


En ny konvolutionel neural netværksmodel til at opdage misbrug og incivilitet på Twitter
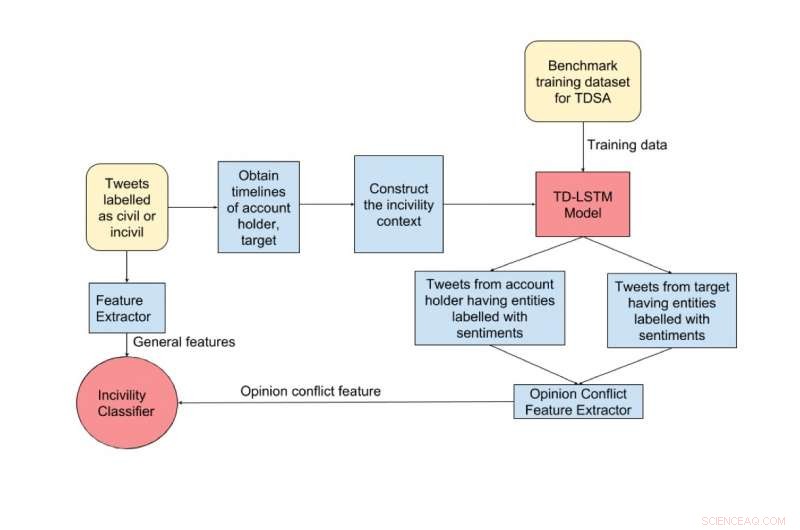
Skematisk over trinene til incivilitetsdetektion. De gule farvede blokke repræsenterer input, de røde blokke repræsenterer klassifikatorerne og de blå farvede blokke repræsenterer de mellemliggende trin. Kredit:Maity et al.
Forskere ved Northwestern University, McGill University, og Indian Institute of Technology Kharagpur har for nylig udviklet en CNN-model (convolutional neural network) på tegnniveau, der kunne hjælpe med at opdage misbrugsindlæg på Twitter. Denne model viste sig at overgå adskillige baseline metoder, opnår en nøjagtighed på 93,3 procent.
I de seneste år, krænkende adfærd på online platforme er steget eksponentielt, især på Twitter. Sociale medievirksomheder søger derfor effektive nye metoder til at identificere denne adfærd for at gribe ind og forhindre, at den forårsager alvorlig skade.
"Twitter, som oprindeligt blev tænkt som et 'e-bytorv, ' bliver til en mosh pit, "Animesh Mukherjee, en af forskerne, der gennemførte undersøgelsen, fortalte Tech Xplore . "Et stigende antal cyber-aggression, sager om cybermobning og incivilitet bliver rapporteret hver dag, hvoraf mange påvirker brugerne alvorligt. Faktisk, dette er en af hovedårsagerne til, at Twitter mister sin aktive tilhængerbase."
Onlineindhold kan spredes hurtigt og nå meget brede målgrupper, så tilfælde af onlinemisbrug trækker ofte ud i lange perioder med meget skadelige virkninger. Offeret eller ofrene, såvel som andre følsomme tilskuere, kan ende med at læse gerningsmandens ord utallige gange, før disse endelig forsvinder fra Twitter. Det er derfor, det er vigtigt for sociale medieplatforme at opdage dette indhold effektivt og hurtigt, udføre rettidige indgreb for at fjerne det.
"Vi satte ud med det mål at udvikle en mekanisme, der automatisk kan opdage uncivile tweets tidligt, før de kan lave alvorlig skade, " sagde Mukherjee. "Vi observerede, at oftest, et offer/mål angribes efter at have udtrykt stærke følelser over for bestemte navngivne enheder. Dette førte os til den centrale idé om at udnytte meningskonflikter til at opdage uncivile tweets."
Mukherjee og hans kolleger indså, at krænkende indlæg ofte er korreleret med meningsforskelle mellem gerningsmanden og målet, især meninger om en kendt offentlig person eller enhed. De inkorporerede derfor enhedsspecifikke sentimentoplysninger i deres CNN-model, håber, at dette vil forbedre dens ydeevne til at opdage misbrugsindhold.

I eksemplet på incivility kontekst citeret nedenfor, vi observerer, at målet tweeter positivt om Donald Trump og amerikansk økonomi. Imidlertid, gerningsmanden (kontohaveren) tweeter negativt om Trump og positivt om præsident Obama. Vi kan observere, at der er en meningskonflikt mellem målet og kontohaveren, da de følelser, der udtrykkes over for den fælles navngivne enhed Donald Trump, er modsatte. Gennemgå hele udvekslingen af beskeder, vi finder, at denne meningskonflikt i sidste ende fører til en ucivil post. Kredit:Maity et al.
"Karakterniveauet CNN forsøger automatisk at udtrække mønstre fra uncivile tweets, der adskiller dem fra andre tweets, "Pawan Goyal, en anden forsker, der gennemførte undersøgelsen, fortalte Tech Xplore. "Vi valgte også at bruge indlejring på karakterniveau, snarere end indlejring på ordniveau. Da tweets normalt er små, kun indeholde nogle få ord, og har mange stavevariationer, modeller på tegnniveau viser sig at være mere robuste end modeller på ordniveau."
Denne CNN-model på karakterniveau klarede sig bedre end den bedste baseline-metode med 4,9 procent, opnår en nøjagtighed på 93,3 procent i at detektere uncivile tweets. Forskerne udførte også en post-hoc analyse, ser nærmere på adfærdsmæssige aspekter af lovovertrædere og ofre på Twitter, i håb om bedre at kunne forstå hændelser i uorden.
Denne analyse afslørede, at en betragtelig del af brugerne var gentagne lovovertrædere, som havde chikaneret mål over 10 gange. Tilsvarende nogle mål var blevet chikaneret af forskellige lovovertrædere ved flere forskellige lejligheder. "Det mest interessante resultat af denne undersøgelse er, at meningskonflikter er stærkt korreleret med ucivil adfærd på Twitter, " sagde Mukherjee. "Denne enkelt funktion forbundet med den char-CNN-baserede dybe neurale model kan være meget effektiv til at identificere uncivile tweets tidligt."
I fremtiden, CNN-modellen udviklet af Mukherjee og hans kolleger kunne være med til at modvirke og reducere krænkende indhold på Twitter. Forskerne forsøger nu at udvikle lignende modeller til at opdage hadefulde ytringer på Twitter, samt på andre sociale medieplatforme.
"I mellemtiden vi studerer også, hvordan hadefulde ytringer spredes på sociale medier, samt at undersøge, hvordan forskellige metoder til at imødegå hadefulde ytringer kan hjælpe med at tackle dette ondskabsfulde online-fænomen, " sagde Mukherjee.
© 2018 Tech Xplore
 Varme artikler
Varme artikler
-
 Spotify vinder flere fans i aktiemarkedsdebuten, efterhånden som aktierne stigerEn handelspost har Spotify-logoet på gulvet på New York Stock Exchange, Tirsdag, 3. april, 2018. Spotify, den nr. 1 musikstreamingtjeneste, som har draget sammenligninger med Netflix, er ved at finde
Spotify vinder flere fans i aktiemarkedsdebuten, efterhånden som aktierne stigerEn handelspost har Spotify-logoet på gulvet på New York Stock Exchange, Tirsdag, 3. april, 2018. Spotify, den nr. 1 musikstreamingtjeneste, som har draget sammenligninger med Netflix, er ved at finde -
 Afrikas største flyselskab bliver ramt af $550 millioner på grund af coronavirus:CEOEthiopian Airlines, den største transportør i Afrika, har afskaffet de fleste af sine ruteflyvninger på grund af pandemien - det søger at fragt- og charterhandel for at hjælpe med at udfylde hullet
Afrikas største flyselskab bliver ramt af $550 millioner på grund af coronavirus:CEOEthiopian Airlines, den største transportør i Afrika, har afskaffet de fleste af sine ruteflyvninger på grund af pandemien - det søger at fragt- og charterhandel for at hjælpe med at udfylde hullet -
 Hvor fantastisk er det:En 3D-printet undervands jetpackKredit:Archie OBrien Hvad ved vi om jetpacks. For en, vi kan let tænke på sci-fi-film, hvor Tony Stark hurtigt skal komme til skurke uden besværlig hjælp fra rumfartøjer, og vi ser ham flyve over
Hvor fantastisk er det:En 3D-printet undervands jetpackKredit:Archie OBrien Hvad ved vi om jetpacks. For en, vi kan let tænke på sci-fi-film, hvor Tony Stark hurtigt skal komme til skurke uden besværlig hjælp fra rumfartøjer, og vi ser ham flyve over -
 Facebook siger, at det bliver bedre til at fjerne hadytringerI denne 7. juni, 2013, fil foto, Facebook lignende symbolet lyser på et skilt uden for virksomhedens hovedkvarter i Menlo Park, Californien. Facebook siger, at det gør fremskridt med at slette hadfuld
Facebook siger, at det bliver bedre til at fjerne hadytringerI denne 7. juni, 2013, fil foto, Facebook lignende symbolet lyser på et skilt uden for virksomhedens hovedkvarter i Menlo Park, Californien. Facebook siger, at det gør fremskridt med at slette hadfuld
- Forskere udvikler ny metode til at detektere ilt på exoplaneter
- Æg afslører, hvad der kan ske med hjernen ved påvirkning
- Er Donald Trump anti-videnskab? Dataene siger ja
- Virkningerne af Platypus Venom
- Røntgenmikroskopi afslører det enestående håndværk hos tekstilfarvere i sibirisk jernalder
- Fra super- til ultraopløselig mikroskopi:Ny metode skubber grænsen til billedopløsning