fra årtiers forskningsarbejde er uvurderlige, med potentielle værdier, der skal udforskes fuldt ud for at generere højtydende OPV-materialer.
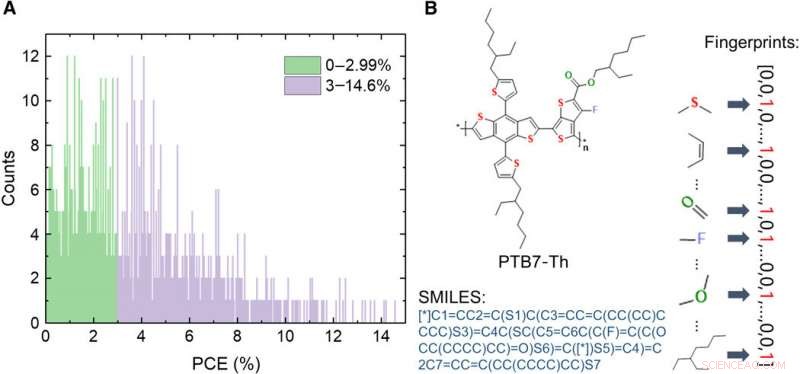
Oplysninger om databasen over OPV-donormaterialer. (A) Fordeling af PCE-værdier af de 1719 molekyler i databasen. (B) Skema af udtryk for et molekyle, inklusive billede, simplified molecular-input line-entry system (SMILES), og fingeraftryk. Kredit:Science Advances, doi:10.1126/sciadv.aay4275
For at udtrække nyttig information fra dataene, Sun et al. krævede et sofistikeret program til at scanne gennem et stort datasæt og udtrække relationer blandt funktionerne. Da maskinlæring (ML) giver beregningsværktøjer til at lære og genkende mønstre og relationer ved hjælp af et træningsdatasæt, holdet brugte en datadrevet tilgang til at aktivere ML og forudsige forskellige materialeegenskaber. ML-algoritmen behøvede ikke at forstå kemien eller fysikken bag materialeegenskaberne for at udføre opgaverne. Lignende metoder har for nylig forudsagt materialers aktivitet/egenskaber med succes under materialeopdagelse, lægemiddeludvikling og materialedesign. Før ML ansøgninger, videnskabsmænd havde genereret keminformatik for at etablere en nyttig værktøjskasse.
Materialeforskere har først for nylig udforsket anvendelserne af ML i OPV-området. I nærværende arbejde, Sun et al. etableret en database indeholdende 1719 eksperimentelt testede donor OPV-materialer indsamlet fra litteratur. De undersøgte vigtigheden af programmeringssprogsekspression af molekylerne først for at forstå ML-ydeevne. De testede derefter flere forskellige typer udtryk, herunder billeder, ASCII strenge, to typer deskriptorer og syv typer af molekylære fingeraftryk. De observerede, at modelforudsigelserne var i god overensstemmelse med de eksperimentelle resultater. Forskerne forventer, at den nye tilgang i høj grad vil fremskynde udviklingen af nye og højeffektive organiske halvledende materialer til OPV-forskningsapplikationer.
Forskerholdet transformerede først de rå data til en maskinlæsbar repræsentation. Der eksisterer en række udtryk for det samme molekyle, der omfatter vidt forskellig kemisk information præsenteret på forskellige abstrakte niveauer. Ved at bruge et sæt ML-modeller, Sun et al. udforsket forskellige udtryk for et molekyle ved at sammenligne deres forudsagte nøjagtighed for strømkonverteringseffektivitet (PCE) for at opnå en dyb-læringsmodelnøjagtighed på 69,41 procent. Den relativt utilfredsstillende ydeevne skyldtes databasens lille størrelse. For eksempel, tidligere, hvor den samme gruppe brugte et større antal molekyler på op til 50, 000, nøjagtigheden af deep-learning-modellen oversteg 90 procent. For fuldt ud at træne en dyb-læringsmodel, forskere skal implementere en større database, der indeholder millioner af prøver.
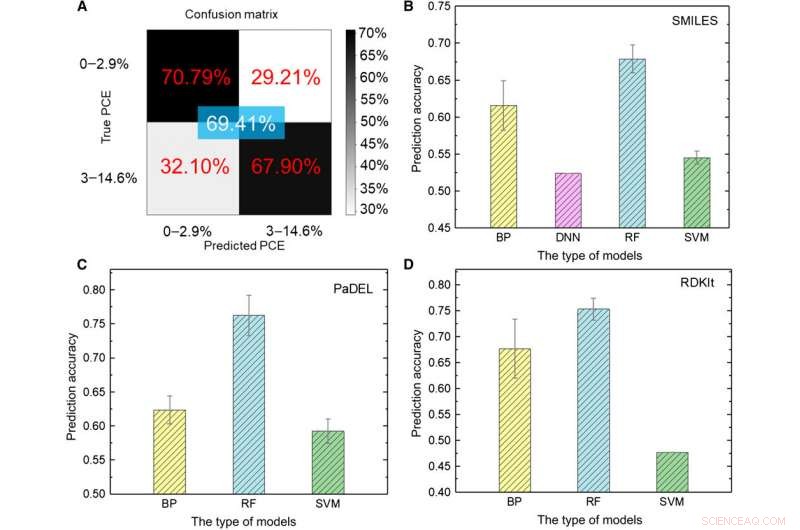
Testresultater af ML-modeller. (A) Test af deep learning-modellen ved hjælp af billeder som input. (B til D) Testresultater af forskellige ML-modeller ved hjælp af (B) SMILES, (C) PaDEL, og (D) RDKIt-deskriptorer som input. Kredit:Science Advances, doi:10.1126/sciadv.aay4275
Sun et al. kun havde hundredvis af molekyler i hver kategori på nuværende tidspunkt, gør det vanskeligt for modellen at udtrække nok information til højere nøjagtighed. Selvom det er muligt at finjustere en fortrænet model for at reducere mængden af data, der kræves, tusindvis af prøver er stadig nødvendige for at opnå et tilstrækkeligt antal funktioner. Dette førte til muligheden for at øge størrelsen af databasen, når billeder blev brugt til at udtrykke molekyler.
Forskerne brugte fem typer overvågede ML-algoritmer i undersøgelsen, inklusive (1) backpropagation (BP) neurale netværk (BPNN), (2) dybt neuralt netværk (DNN), (3) dyb læring, (4) støtte vektormaskine (SVM) og (5) tilfældig skov (RF). Disse var avancerede algoritmer, hvor BPNN, DNN og deep learning var baseret på det kunstige neutrale netværk (ANN). SMILES-koden (simplified molecular-input line entry system) gav et andet originalt udtryk for et molekyle, hvilket Sun et al. bruges som input til fire modeller. Baseret på resultaterne, den højeste nøjagtighed ca. 67,84 procent for RF-modellen. Som før, i modsætning til dyb læring, de fire klassiske metoder kunne ikke udtrække skjulte træk. Som en helhed, SMILES klarede sig dårligere end billeder som deskriptorer af molekyler til at forudsige PCE-klassen (power conversion efficiency) i dataene.
Forskerne brugte derefter molekylære deskriptorer, der kan beskrive et molekyles egenskaber ved hjælp af en række tal i stedet for det direkte udtryk for en kemisk struktur. Forskerholdet brugte to typer deskriptorer PaDEL og RDKIt i undersøgelsen. Efter omfattende analyser på tværs af alle ML-modeller, en stor datastørrelse indebar flere deskriptorer irrelevante for PCE, der påvirker ANN-ydelsen. Forholdsvis, en lille datastørrelse indebar ineffektiv kemisk information til effektivt at træne ML-modeller, når du bruger molekylære deskriptorer som input i ML-tilgange, nøglen var afhængig af at finde passende deskriptorer, der var direkte relateret til målobjektet.
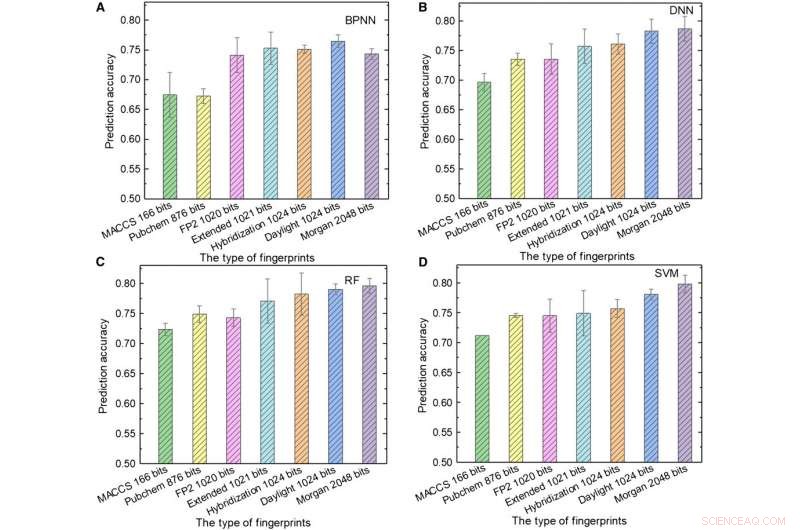
Ydelse af ML-modeller. (A til D) Testresultaterne af (A) BPNN, (B) DNN, (C) RF, og (D) SVM ved hjælp af forskellige typer fingeraftryk som input. Kredit:Science Advances, doi:10.1126/sciadv.aay4275.
Holdet brugte derefter molekylære fingeraftryk; typisk designet til at repræsentere molekyler som matematiske objekter og oprindeligt skabt til at identificere isomerer. Under storstilet databasescreening, konceptet er repræsenteret som et array af bits indeholdende "1" s og "0" s for at beskrive tilstedeværelsen eller fraværet af specifikke understrukturer eller mønstre i molekylerne. Sun et al. brugte syv typer fingeraftryk som input til at træne ML-modellerne og overvejede indflydelsen af fingeraftrykslængden på forudsigelsesydelsen af forskellige modeller for at opnå forskellige fingeraftryk. For eksempel, Molecular Access System (MACCS) fingeraftryk indeholdt 166 bit og var det korteste input, og resultaterne var utilfredsstillende på grund af deres begrænsede information.
Sun et al. viste den bedste kombination af programmeringssprog og ML-algoritme opnået ved brug af hybridiseringsfingeraftryk på 1024 bit og RF, at opnå en forudsigelsesnøjagtighed på 81,76 procent; hvor hybridiseringsfingeraftryk repræsenterede SP2-hybridiseringstilstande af molekyler. Når fingeraftrykkets længde steg fra 166 til 1024 bit, ydelsen af alle ML-modeller blev forbedret, da længere fingeraftryk indeholdt mere kemisk information.
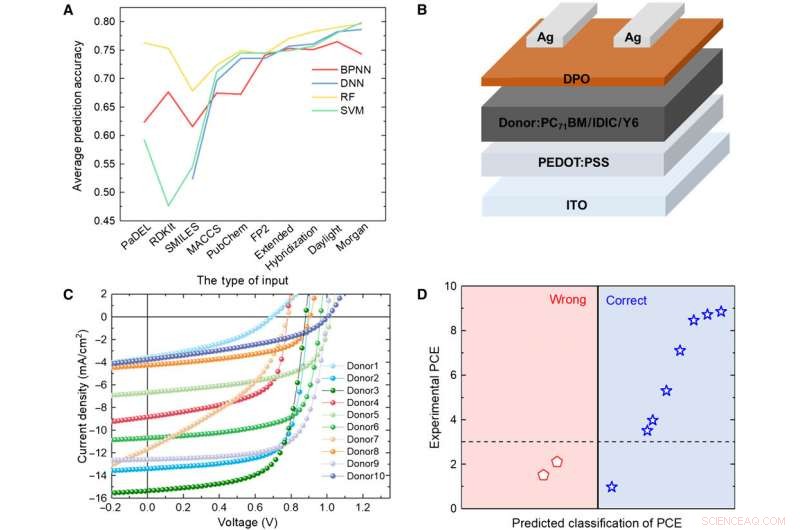
Verifikation af ML-modeller med eksperiment. (A) Sammenligning af resultaterne fra fire forskellige modeller. (B) Skematisk diagram af cellearkitekturen brugt i denne undersøgelse. (C) J-V-kurve for solcellen med det aktive lag ved hjælp af det forudsagte donormateriale. (D) Forudsigelsesresultater versus eksperimentelle data for de forudsagte donormaterialer med RF-algoritmen og Daylight-fingeraftryk. Kredit:Science Advances, doi:10.1126/sciadv.aay4275.
For at teste pålideligheden af ML-modellerne, Sun et al. syntetiserede 10 nye OPV-donormolekyler. Brugte derefter tre repræsentative fingeraftryk til at udtrykke den kemiske struktur af de nye molekyler og sammenlignede resultaterne forudsagt af RF-modellen og de eksperimentelle PCE-værdier. Systemet klassificerede otte af de 10 molekyler. Resultaterne indikerede potentialet af de syntetiske materialer til OPV-applikationer med yderligere eksperimentel optimering for to af de nye materialer. En mindre ændring i strukturen kan forårsage en stor forskel i PCE-værdier. Opmuntrende, ML-modellerne identificerede sådanne mindre ændringer for at lette gunstige forudsigelsesresultater.
På denne måde Wenbo Sun og kolleger brugte en litteraturdatabase om OPV-donormaterialer og en række programmeringssprogsudtryk (billeder, ASCII strenge, deskriptorer og molekylære fingeraftryk) til at bygge ML-modeller og forudsige den tilsvarende OPV PCE-klasse. Holdet demonstrerede et skema til at designe OPV-donormaterialer ved hjælp af ML-tilgange og eksperimentel analyse. De forhåndsscreenede et stort antal donormaterialer ved hjælp af ML-modellen til at identificere førende kandidater til syntese og yderligere eksperimenter. Det nye arbejde kan fremskynde nyt donormaterialedesign for at accelerere udviklingen af høje PCE OPV'er. Brugen af ML i forbindelse med eksperimenter vil fremme materialeopdagelsen.
© 2019 Science X Network
Sidste artikelBrug af en to-trins tilgang til at omdanne alifatiske aminer til unaturlige aminosyrer
Næste artikelDen gode side af kulilte
 Varme artikler
Varme artikler
-
 Nye nanopartikler udviklet til at afbilde og behandle kræftSandia National Laboratories forskere Lauren Rohwer, venstre, Dorina Sava Gallis, centrum, og Kim Butler er medlemmer af et team, der har designet og syntetiseret metal-organiske ramme nanopartikler,
Nye nanopartikler udviklet til at afbilde og behandle kræftSandia National Laboratories forskere Lauren Rohwer, venstre, Dorina Sava Gallis, centrum, og Kim Butler er medlemmer af et team, der har designet og syntetiseret metal-organiske ramme nanopartikler, -
 Informationsfilter til immunforsvarStruktur af MHC-I peptid-belastningskomplekset i membranen af det endoplasmatiske reticulum. Kredit:S. Trowitzsch, A. Möller, R. Tampé I dag, sociale medier hjælper os med at holde os ajour med
Informationsfilter til immunforsvarStruktur af MHC-I peptid-belastningskomplekset i membranen af det endoplasmatiske reticulum. Kredit:S. Trowitzsch, A. Möller, R. Tampé I dag, sociale medier hjælper os med at holde os ajour med -
 Egenskaber ved syrer, baser og salteSyrer, baser og salte er en del af en række ting, vi håndterer dagligt. Syrer giver citrusfrugter den sure smag, mens baser som ammoniak findes i mange typer rengøringsmidler. Salte er et produkt af r
Egenskaber ved syrer, baser og salteSyrer, baser og salte er en del af en række ting, vi håndterer dagligt. Syrer giver citrusfrugter den sure smag, mens baser som ammoniak findes i mange typer rengøringsmidler. Salte er et produkt af r -
 Australske forskere satte rekord for kuldioxidopsamlingKredit:CC0 Public Domain Forskere fra Monash University og CSIRO har sat rekord for kuldioxidopsamling og -lagring (CCS) ved hjælp af teknologi, der ligner en svamp fyldt med små magneter. Ved at
Australske forskere satte rekord for kuldioxidopsamlingKredit:CC0 Public Domain Forskere fra Monash University og CSIRO har sat rekord for kuldioxidopsamling og -lagring (CCS) ved hjælp af teknologi, der ligner en svamp fyldt med små magneter. Ved at
- Måling af kulstof nanorør optaget af planter
- Små børn får venner hurtigere end teenagere, når de flytter ind i mere velhavende kvarterer
- Til lykke til deres dages ende:Forskere arrangerer protein-nanopartikel-ægteskab
- Udvikling af en ny metode til bor-doping af todimensionale kulstofmaterialer
- Bruger ALMA til at løse solens koronale varmemysterium
- Nanopartikellevering maksimerer lægemiddelforsvaret mod bioterrorisme