


Wide learning AI-teknologi muliggør meget præcis læring selv fra ubalancerede datasæt
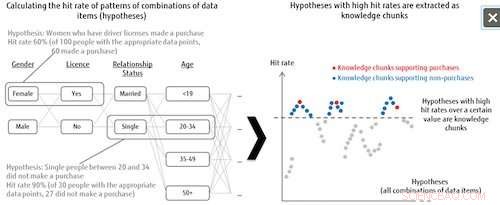
Figur 1:Hypoteseliste og udtræk af vidensklumper. Kredit:Fujitsu
Fujitsu Laboratories Ltd. annoncerede i dag udviklingen af "Wide Learning, "en maskinlæringsteknologi, der er i stand til præcise vurderinger, selv når operatører ikke kan få den mængde data, der er nødvendig til træning. AI bruges nu ofte til at udnytte data på en række forskellige områder, men nøjagtigheden af AI kan blive påvirket i tilfælde, hvor mængden af data, der skal analyseres, er lille eller ubalanceret. Fujitsus Wide Learning-teknologi gør det muligt at opnå vurderinger mere præcist, end det tidligere var muligt, og læring opnås ensartet, uanset hvilken hypotese der undersøges, selv når dataene er ubalancerede. Det opnår den ved først at uddrage hypoteser med en høj grad af betydning, efter at have lavet et stort sæt hypoteser dannet af alle kombinationerne af dataelementer, og derefter ved at kontrollere graden af virkning af hver respektive hypotese baseret på hypotesernes overlappende forhold. I øvrigt, fordi hypoteserne er registreret som logiske udtryk, mennesker kan også forstå ræsonnementet bag en dom. Fujitsus nye Wide Learning-teknologi giver mulighed for brug af kunstig intelligens selv inden for områder som sundhedspleje og markedsføring, hvor de nødvendige data til at foretage domme er knappe, understøtter driften og fremmer automatisering af arbejdsprocesser ved hjælp af kunstig intelligens.
I de seneste år, AI-teknologi er begyndt at blive brugt på en række forskellige områder, herunder sundhedsvæsenet, markedsføring, og finans. Der er stigende forventninger til brugen af AI-beslutningstagning til støtte for drift og automatisering af opgaver på disse områder. En udfordring, der stadig er at realisere potentialet i disse teknologier, imidlertid, er, at dataene kan være ubalancerede. Specifikt, afhængigt af branchen kan det være vanskeligt at skaffe tilstrækkelige data til at træne AI på de mål, som den skal tage stilling til. Det her, træde i kræft, efterlader mange af disse teknologier ude af stand til at producere resultater med tilstrækkelig nøjagtighed til praktisk brug. Desuden, en væsentlig årsag til, at AI-implementeringen mangler fremskridt, er, at selv når en AI giver tilstrækkelig nøjagtig genkendelses- eller klassificeringsydelse, eksperter og endda udviklerne selv kan ofte ikke forklare, hvorfor AI'en producerede et bestemt svar, og hvis de ikke kan opfylde deres ansvar for at forklare resultaterne til industriens frontlinjer, kan kunstig intelligens ikke implementeres.
AI-teknologier baseret på deep learning foretager konventionelt meget nøjagtige vurderinger ved at blive trænet i store mængder data, inklusive rigelige måldata, der skal bedømmes. I scenarier i den virkelige verden, imidlertid, der er mange tilfælde, hvor dataene er utilstrækkelige, med ekstremt få måldata. I disse tilfælde, når man står over for ukendte data, det bliver svært for kunstig intelligens-teknologi at levere meget nøjagtige vurderinger. I øvrigt, maskinlæringsmodellen for eksisterende AI baseret på deep learning er en sort boks-model, der ikke kan forklare årsagerne bag de vurderinger, AI foretager, skabe et problem med gennemsigtighed. Som sådan, fremadrettet vil det være nødvendigt at udvikle ny AI-teknologi, der realiserer meget nøjagtige vurderinger fra ubalancerede data, og det er også gennemsigtigt for at løse forskellige problemer i samfundet.
Med disse udfordringer i tankerne, Fujitsu Laboratories har nu udviklet Wide Learning, en maskinlæringsteknologi, der er i stand til at foretage meget nøjagtige vurderinger, selv i tilfælde, hvor dataene er ubalancerede. Funktionerne i Wide Learning-teknologien omfatter følgende to punkter.
1. Opretter kombinationer af dataelementer for at udtrække store mængder af hypoteser
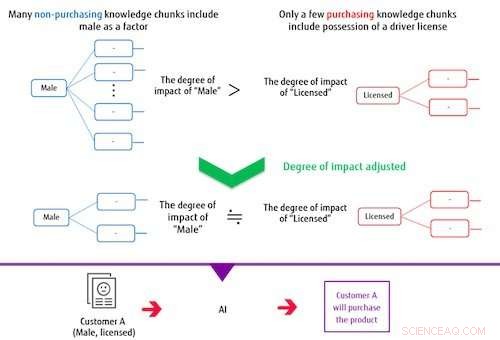
Figur 2:Når man laver en klassifikationsmodel, vidensstykkerne påvirker tilpasningen. Kredit:Fujitsu
Denne teknologi behandler alle kombinationsmønstre af dataelementer som hypoteser, og bestemmer derefter graden af vigtighed af hver hypotese baseret på hitraten for etiketkategorien. For eksempel, når man analyserer tendenser i, hvem der køber bestemte produkter, systemet kombinerer alle mulige mønstre fra dataelementerne for dem, der gjorde eller ikke foretog køb (kategorietiketten), såsom enlige kvinder mellem 20-34, der har kørekort, og analyserer derefter, hvor mange hits det får i data fra dem, der rent faktisk har foretaget køb, når disse kombinationsmønstre tages som hypoteser. De hypoteser, der opnår en hitrate over et vist niveau, defineres som vigtige hypoteser, kaldet "viden bidder". Dette betyder, at selv når måldata er utilstrækkelige, systemet kan udtrække alle hypoteser, der er værd at undersøge, hvilket også kan bidrage til opdagelsen af tidligere uovervejede forklaringer.
2. Justerer graden af påvirkning af vidensstykker for at opbygge en nøjagtig klassifikationsmodel
Systemet bygger en klassifikationsmodel baseret på flere udtrukne vidensstykker og på måletiketten. I denne proces, hvis de emner, der udgør en vidensklump, ofte overlapper de genstande, der udgør andre vidensdele, systemet kontrollerer deres grad af påvirkning for at reducere vægten af deres indflydelse på klassifikationsmodellen. På denne måde systemet kan træne en model, der er i stand til præcise klassificeringer, selv når måletiketten eller de data, der er markeret som korrekte, er ubalancerede. For eksempel, i et tilfælde, hvor mænd, der ikke foretog et køb, udgør langt størstedelen af et varekøbsdatasæt, hvis AI trænes uden at kontrollere graden af påvirkning, så den vidensdel, der inkluderer, hvorvidt en person har en licens eller ej, uafhængig af køn, vil ikke have stor indflydelse på klassificeringen. Med denne nyudviklede metode, graden af påvirkning af vidensstykker, herunder mænd som en faktor, er begrænset på grund af overlapningen af dette emne, mens virkningen af det mindre antal vidensstykker, der inkluderer, om en person har en licens, bliver relativt større i uddannelse, opbygning af en model, der korrekt kan kategorisere både mænd og besiddelse af en licens.
Fujitsu Laboratories gennemførte et forsøg med denne teknologi, anvende det på data inden for områder som digital markedsføring og sundhedsvæsen. I en test med benchmarkdata inden for marketing- og sundhedsområdet fra UC Irvine Machine Learning Repository, denne teknologi forbedrede nøjagtigheden med omkring 10-20 % sammenlignet med deep learning. Det reducerede med succes sandsynligheden for, at systemet ville overse kunder, der sandsynligvis abonnerer på en service, eller patienter med en tilstand med omkring 20-50 %. I markedsføringsdataene, af de cirka 5, 000 kundedataindtastninger brugt i testen, kun omkring 230 var til købende kunder, skabe et ubalanceret sæt. Denne teknologi reducerede antallet af potentielle kunder udelukket fra salgskampagner fra 120, resultatet af deep learning-analyse, til 74. Desuden da de vidensstykker, der danner grundlaget for denne teknologi, har et logisk udtryksformat, evnen til at forklare ræsonnementet bag en dom er også nyttig til at implementere denne teknologi i samfundet. Selv når det er fastslået, at korrektioner til en model er nødvendige, baseret på resultater fra nye data, det er muligt at foretage mere passende revisioner, fordi brugerne kan forstå årsagerne til resultaterne.
Fujitsu Laboratories vil fortsætte med at anvende denne teknologi til opgaver, der kræver ræsonnementet bag AI-domme, såsom i finansielle transaktioner og medicinske diagnoser, og til opgaver, der håndterer lavfrekvente fænomener, såsom svindel og udstyrsnedbrud, med det mål at kommercialisere det som en ny maskinlæringsteknologi, der understøtter Fujitsu Limiteds Fujitsu Human Centric AI Zinrai i regnskabsåret 2019. Fujitsu Laboratories vil også gøre effektiv brug af denne teknologis karakteristiske evne til forklaring, fortsat forskning og udvikling inden for emner såsom forbedret støtte til at træffe domme og beslutninger i opgaver, som det anvendes på, og ind i det overordnede systemdesign, herunder samarbejde med mennesker.
 Varme artikler
Varme artikler
-
 Brug af dyb læring til at forudsige besøg på skadestuerFigur 1. Foreslået model. Kredit:IBM Hos IBM Research, vi undersøger nye løsninger til en række udfordringer i sundhedsvæsenet. En sådan udfordring er overbelægning på skadestuen (ER), hvilket kan
Brug af dyb læring til at forudsige besøg på skadestuerFigur 1. Foreslået model. Kredit:IBM Hos IBM Research, vi undersøger nye løsninger til en række udfordringer i sundhedsvæsenet. En sådan udfordring er overbelægning på skadestuen (ER), hvilket kan -
 Hærens projekt udvikler agile spejderrobotterUC Berkeley robotics kandidatstuderende Justin Yim diskuterer sin springrobot, Salto, som er finansieret af den amerikanske hær. Kredit:University of California Berkley I et forskningsprojekt for
Hærens projekt udvikler agile spejderrobotterUC Berkeley robotics kandidatstuderende Justin Yim diskuterer sin springrobot, Salto, som er finansieret af den amerikanske hær. Kredit:University of California Berkley I et forskningsprojekt for -
 Genopladelige batterier i dine yndlingsenheder kan antænde og brænde dit hus nedKredit:CC0 Public Domain Vi spiller alle russisk roulette med enheder, der drives af lithium-ion-batterier. Chancerne er, at du har snesevis af lithium-ion-drevne enheder inde i dit hjem lige nu.
Genopladelige batterier i dine yndlingsenheder kan antænde og brænde dit hus nedKredit:CC0 Public Domain Vi spiller alle russisk roulette med enheder, der drives af lithium-ion-batterier. Chancerne er, at du har snesevis af lithium-ion-drevne enheder inde i dit hjem lige nu. -
 AIs nuværende hype og hysteri kan sætte teknologien tilbage med årtierAI er ikke så skræmmende, som vi forestiller os. Kredit:AndreyZH/Shutterstock De fleste diskussioner om kunstig intelligens (AI) er kendetegnet ved hyperbol og hysteri. Selvom nogle af verdens mes
AIs nuværende hype og hysteri kan sætte teknologien tilbage med årtierAI er ikke så skræmmende, som vi forestiller os. Kredit:AndreyZH/Shutterstock De fleste diskussioner om kunstig intelligens (AI) er kendetegnet ved hyperbol og hysteri. Selvom nogle af verdens mes
- Billede:Hubble ser galaksen fra det berømte katalog
- Step-by-Step Math Problem Solvere for Proportions
- En videnskabelig undersøgelse kendetegner vores venskabskredse
- Forskere sætter maskinlæring på vej til kvantefordel
- Billede:NASAs Webb Telescope renrumstransporter
- Omkostningerne ved at blive like på sociale medier