


En ny tilgang til lav-ressource maskintranslitteration ved hjælp af RNN'er
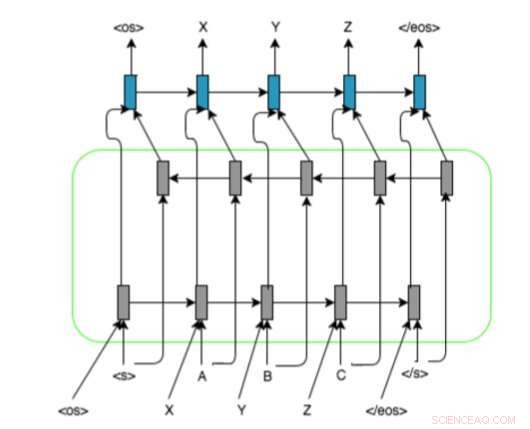
Forskernes RNN-baserede modelarkitektur med encoder-decoder tovejs LSTM og alignment-repræsentation på inputsekvenser. De bruger og, , og markører til at fylde grafem/fonem-sekvenserne til en fast længde. Kredit:Ngoc Tan Le et al.
Et team af forskere ved Universite du Quebec a Montreal og Vietnam National University Ho Chi Minh (VNU-HCM) har for nylig udviklet en tilgang til maskintranslitteration baseret på tilbagevendende neurale netværk (RNN'er). Translitteration indebærer fonetisk oversættelse af ord på et givet kildesprog (f.eks. fransk) til tilsvarende ord på et målsprog (f.eks. vietnamesisk).
Via translitteration, et enkelt ord omdannes til et fonetisk ækvivalent ord i et andet skriftsystem. Denne transformation er typisk afhængig af et stort sæt regler defineret af lingvister, som bestemmer, hvordan fonemer er justeret, i betragtning af et ords oprindelse og målsprogets fonologiske system.
I de seneste år, forskere har udviklet flere deep learning-tilgange til maskinoversættelse, som har vist sig at være et værdifuldt alternativ til eksisterende statistiske tilgange. Disse lovende resultater motiverede teamet af forskere ved Universite du Quebec a Montreal og VNU-HCM til at udvikle en dyb læringstilgang til maskintranslitteration.
Deres tilgang bruger tilbagevendende neurale netværk (RNN'er), da disse har vist sig at være særligt nyttige til at håndtere lignende problemer. Forskerne observerede, at de fleste avancerede grafem-til-fonem-metoder primært var baseret på brugen af grafem-fonem-kortlægninger, mens RNN'er ikke kræver nogen tilpasningsinformation.
"Grafem-til-fonem-modeller er nøglekomponenter i automatisk talegenkendelse og tekst-til-tale-systemer, " forklarede forskerne i deres papir, som blev udgivet på ACM Digital Library. "Med lav-ressource sprogpar, der ikke har tilgængelige og veludviklede udtaleleksikoner, grafem-til-fonem-modeller er særligt nyttige. Disse modeller er baseret på indledende tilpasninger mellem grafemkilde og fonemmålsekvenser."
I deres undersøgelse, forskerne introducerede en ny metode til at opnå lav-ressource maskintranslitteration, som bruger RNN-baserede modeller og alignmentinformation til inputsekvenser. Givet et ord på et givet sprog, som ikke findes i den tosprogede udtaleordbog, deres system kan automatisk forudsige sin fonemiske repræsentation på målsproget.
"Inspireret af sekvens-til-sekvens tilbagevendende neurale netværk-baserede oversættelsesmetoder, den nuværende forskning præsenterer en tilgang, der anvender en tilpasningsrepræsentation for inputsekvenser og forudtrænede kilde- og målindlejringer for at overvinde translitterationsproblemet for et sprogpar med lav ressource, " forklarede forskerne i deres papir.
Denne nye tilgang kombinerer flere dyb læring og neurale netværksbaserede teknikker, inklusive encoder-dekodere, opmærksomhedsmekanismer, alignment-repræsentation for inputsekvenser og forudtrænede kilde- og målindlejringer. Forskerne evaluerede deres metode i en translitterationsopgave, der involverede fransk-vietnamesiske sprogpar med lav ressource, opnår meget lovende resultater.
"Evaluering og eksperimenter, der involverede fransk og vietnamesisk, viste, at med kun en lille tosproget udtaleordbog tilgængelig til træning af translitterationsmodellerne, lovende resultater blev opnået, " skrev forskerne.
Ifølge forskerne, deres undersøgelse var blandt de første til at analysere det vietnamesiske sprog i en translitterationsopgave ved hjælp af RNN'er. Deres metode opnåede bemærkelsesværdige resultater, udkonkurrere andre state-of-the-art statistisk-baserede og multijoint sekvens-baserede tilgange.
Det nye system, som forskerne har udtænkt, kan effektivt og automatisk lære sproglige regelmæssigheder fra små tosprogede udtaleordbøger. Selvom deres undersøgelse specifikt anvendte det til fransk-vietnamesiske translitterationsopgaver, den kunne også udvides til andre sprogpar med lav ressource, for hvilke der findes en tosproget udtaleordbog.
"I det fremtidige arbejde, vi agter at teste vores foreslåede tilgang med en større tosproget udtaleordbog samt at studere andre tilgange, såsom semi-overvåget eller ikke-overvåget, " skrev forskerne i deres papir. "Vi har også til hensigt at undersøge overførselslæring ved hjælp af andre NLP-opgaver eller sprog i miljøer med lav ressource."
© 2019 Science X Network
Sidste artikelCoda 1.0:Wowza, en doc, borde, faner, knapper, og gå team
Næste artikelLyft tilbyder elbiler til ryttere, chauffører
 Varme artikler
Varme artikler
-
 Før Nintendo og Atari:Den sorte ingeniør, der ændrede videospil for altidKredit:CC0 Public Domain Atari. Magnavox. Intellivision. Hver vækker minder om videospils guldalder, som bragte den første bølge af konsoller, du kunne tilslutte til dit hjemme-tv. Men der er e
Før Nintendo og Atari:Den sorte ingeniør, der ændrede videospil for altidKredit:CC0 Public Domain Atari. Magnavox. Intellivision. Hver vækker minder om videospils guldalder, som bragte den første bølge af konsoller, du kunne tilslutte til dit hjemme-tv. Men der er e -
 Forskere bekræfter endelig en 50-årig teori inden for mekanikRotoren med luftsmurede lejer og ryster system © EPFL 2020 Et eksperiment af EPFL -forskere har bekræftet en teori, der har været brugt i mekanik i over et halvt århundrede - på trods af at den al
Forskere bekræfter endelig en 50-årig teori inden for mekanikRotoren med luftsmurede lejer og ryster system © EPFL 2020 Et eksperiment af EPFL -forskere har bekræftet en teori, der har været brugt i mekanik i over et halvt århundrede - på trods af at den al -
 Elektroniske klistermærker til at strømline storstilet internet af tingElektroniske klistermærker kan forvandle almindelige legetøjsblokke til højteknologiske sensorer på tingenes internet. Kredit:Purdue University /Chi Hwan Lee Milliarder af objekter lige fra smartp
Elektroniske klistermærker til at strømline storstilet internet af tingElektroniske klistermærker kan forvandle almindelige legetøjsblokke til højteknologiske sensorer på tingenes internet. Kredit:Purdue University /Chi Hwan Lee Milliarder af objekter lige fra smartp -
 Chinas Silk Road -projekt løber ind i gældskøerKinas præsident Xi Jinping siger, at handelen med bælte- og vejlande har oversteget $ 5 billioner Kinas massive og ekspanderende handelsinfrastrukturprojekt Bælte og vej løber ind i hastighedsstød
Chinas Silk Road -projekt løber ind i gældskøerKinas præsident Xi Jinping siger, at handelen med bælte- og vejlande har oversteget $ 5 billioner Kinas massive og ekspanderende handelsinfrastrukturprojekt Bælte og vej løber ind i hastighedsstød