


Hvordan en videnskabsmand etablerede et to-trins soludbrudssystem for tidlig varsling
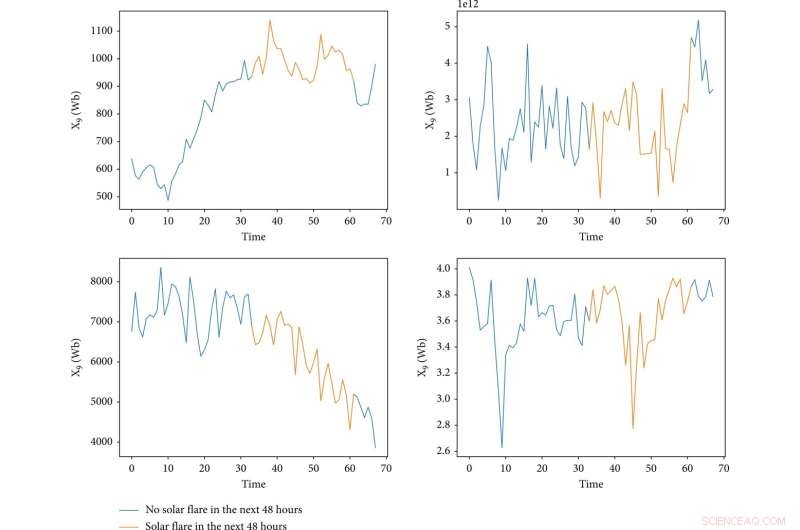
Visualiseringen af fire funktioner under eksistensen af en aktiv region. X-aksen repræsenterer tid, og dens enhed er en prøve, hvor "0" repræsenterer starttidspunktet for et aktivt område, og tidsforskellen mellem tilstødende tidspunkter er 1,5 t. Y-aksen repræsenterer værdien af en funktion. De blå linjer indikerer, at der ikke er nogen soludbrud i de næste 48 timer, og de gule linjer er det modsatte. Kredit:Rum:Videnskab og teknologi
Soludbrud er solstormhændelser drevet af magnetfelter i solaktivitetsområdet. Når denne flare-stråling kommer til Jordens nærhed, øger fotoioniseringen elektrontætheden i ionosfærens D-lag, hvilket forårsager absorption af højfrekvent radiokommunikation, scintillation af satellitkommunikation og øget baggrundsstøjinterferens med radar.
Statistik og erfaringer viser, at jo større udbrændingen er, desto mere sandsynligt er det, at det ledsages af andre soludbrud, såsom en solar protonhændelse, og jo mere alvorlige er virkningerne på Jorden, og dermed påvirker rumflyvning, kommunikation, navigation, kraftoverførsel og andre teknologiske systemer.
At give prognoseoplysninger om sandsynligheden for og intensiteten af flareudbrud er et vigtigt element i begyndelsen af operationelle rumvejrsprognoser. Modelleringsstudiet af soludbrudsforudsigelse er en nødvendig del af nøjagtige udbrudsforudsigelser og har en vigtig anvendelsesværdi. I en forskningsartikel for nylig offentliggjort i Space:Science &Technology , Hong Chen fra College of Science, Huazhong Agricultural University, kombinerede k-betyder klyngealgoritmen og flere CNN-modeller for at bygge et advarselssystem, der kan forudsige, om et soludbrud ville opstå inden for de næste 48 timer.
Først introducerede forfatteren de data, der blev brugt i papiret, og analyserede dem fra et statistisk synspunkt for at danne grundlag for designet af soludbrudsvarslingssystemet. For at reducere projektionseffekten blev midten af det aktive område placeret inden for ±30° fra solskivens centrum valgt. Derefter mærkede forfatteren dataene i overensstemmelse med soludbrudsdata leveret af NOAA, inklusive start- og sluttidspunkter for udstrålingerne, antallet af det aktive område, størrelsen af udbrudene osv.
Der var en alvorlig ubalance mellem antallet af positive og negative prøver i datasættet. For at afhjælpe ubalancen mellem positive og negative prøver blev der fundet et princip om at udvælge de hændelser, der har positive prøver, så meget som muligt. Forfatteren visualiserede sandsynlighedstæthedsfordelingen for hver funktion i alle negative prøver og alle positive prøver. Det kunne let konstateres, at sandsynlighedstæthedsfordelingerne for de negative prøver alle var negativt skæve fordelinger, og karakteristikaene for positive prøver generelt var større end negative prøvers. Det var således muligt at bortfiltrere hændelser med positive prøver efter egenskabsværdierne for hver hændelse.
Bagefter byggede forfatteren hele pipelinen med en metode, der indeholdt følgende to trin:dataforbehandling og modeltræning. For at udføre dataforbehandling blev K-means, en uovervåget klyngemetode, brugt til at klynge hændelser for at reducere hændelser, der kun inkluderer negative prøver så meget som muligt.
Efter k-betyder clustering blev alle hændelser opdelt i tre kategorier, nemlig kategori A, kategori B og kategori C. Forfatteren fandt ud af, at forholdet mellem positive prøver i kategori C er 0,340633, hvilket er meget større end for hele datasættet. Derfor blev kun dataene i kategori C valgt som inputdata på næste trin af algoritmen.
I 2. trin var de neurale netværk, forfatteren brugte, Resnet18, Resnet34 og Xception, som almindeligvis bruges i deep learning. Tre fjerdedele af prøverne i kategori C blev tilfældigt udvalgt. I hvert tilfælde var træningsdata for de neurale netværksmodeller, og resten af prøverne blev betragtet som valideringsdata i processen med træningsmodellen.
For at undgå påvirkning af dimensioner standardiserede forfatteren også de originale data. Standardiseringsmetoden var forskellig fra de almindeligt anvendte. Ifølge standardiseringsberegningsformlen, hvis mærket af en prøve blev forudsagt til at være 1 af det neurale netværk, blev denne prøve betragtet som et signal om soludbrud, der ville forekomme i de næste 48 timer. Men hvis det forudsiges at være 0, ville sandsynligheden for at opstå soludbrud i de næste 48 timer være så lille, at den kunne ignoreres.
Derefter udførte forfatteren eksperimenter og diskuterede resultaterne. Forfatteren gav først en introduktion til eksperimentelle omgivelser og udførte derefter adskillige ablationseksperimenter og sammenligninger med forskellige modeller for at verificere forbedringen af k-betyder klyngealgoritme og boostingstrategi. Desuden lavede forfatteren også sammenligninger mellem den metode, der blev brugt i eksperimentet, og andre 13 binære klassifikationsalgoritmer, der almindeligvis bruges til at præsentere dens forudsigelsesydelse.
De eksperimentelle resultater viste, at forudsigelsesydelsen af modellen, der integrerede flere neurale netværk, var bedre end den af et enkelt foldet neuralt netværk. Endelig blev forudsigelsesresultaterne af Resnet18, Resnet34 og Xception kombineret ved at øge strategien. For alle netværk kan tilbagekaldelse være uændret eller endda reduceret meget efter klyngedannelse. Præcisionen var dog nødt til at stige betydeligt.
Efter klyngedannelse, selvom den positive prøvehastighed ville blive væsentligt forbedret, fra 5 % til 34 %, ville næsten 40 % af informationen om positive prøver også gå tabt. Forfatteren mente, at dette var hovedårsagen til, at tilbagekaldelsen forblev uændret eller endda faldet. Det betød også, at antallet af positive prøver forudsagt i eksperimentet var mindre end den uden klyngedannelse, men sandsynligheden for, at en forudsagt positiv prøve var en sand positiv var højere.
In contrast with the phenomenon that the prediction performance of other binary classification methods was decreasing or even very poor after clustering, the performance of the author's method improved by more than 9% after clustering. In conclusion, the two-stage solar flare early warning system consisted of an unsupervised clustering algorithm (k-means) and several CNN models, where the former was to increase the positive sample rate, and the latter integrated the prediction results of the CNN models to improve the prediction performance.
The results of the experiment proved the effectiveness of the method. + Udforsk yderligere
How scientist applied the recommendation algorithm to anticipate CMEs' arrival times
 Varme artikler
Varme artikler
-
 Faktisk billede af en hvid dværg, der lever af materiale fra en større rød kæmpe 650 lysår fra …Dette billede er fra SPHERE/ZIMPOL observationerne af R Aquarii, og viser selve binærstjernen, med den hvide dværg, der lever af materiale fra Mira-variablen, samt strålerne af materiale, der spyr fra
Faktisk billede af en hvid dværg, der lever af materiale fra en større rød kæmpe 650 lysår fra …Dette billede er fra SPHERE/ZIMPOL observationerne af R Aquarii, og viser selve binærstjernen, med den hvide dværg, der lever af materiale fra Mira-variablen, samt strålerne af materiale, der spyr fra -
 En Yellowstone guide til livet på MarsUniversity of Cincinnati kandidatstuderende Andrew Gangidine studerer silicaaflejringer i Yellowstone for at finde en elementær biosignatur, som NASA kan bruge til at lede efter liv på Mars, når den l
En Yellowstone guide til livet på MarsUniversity of Cincinnati kandidatstuderende Andrew Gangidine studerer silicaaflejringer i Yellowstone for at finde en elementær biosignatur, som NASA kan bruge til at lede efter liv på Mars, når den l -
 Kviksølvpassage observeret ved Cerro Tololo Inter-American ObservatoryKredit:AURA Cirka 13 gange pr. flygtig Merkur kan ses passere direkte foran Solen i det, der kaldes en transit. Den seneste Merkur-transit fandt sted den 11. november, 2019. Hold ved Cerro Tololo
Kviksølvpassage observeret ved Cerro Tololo Inter-American ObservatoryKredit:AURA Cirka 13 gange pr. flygtig Merkur kan ses passere direkte foran Solen i det, der kaldes en transit. Den seneste Merkur-transit fandt sted den 11. november, 2019. Hold ved Cerro Tololo -
 Undskyld, Elon Musk, men det er nu klart, at kolonisering af Mars er usandsynlig - og en dårlig idéTærte i himlen? Mars Ice Home koncept. Kredit:NASA/Clouds AO/SEArch Space X og Tesla-grundlæggeren Elon Musk har en vision om at kolonisere Mars, baseret på en stor raket, atomeksplosioner og en i
Undskyld, Elon Musk, men det er nu klart, at kolonisering af Mars er usandsynlig - og en dårlig idéTærte i himlen? Mars Ice Home koncept. Kredit:NASA/Clouds AO/SEArch Space X og Tesla-grundlæggeren Elon Musk har en vision om at kolonisere Mars, baseret på en stor raket, atomeksplosioner og en i
- Ny arkitektur øger energi- og spektrumeffektiviteten til Internet of Things trådløs kommunikation
- Sekundære skove giver skovrydningsbuffer for gammelvækst primære skove
- Vanddråber bliver til hydrobots ved at tilføje magnetiske perler
- Hvordan kulstof nanorør kunne bruges i fremtidige elektroniske enheder
- Facebook og COVID-19:De slettede appen, så kom coronavirus
- Ny produktionsmetode for 2D-materialer kan føre til smartere enheder