


Ny metode muliggør taleadskillelse af høj kvalitet
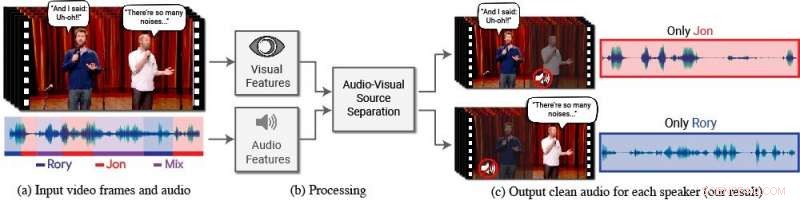
En ny model isolerer og forbedrer talen fra ønskede højttalere i en video. (a) Indgangen er en video (frames + lydspor) med en eller flere personer, der taler, hvor talen af interesse forstyrres af andre højttalere og/eller baggrundsstøj. (b) Både audio og visuelle funktioner udtrækkes og føres ind i en fælles audiovisuel taleadskillelsesmodel. (c) Outputtet er en dekomponering af input-lydsporet til rene talespor, én for hver person, der registreres i videoen. Specifikke personers tale forbedres i videoerne, mens al anden lyd undertrykkes. Den nye model blev trænet ved hjælp af tusindvis af timers videosegmenter fra holdets nye datasæt, AVSpeech, som vil blive udgivet offentligt. Kredit:Forfattere/Google Video-stills:Med tilladelse fra Team Coco/CONAN
Folk har en naturlig evne til at fokusere på, hvad en enkelt person siger, selv når der er konkurrerende samtaler i baggrunden eller andre distraherende lyde. For eksempel, folk kan ofte se, hvad der bliver sagt af nogen på en overfyldt restaurant, under en larmende fest, eller mens du ser tv-debatter, hvor flere eksperter taler om hinanden. Til dato, at være i stand til beregningsmæssigt – og præcist – at efterligne denne naturlige menneskelige evne til at isolere tale har været en vanskelig opgave.
"Computere bliver bedre og bedre til at forstå tale, men stadig har betydelige problemer med at forstå tale, når flere mennesker taler sammen, eller når der er meget støj, " siger Ariel Ephrat, en ph.d. kandidat ved Hebrew University of Jerusalem-Israel og hovedforfatter af forskningen. (Ephrat udviklede den nye model, mens han var i praktik hos Google sommeren 2017.) "Vi mennesker ved, hvordan man forstår tale under sådanne forhold naturligt, men vi vil have computere til at kunne gøre det lige så godt som os, måske endda bedre."
Til denne ende, Ephrat og hans kollegaer hos Google har udviklet en ny audiovisuel model til at isolere og forbedre talen fra ønskede talere i en video. Teamets dybe netværksbaserede model inkorporerer både visuelle og auditive signaler for at isolere og forbedre enhver højttaler i enhver video, selv i udfordrende scenarier i den virkelige verden, såsom videokonferencer, hvor flere deltagere ofte taler på én gang, og larmende barer, som kunne indeholde en række forskellige baggrundsstøj, musik, og konkurrerende samtaler.
Holdet, som inkluderer Googles Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, og Michael Rubinstein, vil præsentere deres arbejde på SIGGRAPH 2018, afholdt 12-16 august i Vancouver, Britisk Columbia. Den årlige konference og udstilling viser verdens førende fagfolk, akademikere, og kreative sind på forkant med computergrafik og interaktive teknikker.
I dette arbejde, forskerne fokuserede ikke kun på auditive signaler for at adskille tale, men også visuelle signaler i videoen - dvs. forsøgspersonens læbebevægelser og potentielt andre ansigtsbevægelser, der kan låne til det, han eller hun siger. De visuelle funktioner, der opnås, bruges til at "fokusere" lyden på et enkelt emne, der taler, og til at forbedre kvaliteten af taleadskillelse.
For at træne deres fælles audiovisuelle model, Ephrat og samarbejdspartnere kuraterede et nyt datasæt, "AVSpeech, "består af tusindvis af YouTube-videoer og andre onlinevideosegmenter, såsom TED Talks, how-to videoer, og foredrag af høj kvalitet. Fra AVSpeech, forskerne genererede et træningssæt af såkaldte "syntetiske cocktailpartyer" - blandinger af ansigtsvideoer med ren tale og andre talelydspor med baggrundsstøj. For at isolere tale fra disse videoer, brugeren er kun forpligtet til at angive ansigtet på den person i videoen, hvis lyd skal fremhæves.
I flere eksempler beskrevet i papiret, med titlen "Looking to Listen at the Cocktail Party:A Speaker-Independent Audio-Visual Model for Speech Separation, "den nye metode viste overlegne resultater sammenlignet med eksisterende kun lydmetoder på rene taleblandinger, og betydelige forbedringer i levering af klar lyd fra blandinger, der indeholder overlappende tale og baggrundsstøj i scenarier i den virkelige verden. Mens fokus for arbejdet er taleadskillelse og forbedring, holdets nye metode kunne også anvendes til automatisk talegenkendelse (ASR) og videotransskription – dvs. lukkede undertekster på streaming af videoer og tv. I en demonstration, den nye fælles audiovisuelle model producerede mere nøjagtige billedtekster i scenarier, hvor to eller flere højttalere var involveret.
Først overrasket over, hvor godt deres metode fungerede, forskerne er begejstrede for dets fremtidige potentiale.
"Vi har ikke set taleadskillelse udført 'i naturen' i en sådan kvalitet før. Det er derfor, vi ser en spændende fremtid for denne teknologi, " bemærker Ephrat. "Der skal mere arbejde til, før denne teknologi lander i forbrugernes hænder, men med de lovende foreløbige resultater, som vi har vist, vi kan helt sikkert se, at det understøtter en række applikationer i fremtiden, som videotekstning, videokonference, og endda forbedrede høreapparater, hvis sådanne enheder kunne kombineres med kameraer."
Forskerne undersøger i øjeblikket mulighederne for at inkorporere det i forskellige Google-produkter.
 Varme artikler
Varme artikler
-
 Forskere er pionerer på en ny måde at omdanne sollys til brændstofEksperimentel to-elektrode opsætning, der viser den fotoelektrokemiske celle belyst med simuleret sollys. Kredit:Katarzyna Sokó? Jagten på at finde nye måder at udnytte solenergi har taget et skri
Forskere er pionerer på en ny måde at omdanne sollys til brændstofEksperimentel to-elektrode opsætning, der viser den fotoelektrokemiske celle belyst med simuleret sollys. Kredit:Katarzyna Sokó? Jagten på at finde nye måder at udnytte solenergi har taget et skri -
 Amazon siger, at franske kunder skal bære omkostningerne ved Frances nye digitale skatAmazon er en af flere amerikanske internetgiganter målrettet mod en ny fransk skat på digitale indtægter, trækker vrede over USAs præsident Donald Trump Amazon planlægger at videregive omkostnin
Amazon siger, at franske kunder skal bære omkostningerne ved Frances nye digitale skatAmazon er en af flere amerikanske internetgiganter målrettet mod en ny fransk skat på digitale indtægter, trækker vrede over USAs præsident Donald Trump Amazon planlægger at videregive omkostnin -
 MIT-holds plukke- og placeringssystem er på et andet niveauKredit:Computer Science &Artificial Intelligence Laboratory Hvis du ser på denne pick and place robot, ser du med det samme, hvorfor det er en stor sag – ikke så meget for fingerfærdighed og fin b
MIT-holds plukke- og placeringssystem er på et andet niveauKredit:Computer Science &Artificial Intelligence Laboratory Hvis du ser på denne pick and place robot, ser du med det samme, hvorfor det er en stor sag – ikke så meget for fingerfærdighed og fin b -
 Anbefaling til kryptografisk nøglegenereringKredit:CC0 Public Domain Kryptografi bruges ofte i informationsteknologiske sikkerhedsmiljøer til at beskytte følsomme, data af høj værdi, der kan blive kompromitteret under transmission eller und
Anbefaling til kryptografisk nøglegenereringKredit:CC0 Public Domain Kryptografi bruges ofte i informationsteknologiske sikkerhedsmiljøer til at beskytte følsomme, data af høj værdi, der kan blive kompromitteret under transmission eller und
- Instruktioner om hvordan man bruger en Abacus
- Eksperimentel udgivelse af Robot Operating System til Windows udgør en attraktiv vej for udviklere
- Se Mælkevejenes supermassive sorte hul føde
- Astronomer opdager en massiv stjernehob, mellem alder, i stjernebilledet Scutum
- Undersøgelse viser en kraftig stigning i detektionshastigheden af brede absorptionslinjevariation…
- Sahara -ørkenen udvider sig - verdens største ørken voksede med 10 procent siden 1920