


Fortolkbarhed og ydeevne:Kan den samme model opnå begge dele?
Kredit:IBM
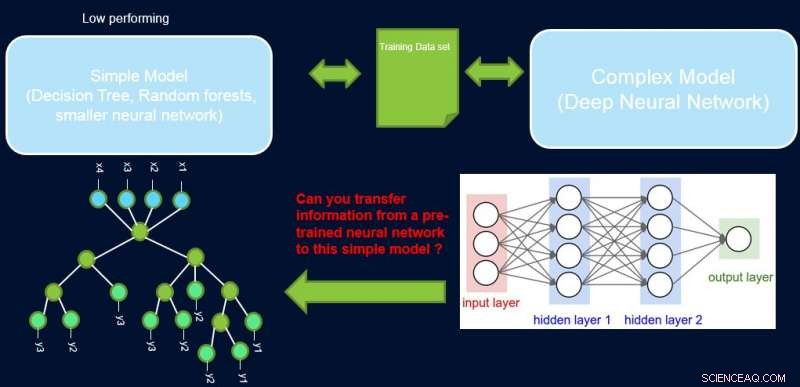
Fortolkning og ydeevne af et system er normalt i modstrid med hinanden, da mange af de bedst performende modeller (dvs. dybe neurale netværk) er black box i naturen. I vores arbejde, Forbedring af simple modeller med tillidsprofiler, vi forsøger at bygge bro over dette hul ved at foreslå en metode til at overføre oplysninger fra et højtydende neuralt netværk til en anden model, som domæneeksperten eller applikationen kan kræve. For eksempel, inden for beregningsbiologi og økonomi, sparsomme lineære modeller foretrækkes ofte, mens i komplekse instrumenterede domæner såsom halvlederfremstilling, ingeniørerne foretrækker måske at bruge beslutningstræer. Sådanne enklere fortolkbare modeller kan opbygge tillid hos eksperten og give nyttig indsigt, der fører til opdagelse af nye og tidligere ukendte fakta. Vores mål er afbildet nedenfor, for et specifikt tilfælde, hvor vi forsøger at forbedre udførelsen af et beslutningstræ.
Antagelsen er, at vores netværk er en højtydende lærer, og vi kan bruge nogle af dens oplysninger til at lære det enkle, fortolkelig, men generelt lavpresterende elevmodel. Vægtning af prøver efter deres vanskeligheder kan hjælpe den enkle model med at fokusere på lettere prøver, som den med succes kan modellere, når den træner, og dermed opnå en bedre samlet ydelse. Vores setup er anderledes end boost:i den tilgang, vanskelige eksempler med hensyn til en tidligere 'svag' elev fremhæves for efterfølgende træning for at skabe mangfoldighed. Her, vanskelige eksempler er med hensyn til en nøjagtig kompleks model. Det betyder, at disse etiketter er næsten tilfældige. I øvrigt, hvis en kompleks model ikke kan løse disse, der er lidt håb for den enkle model med fast kompleksitet. Derfor, det er vigtigt i vores setup at fremhæve lette eksempler, som den simple model kan løse.
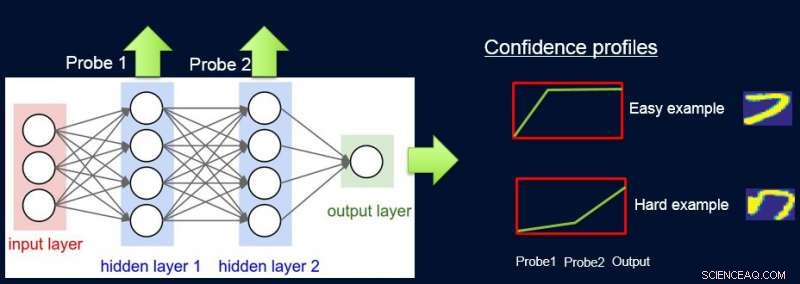
At gøre dette, vi tildeler vægte til prøver i henhold til netværkets vanskeligheder med at klassificere dem, og vi gør dette ved at introducere sonder. Hver sonde tager sit input fra et af de skjulte lag. Hver sonde har et enkelt fuldt forbundet lag med et softmax -lag i størrelsen på netværksoutputtet, der er knyttet til det. Sonden i lag i fungerer som en klassifikator, der kun bruger netværksets præfiks op til lag i. Antagelsen er, at lette instanser vil blive klassificeret korrekt med høj tillid, selv med prober i første lag, og så får vi tillidsniveauer s jeg fra alle sonder for hver af instanserne. Vi bruger alle s jeg at beregne instansproblemer w jeg , f.eks. som arealet under kurven (AUC) på s jeg 's.
Nu kan vi bruge vægtene til at omskole den simple model på det endelige vægtede datasæt. Vi kalder denne pipeline for sondering, opnå tillidsvægte, og genuddannelse af ProfWeight.
Kredit:IBM
Vi præsenterer to alternativer til, hvordan vi beregner vægte til eksempler i datasættet. I AUC -metoden nævnt ovenfor, vi noterer valideringsfejlen/nøjagtigheden af den simple model, når den blev trænet på det originale træningssæt. Vi vælger prober, der har en nøjagtighed på mindst α (> 0) større end den simple model. Hvert eksempel vægtes baseret på den gennemsnitlige konfidensscore for den sande etiket, der beregnes ved hjælp af de individuelle bløde forudsigelser fra sonderne.
Et andet alternativ indebærer optimering ved hjælp af et neuralt netværk. Her lærer vi optimale vægte til træningssættet ved at optimere følgende mål:
S*=min w min β E [λ (Swβ (x), y)], sub. til. E [w] =1
hvor w er vægten for hver instans, β betegner parameterrummet for den simple model S, og λ er dens tabsfunktion. Vi er nødt til at begrænse vægten, da den trivielle løsning af alle vægte, der går til nul, ellers vil være optimal for ovenstående mål. Vi viser i avisen, at vores begrænsning af E [w] =1 har en forbindelse til at finde den optimale betydningsprøveudtagning.
Kredit:IBM
Mere generelt kan ProfWeight bruges til at overføre til endnu enklere, men uigennemsigtige modeller, såsom mindre neurale netværk, som kan være nyttig i domæner med svær hukommelse og strømbegrænsninger. Sådanne begrænsninger opleves ved implementering af modeller på kantudstyr i IoT -systemer eller på mobile enheder eller på ubemandede luftfartøjer.
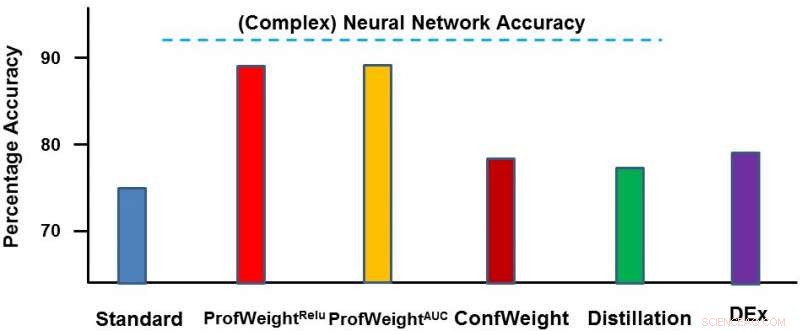
Vi testede vores metode på to domæner:et offentligt billedsætdatasæt CIFAR-10 og et proprietært produktionsdatasæt. På det første datasæt, vores enkle modeller var mindre neurale netværk, der ville overholde strenge hukommelses- og strømbegrænsninger, og hvor vi oplevede en forbedring på 3-4 procent. På det andet datasæt, vores enkle model var et beslutningstræ, og vi forbedrede det betydeligt med ~ 13 procent, hvilket førte til praktiske resultater af ingeniøren. Nedenfor viser vi ProfWeight i sammenligning med de andre metoder på dette datasæt. Vi observerer her, at vi med en vis margin overgår de andre metoder.
I fremtiden vil vi gerne finde nødvendige/tilstrækkelige betingelser, når overførsel med vores strategi ville resultere i forbedring af enkle modeller. Vi vil også gerne udvikle mere sofistikerede metoder til informationsoverførsel, end hvad vi allerede har opnået.
Vi vil præsentere dette arbejde i et papir med titlen "Forbedring af simple modeller med tillidsprofiler" på konferencen om neurale informationsbehandlingssystemer 2018, på onsdag, 5. december kl. under aftenplakatsessionen fra 17.00 til 19.00 i værelse 210 &230 AB (#90).
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
Sidste artikelTumblr forbyder porno for at rydde op i blogplatformen
Næste artikelNye farvesensorer er billigere at fremstille
 Varme artikler
Varme artikler
-
 Endimensionelle objekter forvandles til nye dimensionerKredit:Carnegie Mellon University En linje er den korteste afstand mellem to punkter, men A-linje, et 4-D printsystem udviklet ved Carnegie Mellon University, tager en mere kringlet vej. Endimensi
Endimensionelle objekter forvandles til nye dimensionerKredit:Carnegie Mellon University En linje er den korteste afstand mellem to punkter, men A-linje, et 4-D printsystem udviklet ved Carnegie Mellon University, tager en mere kringlet vej. Endimensi -
 Texas Instruments nye administrerende direktør mister jobbet på grund af personlige forseelserDenne mandag, 22. oktober kl. 2012, filfoto viser virksomhedens skiltning på kontorer i Texas Instruments, i Richardson, Texas. På tirsdag, 17. juli kl. 2018, Texas Instruments dumpede administrerende
Texas Instruments nye administrerende direktør mister jobbet på grund af personlige forseelserDenne mandag, 22. oktober kl. 2012, filfoto viser virksomhedens skiltning på kontorer i Texas Instruments, i Richardson, Texas. På tirsdag, 17. juli kl. 2018, Texas Instruments dumpede administrerende -
 Uber viser et tab på 1 mia. USD i 1. kvartal på stigende omsætningUber CEO Dara Khosrowshahi siger, at virksomheden er på en lang rejse for at blive en platform for bevægelse af mennesker og transport af handel rundt om i verden i massiv skala Køreandelsgiganten
Uber viser et tab på 1 mia. USD i 1. kvartal på stigende omsætningUber CEO Dara Khosrowshahi siger, at virksomheden er på en lang rejse for at blive en platform for bevægelse af mennesker og transport af handel rundt om i verden i massiv skala Køreandelsgiganten -
 Ny tilgang kan øge litiumbatteriers energikapacitetMolekyldiagram viser strukturen af molybdænsulfid, et af de materialer, der bruges til at skabe den nye slags katode til lithium-svovl-batterier. Kredit:Massachusetts Institute of Technology For
Ny tilgang kan øge litiumbatteriers energikapacitetMolekyldiagram viser strukturen af molybdænsulfid, et af de materialer, der bruges til at skabe den nye slags katode til lithium-svovl-batterier. Kredit:Massachusetts Institute of Technology For
- Kinas nye Long March-8 raket laver første flyvning
- Stalagmit har nøglen til at forudsige tørke, oversvømmelser for Indien
- Spinbølge-detektivhistorie redux:Forskere finder mere overraskende adfærd i en 2-D magnet
- Kaster nyt lys på organiske solcellers elektronmotorveje
- Ny metode inverterer selvsamling af flydende krystaller
- Forskere bruger naturens designprincipper til at skabe specialiserede nanostoffer