


Data mining syndromer
Med hver nyhed, begreberne data mining sundhedsinformation rykker stadig højere op på forsknings- og politikdagsordenen på dette område. Klinisk information og genetiske data indeholdt i elektroniske sundhedsjournaler (EPJ'er) repræsenterer en vigtig kilde til nyttig information til biomedicinsk forskning, men det kan være svært at få adgang til dem på en nyttig måde.
Skriver i International Journal of Intelligent Engineering Informatics, Hassan Mahmoud og Enas Abbas fra Benha University og Ibrahim Fathy Ain Shams University, i Egypten, diskutere behovet for innovative og effektive metoder til at repræsentere denne enorme mængde data. De påpeger, at der er data mining-teknikker såvel som ontologi-baserede teknikker, der kan spille en stor rolle i at opdage syndromer hos patienter effektivt og præcist. Et syndrom er defineret som et sæt af samtidige medicinske symptomer og indikatorer forbundet med en given sygdom eller lidelse.
Holdet har gennemgået det nyeste og fokuseret på at gennemgå de velkendte data mining-teknikker såsom beslutningstræer (J48), Naive Bayes, flerlagsperceptron (MLP), og random forest (RF) teknikker og sammenlignet, hvor godt de hver især klarer sig i klassificeringen af et bestemt syndrom, hjerte sygdom.
Holdet konkluderer, at i eksperimenter med et offentligt datasæt, RF-klassifikatoren giver den bedste ydeevne med hensyn til nøjagtighed. I fremtiden, de antyder, at datamining vil gavne sundhedsvæsenet og medicinen væsentligt for opbygningen af et system, der er i stand til at opdage et specifikt syndrom.
 Varme artikler
Varme artikler
-
 Elon Musk siger, at han afbryder forbindelsen til TwitterElon Musk, billedet den 10. oktober, skrev på Twitter, at han går offline Tesla -chef Elon Musk affyrede fredag et tweet, der indikerer, at han afbryder forbindelsen til Twitter, måske til forde
Elon Musk siger, at han afbryder forbindelsen til TwitterElon Musk, billedet den 10. oktober, skrev på Twitter, at han går offline Tesla -chef Elon Musk affyrede fredag et tweet, der indikerer, at han afbryder forbindelsen til Twitter, måske til forde -
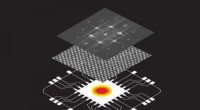 Ingeniører udvikler verdens mest effektive halvledere til termisk styringIllustration, der viser et skematisk billede af en computerchip med et hotspot (nederst); et elektronmikroskopbillede af defektfrit borarsenid (midten); og et billede, der viser elektrondiffraktionsmø
Ingeniører udvikler verdens mest effektive halvledere til termisk styringIllustration, der viser et skematisk billede af en computerchip med et hotspot (nederst); et elektronmikroskopbillede af defektfrit borarsenid (midten); og et billede, der viser elektrondiffraktionsmø -
 Autonome køretøjsfirma Waymo tester i Florida-regnI denne 27. marts, 2018 filbillede, Jaguar I-Pace-køretøjet udstyret med Waymos række af sensorer og radar introduceres i New York. Googles spinoff for autonome køretøjer Waymo siger, at det vil begyn
Autonome køretøjsfirma Waymo tester i Florida-regnI denne 27. marts, 2018 filbillede, Jaguar I-Pace-køretøjet udstyret med Waymos række af sensorer og radar introduceres i New York. Googles spinoff for autonome køretøjer Waymo siger, at det vil begyn -
 To-benet robot efterligner menneskelig balance, mens du løber og hopperJoao Ramos teleopererer Little HERMES, en tobenet robot, der kan efterligne en operatørs balance for at forblive oprejst under løb, gå, og hopper på plads. Kredit:Joao Ramos og Sangbae Kim Redning
To-benet robot efterligner menneskelig balance, mens du løber og hopperJoao Ramos teleopererer Little HERMES, en tobenet robot, der kan efterligne en operatørs balance for at forblive oprejst under løb, gå, og hopper på plads. Kredit:Joao Ramos og Sangbae Kim Redning
- Hvad er lav tæthed?
- Hvor er alle Aquanauts blevet af? Historien om Sealab
- Hvorfor levede 70% af de gamle Ural-bebyggelsers indbyggere ikke op til 18-årsalderen
- Stærkt jordskælv ryster det vestlige Indonesien; ingen tsunamialarm
- Kan videnskaben forklare, hvorfor vi kysser med lukkede øjne?
- Kulstof nanorør strukturer ændret ved angreb indefra, opdager forskere