


Bekæmp offensivt sprog på sociale medier med tekstoverførsel uden opsyn
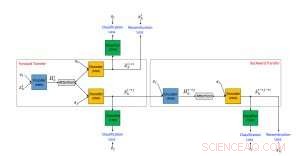
Foreslået ramme for en neural tekststiloverførselsalgoritme ved hjælp af ikke-parallelle data. Kredit:IBM
Online sociale medier er blevet en af de vigtigste måder at kommunikere og udveksle ideer på. Desværre, diskursen er ofte lammet af misbrugssprog, der kan have skadelige virkninger for brugere af sociale medier. For eksempel, en nylig undersøgelse fra YouGov.uk opdagede, at blandt de oplysninger, som arbejdsgivere kan finde online om jobkandidater, aggressivt eller stødende sprog er den mest professionelt skadelige aktivitet på sociale medier. Online sociale medier-netværk håndterer normalt det stødende sprogproblem ved blot at filtrere et opslag fra, når det er markeret som stødende.
I avisen "Fighting Offensive Language on Social Media with Unsupervised Text Style Transfer, "som blev præsenteret på det 56. årlige møde i Association for Computational Linguistics (ACL 2018), vi introducerer en helt ny tilgang til at tackle dette problem. Vores tilgang bruger tekstoverførsel uden opsyn til at oversætte stødende sætninger til tilsvarende ikke-stødende former. Så vidt vi ved, alt tidligere arbejde om problemet med stødende sprog på sociale medier har kun fokuseret på tekstklassificering. Disse metoder kan således hovedsageligt bruges til at markere og filtrere det stødende indhold, men vores foreslåede tilgang går et skridt fremad og producerer en alternativ ikke-stødende version af indholdet. Dette har to potentielle fordele for brugere af sociale medier. For de brugere, der planlægger at sende en stødende besked, at modtage en advarsel om, at indholdet er stødende og vil blive blokeret, sammen med en mere høflig version af meddelelsen, der kan sendes, kan tilskynde dem til at ændre mening og undgå bandeord. Derudover for brugere, der bruger onlineindhold, dette giver dem mulighed for stadig at se og forstå budskabet, men i en ikke-stødende og høflig tone.
En arkitektur til at erstatte stødende sprog
Vores metode er baseret på den nu populære encoder-decoder neurale netværksarkitektur, som er den topmoderne tilgang til maskinoversættelse. I maskinoversættelse, træningen af encoder-decoder neurale netværk forudsætter eksistensen af en "Rosetta Stone", hvor den samme tekst er skrevet på både kilde- og målsproget. Disse parrede data gør det muligt for udviklere nemt at afgøre, om et system oversætter korrekt og derfor træne et encoder-dekodersystem til at klare sig godt. Desværre, i modsætning til maskinoversættelse, så vidt vi ved, der findes ikke noget datasæt med parrede data til rådighed i tilfælde af stødende til ikke-stødende sætninger. I øvrigt, den overførte tekst skal bruge et ordforråd, der er almindeligt i et bestemt applikationsdomæne. Derfor, uovervågede metoder, der ikke bruger parrede data, er nødvendige for at udføre denne opgave.

Vi foreslog en uovervåget metode til overførsel af tekststil, der består af tre hovedkomponenter, hver får en separat opgave under træningen. En (en RNN-koder) analyserer en stødende sætning og komprimerer den mest relevante information til en vektor med virkelig værdi. Dette læses af en anden komponent (en RNN-dekoder), som genererer en ny sætning, der er den oversatte version af den originale. Den oversatte sætning evalueres derefter af den tredje komponent (en CNN-klassifikator) for at identificere, om output er korrekt oversat fra den offensive stil til ikke-offensiv. Derudover den genererede sætning er også "tilbage-oversat" fra ikke-stødende til stødende og sammenlignet med den oprindelige sætning for at kontrollere, om indholdet blev bevaret. Hvis resultaterne af en af ovenstående evalueringer indeholder fejl, systemet justeres derefter. Indkoderen og dekoderen er også, parallelt, trænet ved hjælp af en autoencoding setup, hvor målet består i at rekonstruere input sætningen. Vi bruger også opmærksomhedsmekanismen, som er med til at sikre indholdsbevaring. Vores vigtigste bidrag til arkitektur er den kombinerede brug af en kollaborativ klassifikator, opmærksomhed, og tilbageoverførsel.
Oversættelse af stødende sprog
Vi testede vores foreslåede metode ved hjælp af data fra to populære sociale medienetværk:Twitter og Reddit. Vi skabte datasæt af stødende og ikke-stødende tekster ved at klassificere cirka 10 millioner indlæg ved hjælp af en offensiv sprogklassifikator foreslået af Davidson et al. (2017). Følgende tabel viser eksempler på originale stødende sætninger og de ikke-stødende oversættelser genereret af en tekststiloverførselsmetode foreslået af Shen et al. (2017) og ved vores tilgang. Vores system viste bedre resultater til at oversætte stødende sætninger til ikke-stødende, samtidig med at det overordnede indhold bevaredes, men det producerer nogle gange mærkelige sætninger.
Dette arbejde er et første skridt i retning af en ny lovende tilgang til bekæmpelse af krænkende opslag på sociale medier. Uovervåget tekststiloverførsel er et forskningsområde, der lige er begyndt at se nogle lovende resultater. Vores arbejde er et godt bevis på konceptet for, at nuværende ikke -overvåget tekststiloverførselsmetoder kan anvendes på nyttige opgaver. Imidlertid, det er vigtigt at bemærke, at nuværende uovervågede metoder til overførsel af tekststil kun godt kan håndtere de tilfælde, hvor det stødende sprogproblem er leksikalsk (såsom eksemplerne vist i tabellen) og kan løses ved at ændre eller fjerne nogle få ord. De modeller, vi brugte, vil ikke være effektive i tilfælde af implicit bias, hvor almindeligt ustødelige ord bruges stødende.
Vi mener, at forbedrede versioner af den foreslåede metode, sammen med brugen af meget større mængder træningsdata, vil være i stand til at klare andre krænkende indlæg, såsom indlæg, der indeholder hadefulde ytringer, racisme, og sexisme. Vi forestiller os, at vores metode kunne bruges til at forbedre konversations-AI, ved at sikre, at chatbots, der lærer ved at interagere med brugere online, ikke senere vil gengive stødende sprog og hadefulde ytringer. Forældrekontrol er en anden potentiel anvendelse af det foreslåede system.
Denne historie er genudgivet med tilladelse fra IBM Research.
 Varme artikler
Varme artikler
-
 Teknikfirmaer underskriver et løfte om at afstå fra at hjælpe cyberangrebDe seneste års bølge af cyberangreb har fået store teknologivirksomheder til at underskrive en pagt om at arbejde sammen, og at acceptere ikke at hjælpe regeringer med at iværksætte offensive foransta
Teknikfirmaer underskriver et løfte om at afstå fra at hjælpe cyberangrebDe seneste års bølge af cyberangreb har fået store teknologivirksomheder til at underskrive en pagt om at arbejde sammen, og at acceptere ikke at hjælpe regeringer med at iværksætte offensive foransta -
 Ny afsendelsesmetode kunne reducere antallet af taxaer på vejen og samtidig imødekomme passagerern…Kredit:Ad Meskens via Wikipedia Fremkomsten af selvkørende biler vil dramatisk ændre den måde, vi bevæger os rundt i byer på i fremtiden. I særdeleshed, privat bilejerskab forventes at skifte m
Ny afsendelsesmetode kunne reducere antallet af taxaer på vejen og samtidig imødekomme passagerern…Kredit:Ad Meskens via Wikipedia Fremkomsten af selvkørende biler vil dramatisk ændre den måde, vi bevæger os rundt i byer på i fremtiden. I særdeleshed, privat bilejerskab forventes at skifte m -
 Microsoft opfordrer til regulering af ansigtsgenkendende teknologiMicrosoft og andre teknologivirksomheder har brugt ansigtsgenkendelsesteknologi i årevis til opgaver som at organisere digitale fotografier Microsofts juridiske chef opfordrede fredag til regule
Microsoft opfordrer til regulering af ansigtsgenkendende teknologiMicrosoft og andre teknologivirksomheder har brugt ansigtsgenkendelsesteknologi i årevis til opgaver som at organisere digitale fotografier Microsofts juridiske chef opfordrede fredag til regule -
 Wimbledon omarbejder AI-teknologi for at reducere skævhed i spilhøjdepunkterPersonalet overvåger spildata og arbejder med kampanalyse i et operationsrum under Wimbledon Tennis Championships i London, Onsdag, 3. juli, 2019. All England Club tilføjer teknologiforbedringer ved d
Wimbledon omarbejder AI-teknologi for at reducere skævhed i spilhøjdepunkterPersonalet overvåger spildata og arbejder med kampanalyse i et operationsrum under Wimbledon Tennis Championships i London, Onsdag, 3. juli, 2019. All England Club tilføjer teknologiforbedringer ved d
- Fremskridt inden for røntgenbilleder skinner lys på nanomaterialer
- Sådan beregnes væksthastighed eller procentvis ændring
- TSA lufthavns sikkerhedsscreening vil blive meget mere præcis lige i tide for nogle ferierejsende
- Nyt hjelmdesign kan håndtere sportsdrejninger
- Ingeniør opdager mægtig kraft i opfindelsen med lille solenergi
- Aktive flydende krystalsystemer undersøgt i jagten på autonome materialesystemer