


Fremtiden for AI har brug for hardwareacceleratorer baseret på analoge hukommelsesenheder
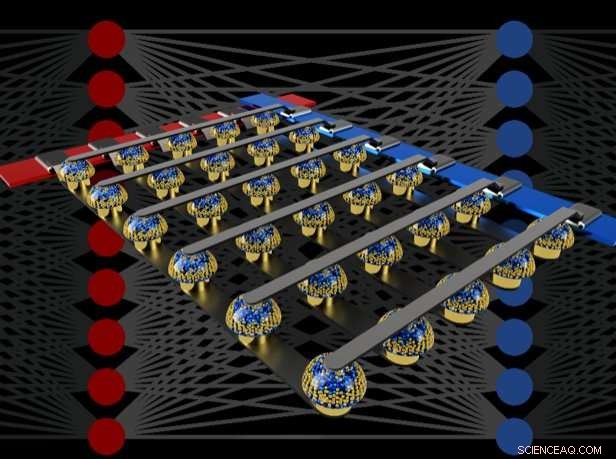
Tværbjælkearrays af ikke-flygtige hukommelser kan accelerere træningen af fuldt forbundne neurale netværk ved at udføre beregninger på stedet for dataene. Kredit:IBM
Forestil dig personlig kunstig intelligens (AI), hvor din smartphone bliver mere som en intelligent assistent – genkender din stemme selv i et støjende rum, at forstå konteksten af forskellige sociale situationer eller kun præsentere de oplysninger, der virkelig er relevante for dig, plukket ud af den strøm af data, der kommer hver dag. Sådanne kapaciteter kan snart være inden for vores rækkevidde – men at nå dertil kræver hurtig, magtfulde, energieffektive AI-hardwareacceleratorer.
I et nyligt papir offentliggjort i Natur , vores IBM Research AI-team demonstrerede deep neural network (DNN) træning med store arrays af analoge hukommelsesenheder med samme nøjagtighed som et Graphical Processing Unit (GPU)-baseret system. Vi mener, at dette er et stort skridt på vejen mod den slags hardwareacceleratorer, der er nødvendige for de næste AI-gennembrud. Hvorfor? Fordi at levere Future of AI vil kræve en voldsom udvidelse af omfanget af AI-beregninger.
DNN'er skal blive større og hurtigere, både i skyen og på kanten – og det betyder, at energieffektiviteten skal forbedres dramatisk. Mens bedre GPU'er eller andre digitale acceleratorer til en vis grad kan hjælpe, sådanne systemer bruger uundgåeligt meget tid og energi på at flytte data fra hukommelsen til behandling og tilbage. Vi kan forbedre både hastighed og energieffektivitet ved at udføre AI-beregninger i det analoge domæne med lige ved placeringen af dataene – men det giver kun mening at gøre, hvis de resulterende neurale netværk er lige så smarte som dem, der er implementeret med konventionel digital hardware.
Analoge teknikker, involverer kontinuerligt variable signaler i stedet for binære 0'er og 1'ere, har iboende grænser for deres præcision - hvilket er grunden til, at moderne computere generelt er digitale computere. Imidlertid, AI-forskere er begyndt at indse, at deres DNN-modeller stadig fungerer godt, selv når digital præcision er reduceret til niveauer, der ville være alt for lave til næsten enhver anden computerapplikation. Dermed, for DNN'er, det er muligt, at analog beregning måske også kunne fungere.
Imidlertid, indtil nu, ingen havde endegyldigt bevist, at sådanne analoge tilgange kunne udføre det samme arbejde som nutidens software, der kører på konventionel digital hardware. Det er, kan DNN'er virkelig trænes til tilsvarende høj nøjagtighed med disse teknikker? Det nytter ikke meget at være hurtigere eller mere energieffektiv i at træne en DNN, hvis den resulterende klassificeringsnøjagtighed altid vil være uacceptabel lav.
I vores avis, vi beskriver, hvordan analoge ikke-flygtige hukommelser (NVM) effektivt kan accelerere "tilbagepropagations"-algoritmen i hjertet af mange nyere AI-fremskridt. Disse hukommelser tillader "multiply-accumulate"-operationer, der bruges gennem disse algoritmer, at blive paralleliseret i det analoge domæne, ved placeringen af vægtdata, ved hjælp af underliggende fysik. I stedet for store kredsløb til at multiplicere og lægge digitale tal sammen, vi sender simpelthen en lille strøm gennem en modstand ind i en ledning, og derefter forbinde mange sådanne ledninger sammen for at lade strømmene bygge op. Dette lader os udføre mange beregninger på samme tid, frem for den ene efter den anden. Og i stedet for at sende digitale data på lange rejser mellem digitale hukommelseschips og behandlingschips, vi kan udføre al beregning inde i den analoge hukommelseschip.
Imidlertid, på grund af forskellige ufuldkommenheder, der er iboende til nutidens analoge hukommelsesenheder, tidligere demonstrationer af DNN-træning udført direkte på store arrays af rigtige NVM-enheder formåede ikke at opnå klassificeringsnøjagtigheder, der matchede softwaretrænede netværk.
Ved at kombinere langtidslagring i phase-change memory (PCM) enheder, nær-lineær opdatering af konventionelle Complementary Metal-Oxide Semiconductor (CMOS) kondensatorer og nye teknikker til at udligne enhed-til-enhed variabilitet, vi finjusterede disse ufuldkommenheder og opnåede software-ækvivalente DNN-nøjagtigheder på en række forskellige netværk. Disse eksperimenter brugte en blandet hardware-software tilgang, kombinerer softwaresimuleringer af systemelementer, der er nemme at modellere nøjagtigt (såsom CMOS-enheder) sammen med fuld hardwareimplementering af PCM-enhederne. Det var vigtigt at bruge rigtige analoge hukommelsesenheder til hver vægt i vores neurale netværk, fordi modelleringsmetoder for sådanne nye enheder ofte ikke er i stand til at fange hele rækken af enhed-til-enhed variabilitet, de kan udvise.
Ved at bruge denne tilgang, vi bekræftede, at fulde chips faktisk skulle give tilsvarende nøjagtighed, og dermed gøre det samme arbejde som en digital accelerator – men hurtigere og med lavere effekt. I betragtning af disse opmuntrende resultater, vi er allerede begyndt at udforske designet af prototype hardwareacceleratorchips, som en del af et IBM Research Frontiers Institute-projekt.
Fra disse tidlige designbestræbelser var vi i stand til at levere, som en del af vores naturpapir, indledende estimater for potentialet af sådanne NVM-baserede chips til træning af fuldt forbundne lag, med hensyn til beregningsmæssig energieffektivitet (28, 065 GOP/sek/W) og gennemløb pr. område (3,6 TOP/sek/mm2). Disse værdier overstiger specifikationerne for nutidens GPU'er med to størrelsesordener. Desuden, fuldt forbundne lag er en type neurale netværkslag, for hvilke den faktiske GPU-ydeevne ofte falder et godt stykke under de nominelle specifikationer.
Dette papir indikerer, at vores NVM-baserede tilgang kan levere softwareækvivalente træningsnøjagtigheder såvel som en forbedring af acceleration og energieffektivitet i størrelsesordener på trods af ufuldkommenhederne i eksisterende analoge hukommelsesenheder. De næste skridt vil være at demonstrere den samme softwareækvivalens på større netværk, der kræver store, fuldt forbundne lag – såsom de tilbagevendende forbundne Long Short Term Memory (LSTM) og Gated Recurrent Unit (GRU) netværk bag de seneste fremskridt inden for maskinoversættelse, billedtekster og tekstanalyse – og til at designe, implementere og forfine disse analoge teknikker på prototype NVM-baserede hardwareacceleratorer. Nye og bedre former for analog hukommelse, optimeret til denne applikation, kunne bidrage yderligere til at forbedre både arealtæthed og energieffektivitet.
Sidste artikelApple lukker iPhone-sikkerhedskløften brugt af retshåndhævelse
Næste artikeliPal-robotledsager til Kinas ensomme børn
 Varme artikler
Varme artikler
-
 Forskning i lithium-ilt-batterier kan øge ydeevnen af elektronik, bilerBatteridesignet vil fokusere på oxygenelektroden (~1,2 cm diameter og 0,4 mm tykkelse). Kredit:Xianglin Li Træt af at skulle tilslutte din telefon hver aften? Hjælpen er måske på vej. Ny forsknin
Forskning i lithium-ilt-batterier kan øge ydeevnen af elektronik, bilerBatteridesignet vil fokusere på oxygenelektroden (~1,2 cm diameter og 0,4 mm tykkelse). Kredit:Xianglin Li Træt af at skulle tilslutte din telefon hver aften? Hjælpen er måske på vej. Ny forsknin -
 Infosys-fortjenesten stiger med 23,5 %, da sonden ikke finder bevis for fejlInfosys sagde, at deres undersøgelse ikke havde fundet beviser for uredelighed eller økonomisk bedrageri fra topledere, herunder administrerende direktør Salil Parekh (R) Indiens næststørste it-ou
Infosys-fortjenesten stiger med 23,5 %, da sonden ikke finder bevis for fejlInfosys sagde, at deres undersøgelse ikke havde fundet beviser for uredelighed eller økonomisk bedrageri fra topledere, herunder administrerende direktør Salil Parekh (R) Indiens næststørste it-ou -
 Den hypodermiske effekt - hvordan propaganda manipulerer vores følelserKredit:CC0 Public Domain Skandalen omkring Cambridge Analyticas og Facebooks ukorrekte brug af data ved det amerikanske valg i 2016 minder om de gamle debatter om propaganda og dens evne til at kr
Den hypodermiske effekt - hvordan propaganda manipulerer vores følelserKredit:CC0 Public Domain Skandalen omkring Cambridge Analyticas og Facebooks ukorrekte brug af data ved det amerikanske valg i 2016 minder om de gamle debatter om propaganda og dens evne til at kr -
 For billigt til at lægge mærke til vand er ved at være slut, og vandforsyninger skal advare forbr…Kredit:CC0 Public Domain De fleste forbrugere kender prisen på en gallon benzin. Mange kunder kan læse deres elregninger og forstå, hvordan strøm blev brugt i faktureringsperioden. Men spørg dem,
For billigt til at lægge mærke til vand er ved at være slut, og vandforsyninger skal advare forbr…Kredit:CC0 Public Domain De fleste forbrugere kender prisen på en gallon benzin. Mange kunder kan læse deres elregninger og forstå, hvordan strøm blev brugt i faktureringsperioden. Men spørg dem,
- Hvad er virkningerne af mennesker på græsbiomer?
- Flash oversvømmelser viste sig at sende massiv mængde mikroplast fra floder til havet
- Hvordan ild i dag vil påvirke vandet i morgen
- Plastkrisens nye ansigt
- Nanoplader forbedrer LCD- og LED-skærme
- Undersøgelse viser, at indkomstulighed driver den voksende indkomstforskel mellem forskellige regio…