


Emnejusteret synlighedsmetrik for videnskabelige artikler

En egentlig videnskabelig artikel (fra KDD Cup-datasættet) med kendte citater blev brugt til at demonstrere, hvordan algoritmen kunne generere anbefalinger til forskere, der søger efter information inden for et relateret felt. Figuren viser de 15 bedste citater anbefalet af metrikken. Ud af disse 15 forudsagte citater, fem af dem (markeret med asterisker) var faktiske citater af artiklen. Sammenlignet med, andre metoder formåede ikke at forudsige nogen af de faktiske citater. De farvede segmenter i "emneproportionerne" angiver sandsynligheden for, at en artikel tilhører et specifikt emne. Kredit:Annals of Applied Statistics
En NUS-statistiker har udviklet en metrik, der automatisk tager højde for citationsvariationer i forskellige discipliner til måling af videnskabelige artiklers forskningsmæssige værdi.
Forskningsværdien (impact) af videnskabelige artikler bruges ofte som en af parametrene til at bedømme kvaliteten af forskningsresultater. Dette er normalt opnået fra citater af forskningsarbejde, der allerede er offentliggjort i tidsskriftet. Imidlertid, forskellige akademiske discipliner har forskellig forskningsadfærd og citeringspraksis. For eksempel, artikler inden for visse discipliner (f.eks. matematik) har generelt lave citater, mens andre områder (f.eks. molekylærbiologi) i sammenligning havde flere citater i gennemsnit. Derfor, en sammenligning af forskningskvalitet på tværs af forskellige discipliner baseret på rå citationsantal ville ikke afspejle forskningsværdien nøjagtigt.
Prof Linda TAN fra Institut for Statistik og Anvendt Sandsynlighed, NUS har udviklet en metrik på artikelniveau, kaldet "emnejusteret synlighedsmetrik", som automatisk er i stand til at redegøre for variationen i citeringsaktiviteter mellem forskellige forskningsfelter. Den beregner dette uden at bruge eksisterende feltklassifikationer tagget til den enkelte artikel, men ved at bruge et komplekst netværk, der indeholder attributter, der hører til den valgte artikel. Hver artikel behøver ikke at tilhøre et enkelt felt, men kan tilhøre flere felter med varierende grader. Dette kan give en bedre målestok til at sammenligne individuelle videnskabelige publikationer på tværs af forskellige områder. Forskerholdet har også udviklet en effektiv beregningsalgoritme ved hjælp af denne metrik til at hjælpe akademiske forskere med artikelanbefalinger.
Prof Tan sagde, "Når vores metode anvendes på KDD Cup 2003 (videnopdagelse og data mining-konkurrence) benchmarking-datasæt, som har cirka 30, 000 højenergifysikartikler, det demonstrerede bedre ydeevne for artikelanbefalinger ved at være mere præcis i at forudsige de faktiske citater fra testartikler, sammenlignet med andre tilgængelige modeller."
 Varme artikler
Varme artikler
-
 Gammelt knogleprotein afslører, hvilke skildpadder der var på menuen i Florida, CaribienOrganisk materiale kan hurtigt henfalde i det varme, fugtige forhold i troperne. Men forskere fandt ud af, at mange gamle skildpaddeknogler stadig indeholdt kollagen. De brugte dette protein til at id
Gammelt knogleprotein afslører, hvilke skildpadder der var på menuen i Florida, CaribienOrganisk materiale kan hurtigt henfalde i det varme, fugtige forhold i troperne. Men forskere fandt ud af, at mange gamle skildpaddeknogler stadig indeholdt kollagen. De brugte dette protein til at id -
 Sådan fungerer personlige luftfartøjerSpringtail EFV-4A under en fri svæver i oktober 2003. Se mere jet billeder . Foto høflighed trekaerospace.com Da bilen første gang rullede på grusveje i det 19. århundrede, det tillod os at gå s
Sådan fungerer personlige luftfartøjerSpringtail EFV-4A under en fri svæver i oktober 2003. Se mere jet billeder . Foto høflighed trekaerospace.com Da bilen første gang rullede på grusveje i det 19. århundrede, det tillod os at gå s -
 Undersøgelse finder, at området for retsmedicinsk antropologi mangler mangfoldighedKredit:CC0 Public Domain Den retsmedicinske antropologi er en relativt homogen disciplin med hensyn til mangfoldighed (farvede, LGBTQ+ personer, mennesker med psykiske og fysiske handicap, osv.),
Undersøgelse finder, at området for retsmedicinsk antropologi mangler mangfoldighedKredit:CC0 Public Domain Den retsmedicinske antropologi er en relativt homogen disciplin med hensyn til mangfoldighed (farvede, LGBTQ+ personer, mennesker med psykiske og fysiske handicap, osv.), -
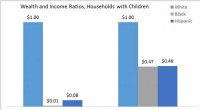 Racerigdomskløften værre for familier med børnKredit:Duke University Det er svært for familier med børn at spare penge. I USA, det er endnu sværere, når familien er sort, finder en ny undersøgelse. Resultaterne fremhæver vedvarende økonomisk
Racerigdomskløften værre for familier med børnKredit:Duke University Det er svært for familier med børn at spare penge. I USA, det er endnu sværere, når familien er sort, finder en ny undersøgelse. Resultaterne fremhæver vedvarende økonomisk
- Forskere introducerer ny varmetransportteori i jagten på effektiv termoelektrik
- Fracking og jordskælv - afvejer farerne i Sydafrika
- Vedholdenhed vil bringe dig overalt:Efter en rejse på 300 millioner miles, NASAs Mars-rover deler T…
- Inertial indeslutning fusion implosioner har betydelige 3-D asymmetrier
- Undervands telekommunikationskabler udgør et fremragende seismisk netværk
- Eksperimenter i isolation:Træning af astronauter til langsigtede solomissioner