


Beskyttelse af AI's intellektuelle ejendom med vandmærkning
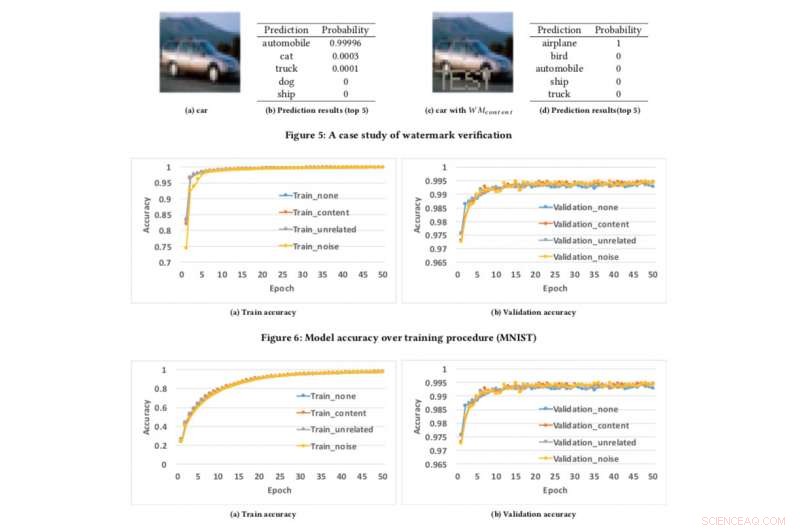
Modelnøjagtighed over træningsprocedure. Kredit:CIFAR10
Hvis vi kan beskytte videoer, lyd og fotos med digital vandmærkning, hvorfor ikke AI-modeller?
Dette er spørgsmålet, mine kolleger og jeg stillede os selv, da vi søgte at udvikle en teknik til at forsikre udviklere om, at deres hårde arbejde med at bygge AI, såsom deep learning-modeller, kan beskyttes. Du tænker måske, "Beskyttet mod hvad?" Godt, for eksempel, hvad hvis din AI-model bliver stjålet eller misbrugt til ondsindede formål, såsom at tilbyde en plagieret service bygget på stjålet model? Dette er en bekymring, især for AI-ledere som IBM.
Tidligere på måneden præsenterede vi vores forskning på AsiaCCS '18-konferencen i Incheon, Republikken Korea, og vi er stolte af at sige, at vores omfattende evalueringsteknik til at løse denne udfordring har vist sig at være yderst effektiv og robust. Vores nøgleinnovation er, at vores koncept kan fjernbekræfte ejerskabet af DNN-tjenester (Deep Neural Network) ved hjælp af simple API-forespørgsler.
Efterhånden som deep learning-modeller bliver mere udbredt og bliver mere værdifulde, de er i stigende grad mål for modstandere. Vores idé, som er patentanmeldt, tager inspiration fra de populære vandmærketeknikker, der bruges til multimedieindhold, såsom videoer og billeder.
Når du vandmærker et billede, er der to trin:indlejring og registrering. I indlejringsstadiet, ejere kan overlejre ordet "COPYRIGHT" på billedet (eller vandmærker, der er usynlige for menneskelig opfattelse), og hvis det bliver stjålet og brugt af andre, bekræfter vi dette i opdagelsesstadiet, hvorved ejere kan udtrække vandmærkerne som juridisk bevis for at bevise ejerskab. Samme idé kan anvendes på DNN.
Ved at indlejre vandmærker til DNN-modeller, hvis de bliver stjålet, vi kan verificere ejerskabet ved at udtrække vandmærker fra modellerne. Imidlertid, forskellig fra digital vandmærkning, som integrerer vandmærker i multimedieindhold, vi var nødt til at designe en ny metode til at indlejre vandmærker i DNN-modeller.
I vores avis, vi beskriver en tilgang til at indsætte vandmærker i DNN-modeller, og designe en fjernbekræftelsesmekanisme til at bestemme ejerskabet af DNN-modeller ved at bruge API-kald.
Vi udviklede tre vandmærkegenereringsalgoritmer til at generere forskellige typer vandmærker til DNN-modeller:
- indlejring af meningsfuldt indhold sammen med de originale træningsdata som vandmærker i de beskyttede DNN'er,
- indlejring af irrelevante dataeksempler som vandmærker i de beskyttede DNN'er, og
- indlejring af støj som vandmærker i de beskyttede DNN'er.
For at teste vores vandmærkeramme, vi brugte to offentlige datasæt:MNIST, et håndskrevet ciffergenkendelsesdatasæt, der har 60, 000 træningsbilleder og 10, 000 testbilleder og CIFAR10, et objektklassifikationsdatasæt med 50, 000 træningsbilleder og 10, 000 testbilleder.
At køre eksperimentet er ret ligetil:vi forsyner simpelthen DNN med et specifikt udformet billede, som udløser en uventet, men kontrolleret reaktion, hvis modellen er blevet vandmærket. Det er ikke første gang vandmærkning er blevet overvejet, men tidligere koncepter var begrænset ved at kræve adgang til modelparametre. Imidlertid, i den virkelige verden, de stjålne modeller installeres normalt eksternt, og den plagierede tjeneste ville ikke offentliggøre parametrene for de stjålne modeller. Ud over, de indlejrede vandmærker i DNN-modeller er robuste og modstandsdygtige over for forskellige modvandmærkemekanismer, såsom finjustering, parameter beskæring, og modelinversionsangreb.
Ak, vores rammer har nogle begrænsninger. Hvis den lækkede model ikke implementeres som en onlinetjeneste, men bruges som en intern tjeneste, så kan vi ikke opdage noget tyveri, men så kan plagiatøren selvfølgelig ikke tjene penge på de stjålne modeller.
Ud over, vores nuværende vandmærkeramme kan ikke beskytte DNN-modellerne mod at blive stjålet gennem forudsigelses-API'er, hvorved angribere kan udnytte spændingen mellem forespørgselsadgang og fortrolighed i resultaterne til at lære parametrene for maskinlæringsmodeller. Imidlertid, sådanne angreb har kun vist sig at fungere godt i praksis for konventionelle maskinlæringsalgoritmer med færre modelparametre såsom beslutningstræer og logistiske regressioner.
Vi søger i øjeblikket at implementere dette i IBM og undersøge, hvordan teknologien kan leveres som en service til kunder.
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
 Varme artikler
Varme artikler
-
 3D-udskrivning af den næste generation af batterierGitterarkitektur kan tilvejebringe kanaler til effektiv transport af elektrolyt inde i mængden af materiale, mens for terningelektroden, det meste af materialet vil ikke blive udsat for elektrolytte
3D-udskrivning af den næste generation af batterierGitterarkitektur kan tilvejebringe kanaler til effektiv transport af elektrolyt inde i mængden af materiale, mens for terningelektroden, det meste af materialet vil ikke blive udsat for elektrolytte -
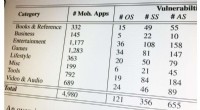 Smartphone -apps kan oprette forbindelse til sårbare backend -cloud -servereEn del af diagrammet er oprettet for at give et overblik over sårbare mobilapps efter genre. Kredit:Georgia Tech Cybersikkerhedsforskere har opdaget sårbarheder i backend-systemer, der fodrer indh
Smartphone -apps kan oprette forbindelse til sårbare backend -cloud -servereEn del af diagrammet er oprettet for at give et overblik over sårbare mobilapps efter genre. Kredit:Georgia Tech Cybersikkerhedsforskere har opdaget sårbarheder i backend-systemer, der fodrer indh -
 Mozilla-initiativet hjælper stemmeteknologispillere via multi-sprog datasætDet lyder måske som en mundfuld, men det betyder virkelig meget. Mozilla taler om det største til dato transskriberede stemmedatasæt i det offentlige domæne. Oversættelse:Over 14, 000 mennesker. På 18
Mozilla-initiativet hjælper stemmeteknologispillere via multi-sprog datasætDet lyder måske som en mundfuld, men det betyder virkelig meget. Mozilla taler om det største til dato transskriberede stemmedatasæt i det offentlige domæne. Oversættelse:Over 14, 000 mennesker. På 18 -
 Den amerikanske radiogigant iHeartMedia anmoder om konkursBob Pittman, formanden og administrerende direktør for iHeartMedia, sagde, at aftalen ville hjælpe med at opnå en kapitalstruktur, der endelig matcher vores imponerende driftsforretning Førende am
Den amerikanske radiogigant iHeartMedia anmoder om konkursBob Pittman, formanden og administrerende direktør for iHeartMedia, sagde, at aftalen ville hjælpe med at opnå en kapitalstruktur, der endelig matcher vores imponerende driftsforretning Førende am