


Kondensatorbaseret arkitektur til AI-hardware acceleratorer
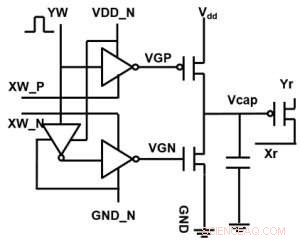
Figur 1. Enhedscelle skematisk for et kondensatorbaseret tværpunktsarray. Kredit:IBM
IBM rækker ud over digitale teknologier med et kondensatorbaseret tværpunktsarray til analoge neurale netværk, udviser potentielle størrelsesordener forbedringer i dybe læringsberegninger. Analoge computingarkitekturer udnytter lagringskapaciteten og fysiske attributter for visse hukommelsesenheder ikke kun til at gemme oplysninger, men også for at udføre beregninger. Dette har potentiale til i høj grad at reducere den tid og energi, der kræves af computere, fordi data ikke skal flyttes mellem hukommelsen og processoren. Ulempen kan være en reduktion i beregningsnøjagtighed, men for systemer, der ikke kræver høj nøjagtighed, det er den rigtige bytte.
I analoge neurale netværk (NN), ikke-flygtige hukommelse (NVM) baserede kryds-punkt-arrays har opnået lovende resultater for slutningsopgaver. Imidlertid, at træne NN'er til høj nøjagtighed er svært for NVM -enheder, da vellykket træning afhænger af at holde de inkrementelle ændringer i NN -vægten lille (kræver cirka 1, 000 opdateringstilstande) og symmetriske (så positive og negative opdateringer i gennemsnit balancerer). Sådanne problemer kan løses ved hjælp af kondensatorer. Da ladning kan tilføjes eller fratrækkes kontinuerligt, hvis antallet af elektroner er højt, analog og symmetrisk vægtopdatering kan opnås. Vi præsenterede et kondensatorbaseret tværpunktsarray til analoge neurale netværk på VLSI Technology Symposium 2018. Den nye arkitektur opnåede rekordsymmetri og linearitet for vægtopdatering.
Figur 1 viser enhedscelle skematisk for et kondensatorbaseret tværpunktsarray. Nøglekomponenten er kondensatoren, der er forbundet til en udlæsning felt effekt transistor (FET). Ladningen på kondensatoren repræsenterer den synaptiske vægt, og kondensatoren oplades og aflades med to strømkilde -FET'er. Figur 2 viser den målte ændring i konduktansen af aflæsning FET for en enkelt celle, og tilsvarende kondensatorspænding henholdsvis ved at anvende ti cyklusser med 400 positive opdateringer efterfulgt af 400 negative opdateringer. Figur 3 sammenligner de eksperimentelle ikke-linearitetsopdateringsfaktorer for vores kondensatorbaserede analoge synaps mod andre NVM-teknologier. Den kondensatorbaserede enhedscelle giver den bedste symmetri og linearitet, der er demonstreret til dato. Figur 4 viser parallel vægtopdatering på et 2 × 2 array.
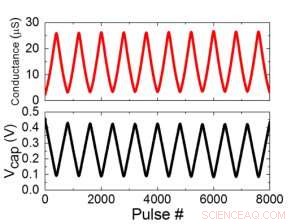
Figur 2. (a) Eksperimentelle resultater til opdatering af enkeltcelle med 8000 pulser. (b) Tilsvarende ændring af kondensatorspænding. Pulsbredde 50 ns, periode:500 ns. Kredit:IBM
Selvom kondensatorer er flygtige, lækagen kunne kompenseres under vægtopdatering. Da træningen gentagne gange går fremad, baglæns og vægtopdateringscyklusser, vægte efter henfald i forrige cyklus bruges i træning til næste cyklus og bliver opdateret. Derfor, ingen forsætlige opdateringscyklusser er nødvendige. Vi testede effekten af opbevaringstid på træning, ved hjælp af et fuldt tilsluttet netværk. Den har et inputlag, to skjulte lag, og et outputlag (figur 5) og blev trænet i MNIST -datasættet ved stokastisk gradientnedstigning og tilbagepropagering. Forudsat at træningscyklussens længde pr. Lag (fremad+baglæns+opdatering) er 200 ns og synaptisk vægt falder med RC -tidskonstant τ, vi fandt ud af, at straf i træningsnøjagtighed på grund af kondensatorladningstab bliver ubetydelig, når τ> 106 × træningscykluslængden (figur 6). Vi testede også kravet til opbevaringstid for et konvolutionsnetværk. Vores testnetværk har to konvolutionslag med to poollag og to fuldt tilsluttede lag (figur 7). På grund af vægtdelingen (genbrug) i konvolutionslag, opbevaringskravene for et konvolutionsnervalt netværk (CNN) er omkring 600 større (figur 8).
Vi anslår skalerbarheden af dette kondensatorbaserede array som en funktion af lækage for både fuldt tilsluttede og konvolutonale neurale netværk (figur 9). Cirkeldatapunkter viser, at kondensatoren skaleres lineært med pass transistor lækage. Firkantede datapunkter viser, at når lækagen er stor, celleområdet domineres af kondensatorerne; når lækstrømmen er lille, området vil blive domineret af FET'er i cellen. For DRAM -teknologi med lækage af 1 fA/celle kræver kondensator <1fF/celle til fuldt tilsluttet neuralt netværk og ~ 100 fF/celle til CNN. Skalerbarheden til større input og flere lag kræver yderligere undersøgelse. Selvom det kan have brug for større kondensator, når input bliver større, vores foreløbige resultater (offentliggøres) viser, at optimering af netværk/algoritme kan reducere kondensatorbehovet.
IBM arbejder nu på en ny ideel hukommelse med optimeret analog adfærd. Disse kondensatorer gør det muligt at implementere analog AI -kerne på en accelereret tidsplan, da teknologien og processen er tilgængelige.
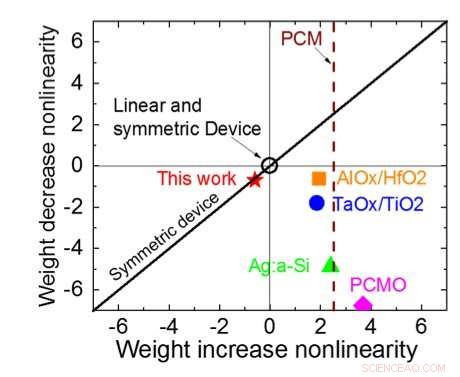
Figur 3. Konduktans-ikke-linearitet af dette arbejde sammenlignet med andre NVM-teknologier. Kredit:IBM
Ud over vores kondensator tilgang, IBM undersøger andre nye elementer til analog hukommelse og beregning, såsom faseændringshukommelse (PCM) og resistiv RAM (RRAM). Disse elementer varierer med hensyn til celleområder, tilbageholdelse, symmetri, og modenhed. Analoge acceleratorer er en komponent i IBM Research AIs pipeline af AI -hardware -acceleratorer. Rørledningen starter med at få mest muligt ud af eksisterende GPU -acceleratorer, efterfulgt af innovative digitale AI -kerner, der udnytter omtrentlige computere.
-
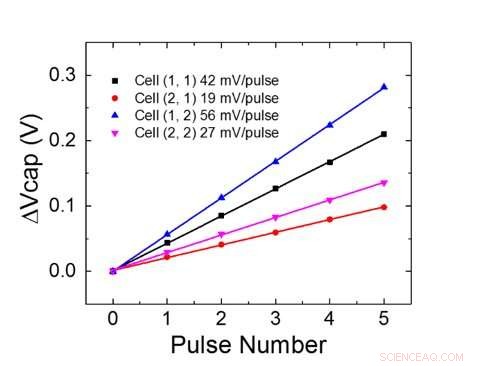
Figur 4. Parallel vægtopdatering på et 2 × 2 array. Kredit:IBM
-
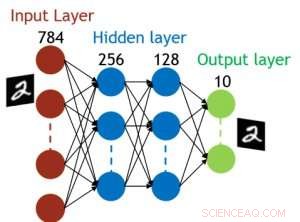
Figur 5. Simuleret struktur til fuldt forbundet neuralt netværk. Kredit:IBM
-
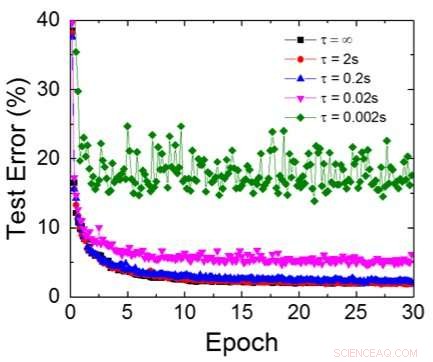
Figur 6. Simuleret testfejl for MNIST -datasæt, forudsat at vægte henfalder kontinuerligt med forskellig RC -tidskonstant τ, 200ns træningscykluslængde. Kredit:IBM
-
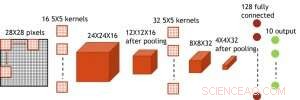
Figur 7. Simuleret struktur for konvolutionelt neuralt netværk. Kredit:IBM
-
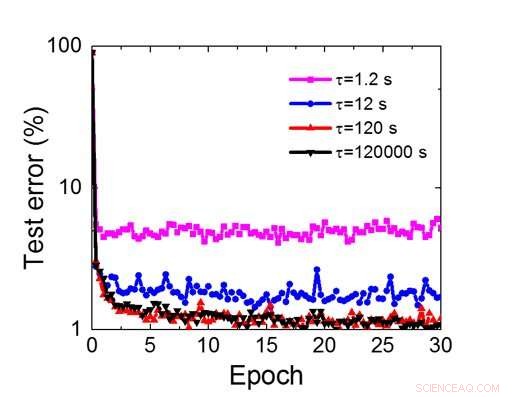
Figur 8. Simuleret krav til tilbageholdelsestid for dette kondensatorbaserede array til at træne konvolutionsnervalt netværk. Kredit:IBM
-
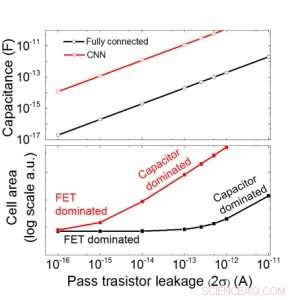
Figur 9. Skalerbarhed af dette kondensatorbaserede array som en funktion af lækage for både fuldt tilsluttede og konvolutonale neurale netværk. Kredit:IBM
Sidste artikelSpace IoT tager fart
Næste artikelSoftBank hæver aktieposten i Yahoo Japan ved køb fra Altaba
 Varme artikler
Varme artikler
-
 Team udvikler natriumionbatterier ved hjælp af kobbersulfidSodieringsprocessen af kobbersulfid. Kredit:KAIST Et KAIST -forskerhold udviklede for nylig natriumionbatterier ved hjælp af kobbersulfidanode. Dette fund vil bidrage til at fremme kommercialise
Team udvikler natriumionbatterier ved hjælp af kobbersulfidSodieringsprocessen af kobbersulfid. Kredit:KAIST Et KAIST -forskerhold udviklede for nylig natriumionbatterier ved hjælp af kobbersulfidanode. Dette fund vil bidrage til at fremme kommercialise -
 Et aktuelt kort til forbedring af kredsløbsdesignStrømmen af en elektrisk strøm mellem to elektroder på en magnetisk tynd film afbildes ved at måle strimmeldomænerne. Kredit:KAUST En praktisk metode til at kortlægge strømmen af en strøm i en
Et aktuelt kort til forbedring af kredsløbsdesignStrømmen af en elektrisk strøm mellem to elektroder på en magnetisk tynd film afbildes ved at måle strimmeldomænerne. Kredit:KAUST En praktisk metode til at kortlægge strømmen af en strøm i en -
 Udfordringerne og potentielle fordele ved at gå over til koncentreret solenergi for at afsalte havv…Mange ørkenområder kunne afsalte med solenergi, men hvilken slags solcelle? Hvad med efter mørkets frembrud? Og hvilken afsaltningsteknologi er bedst parret med solenergi? Kredit:NASA Manglen på f
Udfordringerne og potentielle fordele ved at gå over til koncentreret solenergi for at afsalte havv…Mange ørkenområder kunne afsalte med solenergi, men hvilken slags solcelle? Hvad med efter mørkets frembrud? Og hvilken afsaltningsteknologi er bedst parret med solenergi? Kredit:NASA Manglen på f -
 Unik teknologi overgår traditionelle varmelagringsmuligheder i fleksibilitet og effektivitetStørrelsen på en skraldespand, Argonnes lagringssystem for termisk energi kan skaleres op eller ned for at opfylde behovene i stort set enhver kommerciel applikation. Kredit:Argonne National Laborator
Unik teknologi overgår traditionelle varmelagringsmuligheder i fleksibilitet og effektivitetStørrelsen på en skraldespand, Argonnes lagringssystem for termisk energi kan skaleres op eller ned for at opfylde behovene i stort set enhver kommerciel applikation. Kredit:Argonne National Laborator