


WaveGlow:Et flow-baseret generativt netværk til at syntetisere tale
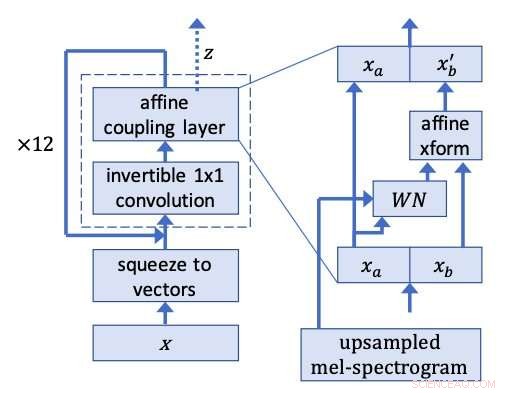
WaveGlow netværk. Kredit:Prenger, Valle, og Catanzaro.
Et team af forskere ved NVIDIA har for nylig udviklet WaveGlow, et flow-baseret netværk, der kan generere tale af høj kvalitet fra melspektrogrammer, som er akustiske tids-frekvensrepræsentationer af lyd. Deres metode, skitseret i et papir, der er forududgivet på arXiv, bruger et enkelt netværk trænet med en enkelt omkostningsfunktion, gør træningsproceduren nemmere og mere stabil.
"De fleste neurale netværk til at syntetisere tale var for langsomme for os, "Ryan Prenger, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "De var begrænset i hastighed, fordi de var designet til kun at generere én sample ad gangen. Undtagelserne var tilgange fra Google og Baidu, der genererede lyd meget hurtigt parallelt. Men, disse tilgange brugte lærernetværk og elevnetværk og var for komplekse til at replikere."
Forskerne hentede inspiration fra Glow, et flow-baseret netværk fra OpenAI, der kan generere billeder i høj kvalitet parallelt, bevare en ret simpel struktur. Ved at bruge en inverterbar 1x1 foldning, Glow opnåede bemærkelsesværdige resultater, producerer meget realistiske billeder. Forskerne besluttede at anvende den samme idé bag denne metode til talesyntese.
"Tænk på den hvide støj, der kommer fra en radio, der ikke er indstillet til nogen station, " Forklarede Prenger. At hvid støj er super nem at generere. Den grundlæggende idé med at syntetisere tale med WaveGlow er at træne et neuralt netværk til at transformere den hvide støj til tale. Hvis du bruger et hvilket som helst gammelt neuralt netværk, træning vil være problematisk. Men hvis du specifikt bruger et netværk, der kan køres baglæns såvel som fremad, matematikken bliver let, og nogle af træningsproblemerne forsvinder."
Forskerne kørte taleklip fra træningsdatasættet baglæns, træning af WaveGlow til at producere, hvad der ligner hvid støj. Deres model anvender den samme idé bag Glow til en WaveNet-lignende arkitektur, altså navnet WaveGlow.
I en PyTorch-implementering, WaveGlow producerede lydprøver med en hastighed på over 500 kHz, på en NVIDIA V100 GPU. Crowd-sourced mean opinion score (MOS) test på Amazon Mechanical Turk tyder på, at tilgangen leverer lydkvalitet lige så god som den bedste offentligt tilgængelige WaveNet-metode.
"I talesynteseverdenen, der er behov for modeller, der genererer tale mere end en størrelsesorden hurtigere i realtid, " sagde Prenger. "Vi håber, at WaveGlow kan opfylde dette behov og samtidig være nemmere at implementere og vedligeholde end andre eksisterende modeller. I den dybe læringsverden, vi tror, at denne type tilgang, der bruger et invertibelt neuralt netværk og den resulterende simple tabsfunktion, er relativt understuderet. WaveGlow giver endnu et eksempel på, hvordan denne tilgang kan give generative resultater af høj kvalitet på trods af dens relative enkelhed."
WaveGlows kode er let tilgængelig online og kan tilgås af andre, der ønsker at prøve den eller eksperimentere med den. I mellemtiden forskerne arbejder på at forbedre kvaliteten af syntetiserede lydklip ved at finjustere deres model og udføre yderligere evalueringer.
"Vi har ikke lavet en masse analyser for at se, hvor lille et netværk vi kan slippe af sted med, " sagde Prenger. "De fleste af vores arkitekturbeslutninger var baseret på meget tidlige dele af træningen. Imidlertid, mindre netværk med længere træningstid kan generere lige så god lyd. Der er mange interessante retninger, som denne forskning kan gå i fremtiden."
© 2018 Science X Network
 Varme artikler
Varme artikler
-
 Endelig, en simpel 3-D printer til metalEn prøvedel printet fra bulk metallisk glas via den TPF-baserede FFF-proces. Kredit:Elsevier Bruges til at fremstille tredimensionelle objekter af næsten enhver type, på tværs af en række brancher
Endelig, en simpel 3-D printer til metalEn prøvedel printet fra bulk metallisk glas via den TPF-baserede FFF-proces. Kredit:Elsevier Bruges til at fremstille tredimensionelle objekter af næsten enhver type, på tværs af en række brancher -
 Dell øger markedsandelen i det svækkede globale pc-markedKredit:CC0 Public Domain Efterhånden som verdensomspændende pc-forsendelser falder, de tre bedste leverandører – Lenovo, HP Inc. og Dell Technologies – øgede deres andel af det globale pc-marked i
Dell øger markedsandelen i det svækkede globale pc-markedKredit:CC0 Public Domain Efterhånden som verdensomspændende pc-forsendelser falder, de tre bedste leverandører – Lenovo, HP Inc. og Dell Technologies – øgede deres andel af det globale pc-marked i -
 Toyota annoncerer ny tilbagekaldelse af 2,4 millioner hybridbilerDen seneste tilbagekaldelse påvirker flere modeller af Toyotas Prius og Auris hybridkøretøjer produceret mellem oktober 2008 og november 2014 Den japanske bilgigant Toyota sagde fredag, at den til
Toyota annoncerer ny tilbagekaldelse af 2,4 millioner hybridbilerDen seneste tilbagekaldelse påvirker flere modeller af Toyotas Prius og Auris hybridkøretøjer produceret mellem oktober 2008 og november 2014 Den japanske bilgigant Toyota sagde fredag, at den til -
 Bitcoin -udveksling bringer teknologichefen til sigCameron og Tyler Winklevoss, set ved premieren på filmen Oceans 8 i New York, har søgt at gøre bitcoin mere populær med deres udveksling kaldet Gemini En bitcoin -børs ledet af Cameron og Tyler Wi
Bitcoin -udveksling bringer teknologichefen til sigCameron og Tyler Winklevoss, set ved premieren på filmen Oceans 8 i New York, har søgt at gøre bitcoin mere populær med deres udveksling kaldet Gemini En bitcoin -børs ledet af Cameron og Tyler Wi
- Toyotas globale bilsalg i 2019 følger Volkswagens
- Egyptiske mumier viste sig at have de ældste figurative tatoveringer
- Hvad er en ubalanceret kraft?
- Hvordan man taler med folk om klimaændringer
- Fordele og ulemper ved at bruge Propane
- Nanostrukturer bliver bedre til at høste sollys til generering af soldamp