


En ny dynamisk ensemble aktiv læringsmetode baseret på en ikke-stationær bandit
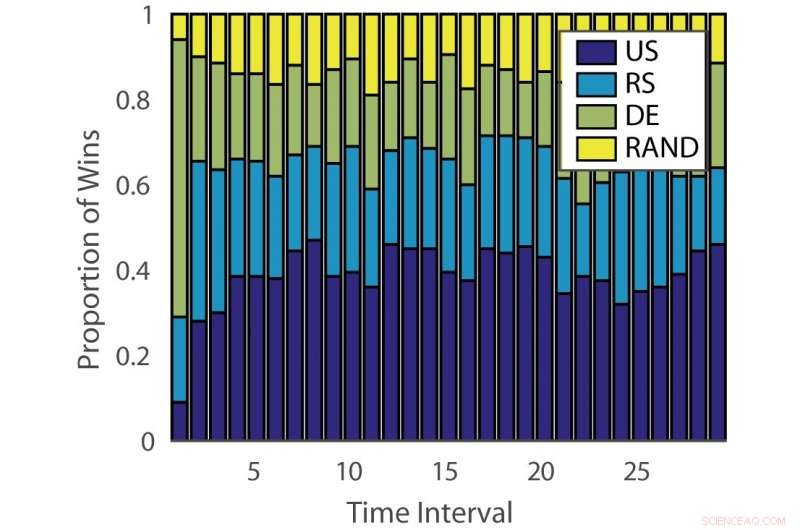
Andel af sejre:"ILPD". Kredit:Pang et al.
Forskere ved University of Edinburgh, University College London (UCL) og Nara Institute of Science and Technology har udviklet en ny ensemble aktiv læringstilgang baseret på en ikke-stationær flerarmet bandit og en ekspertrådgivningsalgoritme. Deres metode, præsenteret i et papir, der på forhånd er offentliggjort på arXiv, kunne reducere den tid og kræfter, der er investeret i den manuelle annotering af data.
"Konventionel overvåget maskinlæring er datahungrige, og mærkede data kan være en flaskehals, når dataanmelding er dyr, "Timothy Hospedales, en af forskerne, der gennemførte undersøgelsen, fortalte Tech Xplore. "Aktiv læring understøtter overvåget læring ved at forudsige de mest informative datapunkter, der skal kommenteres, så gode modeller kan trænes med et reduceret annotationsbudget."
Aktiv læring er et bestemt område inden for maskinlæring, hvor en læringsalgoritme aktivt kan vælge de data, den ønsker at lære af. Dette resulterer typisk i bedre ydeevne, med betydeligt mindre træningsdatasæt.
Forskere har udviklet en række aktive læringsalgoritmer, der kan reducere omkostningerne ved annotering, men indtil videre, ingen af disse løsninger har vist sig at være effektive til alle problemer. Andre undersøgelser har derfor brugt banditalgoritmer til at identificere den bedste aktive læringsalgoritme for et givet datasæt.
"Udtrykket 'bandit' refererer til en spilleautomat med flere arme, hvilket er en bekvem matematisk abstraktion til udforsknings-/udnyttelsesproblemer, "Hospedales forklaret." En banditalgoritme finder en god balance mellem indsats, der bruges på at udforske alle spillemaskiner for at finde ud af, hvilken der udbetaler mest, med indsats brugt på at udnytte den hidtil bedste spillemaskine. "
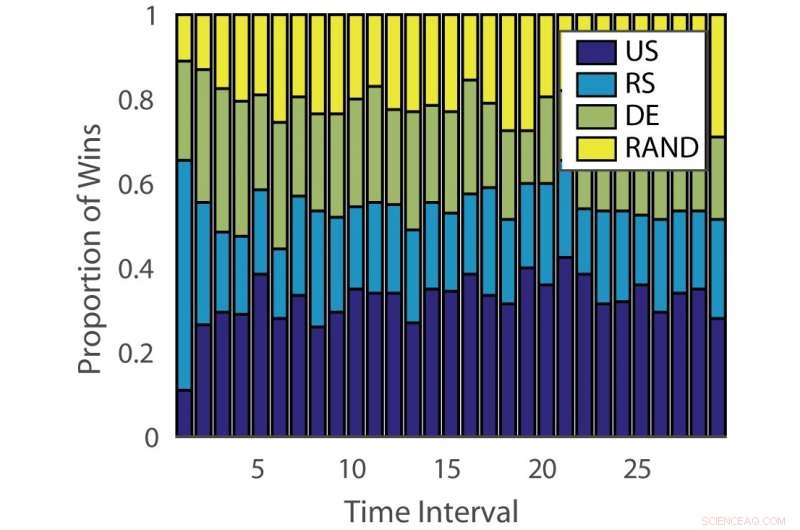
Andel af sejre:"tysk". Kredit:Pang et al.
Effekten af aktive læringsalgoritmer varierer både på tværs af problemer og over tid på forskellige stadier af læring. Denne observation er analog med at spille spilleautomater, hvor udbetalingssandsynligheden ændrer sig over tid.
"Formålet med vores undersøgelse var at udvikle en ny banditalgoritme, der forbedrer ydeevnen ved at tage højde for dette aspekt af det aktive læringsproblem, "Sagde Hospedales.
For at tackle denne begrænsning, forskerne foreslog et dynamisk ensemble active learner (DEAL) baseret på en ikke-stationær bandit. Denne elev opbygger et skøn over hver aktiv læringsalgoritms effektivitet online, baseret på belønningen (vigtighedsvægtet nøjagtighed) opnået efter hver annotering af data.
"Det gør dette ved at bruge præferencen udtrykt for det punkt ved hver aktiv læringsalgoritme, "Kunkun Pang, en anden forsker, der gennemførte undersøgelsen, fortalte Tech Xplore. "For at behandle spørgsmålet om den ændrede effekt af aktive elever over tid, vi genstarter med jævne mellemrum læringsalgoritmen for at opdatere dens aktive indlæringspræference. Med denne evne, hvis den mest effektive aktive læringsalgoritme skifter mellem tidlige og sene stadier af læring, vi kan hurtigt tilpasse os denne forandring. "
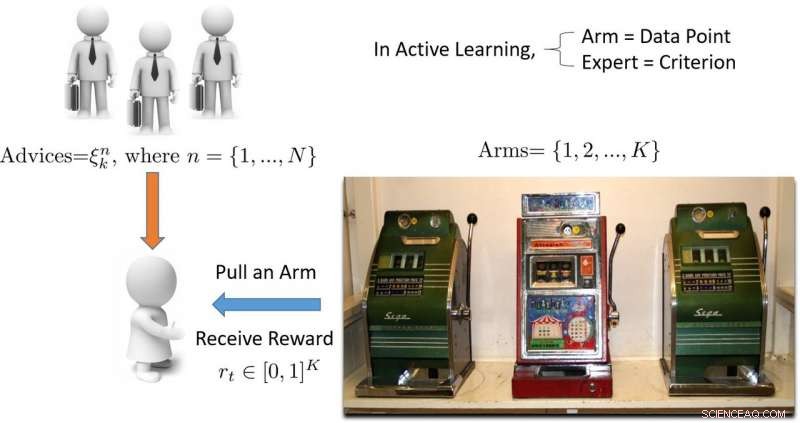
Illustration af flerarmet banditbaseret tilgang til aktiv læring. Kredit:Pang et al.
Forskerne testede deres tilgang på 13 populære datasæt, opnå meget opmuntrende resultater. Deres DEAL -algoritme har en matematisk ydelsesgaranti, hvilket betyder, at det er en høj grad af tillid til, hvor godt det vil fungere.
"Garantien vedrører ydelsen af vores algoritme, hvilket er det for et ideelt orakel, der altid kender det rigtige valg for den aktive elev, "Hospedales forklarede." Det giver en grænse for præstationsgabet mellem en sådan bedste case-algoritme og vores. "
Den empiriske evaluering foretaget af Hospedales og hans kolleger bekræftede, at deres DEAL -algoritme forbedrer den aktive læringspræstation på en række benchmarks. Det gør det ved løbende at identificere den mest effektive aktive læringsalgoritme til forskellige opgaver og på forskellige stadier af træning.
"I dag, mens aktiv læring er tiltalende, dens indvirkning på maskinlæringspraksis er begrænset på grund af besværet med at matche algoritmer til problemer og stadier af læring, "Hospedales sagde." DEAL eliminerer denne vanskelighed og giver en tilgang til at tackle mange problemer og alle stadier af læring. Ved at gøre aktiv læring lettere at bruge, vi håber, at det kan have en større indvirkning på at reducere annotationsomkostninger i maskinlæringspraksis. "
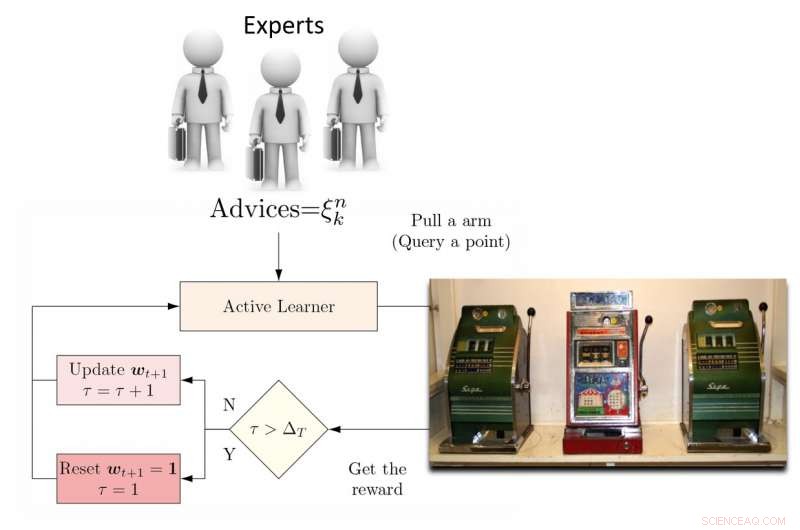
Illustration af DEAL REXP4 algoritme. Kredit:Pang et al.
På trods af de meget lovende resultater, teknikken, som forskerne har udtænkt, har stadig en betydelig begrænsning. DEAL udfører al læring inden for et enkelt problem, og dette resulterer i en 'kold start, 'hvilket betyder, at algoritmen nærmer sig alle nye problemer med en tom skifer.
"I det løbende arbejde, vi lærer at kommentere på mange forskellige problemer og til sidst overføre denne viden til et nyt problem, for straks at udføre en effektiv annotation uden krav til opvarmning, "Sagde Pang." Vores forarbejde om dette emne er blevet offentliggjort og vandt også prisen for bedste papir på ICML 2018 AutoML -workshop. "
© 2018 Science X Network
Sidste artikelDisse nye teknikker udsætter din browserhistorik for angribere
Næste artikelGM rapporterer om et stærkt overskud, løfte aktier
 Varme artikler
Varme artikler
-
 Undersøge batteri-hotspots for sikrere energilagringJo varmere et hotspot inde i et batteri, jo mere lithiummetalopbygning det tiltrækker, og jo mere modtageligt bliver batteriet for en kortslutning. Disse scanningselektronmikroskopbilleder viser denne
Undersøge batteri-hotspots for sikrere energilagringJo varmere et hotspot inde i et batteri, jo mere lithiummetalopbygning det tiltrækker, og jo mere modtageligt bliver batteriet for en kortslutning. Disse scanningselektronmikroskopbilleder viser denne -
 En ny tilgang til at løse fødevaresikkerhedsproblemer efter naturkatastroferKredit:Nozhati et al. Forskere ved Colorado State University (CSU) har udviklet en tilnærmet dynamisk programmeringstilgang til at forbedre fødevaresikkerheden i samfund, der er ramt af naturkatas
En ny tilgang til at løse fødevaresikkerhedsproblemer efter naturkatastroferKredit:Nozhati et al. Forskere ved Colorado State University (CSU) har udviklet en tilnærmet dynamisk programmeringstilgang til at forbedre fødevaresikkerheden i samfund, der er ramt af naturkatas -
 Tusindvis af svenskere indsætter mikrochips i sig selv – her er hvorforChips med alt. Kredit:www.shutterstock.com Tusindvis af mennesker i Sverige har indsat mikrochips, som kan fungere som kontaktløse kreditkort, nøglekort og endda jernbanekort, ind i deres kroppe.
Tusindvis af svenskere indsætter mikrochips i sig selv – her er hvorforChips med alt. Kredit:www.shutterstock.com Tusindvis af mennesker i Sverige har indsat mikrochips, som kan fungere som kontaktløse kreditkort, nøglekort og endda jernbanekort, ind i deres kroppe. -
 CES 2020:Hvis LGs rullebare OLED-tv lyder bekendt, der er en grundKredit:CC0 Public Domain Stjernen på sidste års CES var helt klart det Rollable OLED TV fra LG Display, valgt af CNET, Mashable og Reviewed.com som et af de hotteste produkter til CES 2019 – et tv
CES 2020:Hvis LGs rullebare OLED-tv lyder bekendt, der er en grundKredit:CC0 Public Domain Stjernen på sidste års CES var helt klart det Rollable OLED TV fra LG Display, valgt af CNET, Mashable og Reviewed.com som et af de hotteste produkter til CES 2019 – et tv
- Forskere finder molybdæn diselenid ikke så stærkt, som de troede
- Storm Ida -rester ramte nordøst i USA med oversvømmelser, tornadoer
- Mod nanorobotter, der svømmer gennem blod for at levere stoffer
- Fordybende etisk værktøj hjælper udviklere med at undgå dystopi af Internet of Things
- Indias IndiGo laver $ 33 mia. Mega-ordre på Airbus-jetfly
- #BlackGirlMagic:Sorte kvinder i STEM kører fremad – undervisere skal indhente det