


De fleste amerikanere er ikke klar over, hvad virksomheder kan forudsige ud fra deres data

Hvad ved din telefon om dig? Kredit:Rawpixel.com/Shutterstock.com
67 procent af smartphonebrugere er afhængige af Google Maps for at hjælpe dem med at komme derhen, hvor de er på vej hurtigt og effektivt.
En vigtig funktion ved Google Maps er dens evne til at forudsige, hvor lang tid forskellige navigationsruter vil tage. Det er muligt, fordi mobiltelefonen på hver person, der bruger Google Maps, sender data om dens placering og hastighed tilbage til Googles servere, hvor det analyseres for at generere nye data om trafikforhold.
Information som denne er nyttig til navigation. Men nøjagtig de samme data, som bruges til at forudsige trafikmønstre, kan også bruges til at forudsige andre former for information – information, som folk måske ikke er fortrolige med at afsløre.
For eksempel, data om en mobiltelefons tidligere placering og bevægelsesmønstre kan bruges til at forudsige, hvor en person bor, hvem deres arbejdsgiver er, hvor de deltager i gudstjenester og deres børns aldersgruppe baseret på, hvor de afleverer dem i skole.
Disse forudsigelser markerer, hvem du er som person, og gæt, hvad du sandsynligvis vil gøre i fremtiden. Forskning viser, at folk stort set ikke er klar over, at disse forudsigelser er mulige, og, hvis de bliver opmærksomme på det, kan ikke lide det. Efter min mening, som en, der studerer, hvordan forudsigende algoritmer påvirker folks privatliv, det er et stort problem for digitalt privatliv i USA.
Hvordan er det hele muligt?
Hver enhed du bruger, hver virksomhed du handler med, hver online konto, du opretter, eller loyalitetsprogram, du tilmelder dig, og endda regeringen selv indsamler data om dig.
Den slags data, de indsamler, omfatter ting som dit navn, adresse, alder, CPR- eller kørekortnummer, købstransaktionshistorik, web browsing aktivitet, vælgerregistreringsoplysninger, uanset om du har børn, der bor hos dig eller taler et fremmedsprog, de billeder du har lagt ud på sociale medier, salgsprisen på dit hjem, om du for nylig har haft en livsbegivenhed som at blive gift, din kredit score, hvilken slags bil du kører, hvor meget du bruger på dagligvarer, hvor meget kreditkortgæld du har og placeringshistorikken fra din mobiltelefon.
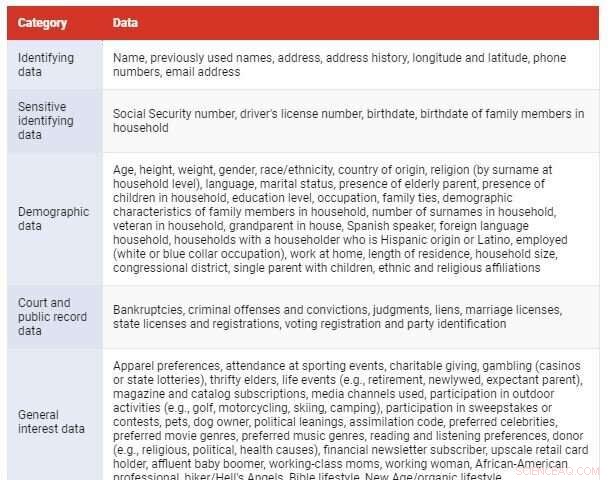
Kredit:Samtalen
Det er ligegyldigt, om disse datasæt blev indsamlet separat af forskellige kilder og ikke indeholder dit navn. Det er stadig nemt at matche dem efter andre oplysninger om dig, som de indeholder.
For eksempel, der er identifikatorer i offentlige registerdatabaser, gerne dit navn og hjemmeadresse, der kan matches med GPS-placeringsdata fra en app på din mobiltelefon. Dette giver en tredjepart mulighed for at forbinde din hjemmeadresse med det sted, hvor du tilbringer det meste af dine aften- og nattetimer - formentlig der, hvor du bor. Det betyder, at appudvikleren og dens partnere har adgang til dit navn, selvom du ikke direkte gav dem det.
I USA, de virksomheder og platforme, du interagerer med, ejer de data, de indsamler om dig. Det betyder, at de lovligt kan sælge disse oplysninger til datamæglere.
Datamæglere er virksomheder, der er i gang med at købe og sælge datasæt fra en bred vifte af kilder, herunder placeringsdata fra mange mobiltelefonudbydere. Datamæglere kombinerer data for at skabe detaljerede profiler af individuelle personer, som de sælger til andre virksomheder.
Kombinerede datasæt som dette kan bruges til at forudsige, hvad du vil købe for at målrette annoncer. For eksempel, en virksomhed, der har købt data om dig, kan gøre ting som at forbinde dine sociale medier-konti og browserhistorik med den rute, du tager, når du kører ærinder, og din købshistorik i din lokale købmand.
Arbejdsgivere bruger store datasæt og forudsigelige algoritmer til at træffe beslutninger om, hvem der skal interviewes til job og forudsige, hvem der kan stoppe. Politiafdelinger laver lister over personer, der kan være mere tilbøjelige til at begå voldelige forbrydelser. FICO, det samme firma, der beregner kreditscore, beregner også en "medicinoverholdelsesscore", der forudsiger, hvem der vil stoppe med at tage deres receptpligtige medicin.
Hvor bevidste er folk om dette?
Selvom folk måske er klar over, at deres mobiltelefoner har GPS, og at deres navn og adresse er i en offentlig registerdatabase et sted, det er langt mindre sandsynligt, at de indser, hvordan deres data kan kombineres for at lave nye forudsigelser. Det skyldes, at privatlivspolitikker typisk kun omfatter vagt sprog om, hvordan data, der er indsamlet, vil blive brugt.
I en undersøgelse fra januar Pew Internet and American Life-projektet spurgte voksne Facebook-brugere i USA om de forudsigelser, Facebook kommer med om deres personlige træk, baseret på data indsamlet af platformen og dens partnere. For eksempel, Facebook tildeler en "multikulturel affinitet" kategori til nogle brugere, at gætte på, hvor ens de er med mennesker med forskellig race eller etnisk baggrund. Disse oplysninger bruges til at målrette annoncer.
Undersøgelsen viste, at 74 procent af befolkningen ikke kendte til disse forudsigelser. Omkring halvdelen sagde, at de ikke er komfortable med, at Facebook forudsiger information som denne.
I min forskning, Jeg har opdaget, at folk kun er opmærksomme på forudsigelser, der vises til dem i en apps brugergrænseflade, og det giver mening i betragtning af grunden til, at de besluttede at bruge appen. For eksempel, en undersøgelse fra 2017 af fitness tracker-brugere viste, at folk er klar over, at deres tracker-enhed indsamler deres GPS-position, når de træner. Men dette oversættes ikke til bevidsthed om, at aktivitetsmålerfirmaet kan forudsige, hvor de bor.
I en anden undersøgelse, Jeg fandt ud af, at brugere af Google Søgning ved, at Google indsamler data om deres søgehistorik, og Facebook-brugere er klar over, at Facebook ved, hvem deres venner er. Men folk ved ikke, at deres Facebook "synes godt om" kan bruges til præcist at forudsige deres politiske partitilhørsforhold eller seksuelle orientering.
Hvad kan man gøre ved dette?
Nutidens internet er i høj grad afhængig af, at folk administrerer deres eget digitale privatliv.
Virksomheder beder folk på forhånd om at give samtykke til systemer, der indsamler data og foretager forudsigelser om dem. Denne tilgang ville fungere godt til at administrere privatlivets fred, hvis folk nægtede at bruge tjenester, der har privatlivspolitikker, de ikke kan lide, og hvis virksomheder ikke ville overtræde deres egne privatlivspolitikker.
Men forskning viser, at ingen læser eller forstår disse privatlivspolitikker. Og, selv når virksomheder står over for konsekvenser for at bryde deres løfter om privatlivets fred, det forhindrer dem ikke i at gøre det igen.
At kræve, at brugere giver samtykke uden at forstå, hvordan deres data vil blive brugt, giver også virksomheder mulighed for at flytte skylden over på brugeren. Hvis en bruger begynder at føle, at deres data bliver brugt på en måde, som de faktisk ikke er fortrolig med, de har ikke plads til at klage, fordi de har givet samtykke, ret?
Efter min mening, der er ingen realistisk måde for brugere at være opmærksomme på den slags forudsigelser, der er mulige. Folk forventer naturligvis, at virksomheder kun bruger deres data på måder, der er relateret til de grunde, de havde til at interagere med virksomheden eller appen i første omgang. Men virksomheder er normalt ikke juridisk forpligtet til at begrænse den måde, de bruger folks data på, til kun at omfatte ting, som brugerne ville forvente.
En undtagelse er Tyskland, hvor Federal Cartel Office afgjorde den 7. februar, at Facebook specifikt skal bede sine brugere om tilladelse til at kombinere data indsamlet om dem på Facebook med data indsamlet fra tredjeparter. Dommen slår også fast, at hvis folk ikke giver deres tilladelse til dette, de burde stadig kunne bruge Facebook.
Jeg mener, at USA har brug for stærkere privatlivsrelateret regulering, så virksomheder bliver mere gennemsigtige og ansvarlige over for brugerne om ikke kun de data, de indsamler, men også den slags forudsigelser, de genererer ved at kombinere data fra flere kilder.
Denne artikel er genudgivet fra The Conversation under en Creative Commons-licens. Læs den originale artikel. 
 Varme artikler
Varme artikler
-
 Amazon fremhævede som en stor sejr for NY, men matematik er mere komplekstI denne 13. november, 2018, fil foto, en måge flyver af sted med fiskerester i nærheden af et tidligere havneanlæg, med Long Island malet på gamle overførselsbroer i Gantry State Park i Long Island
Amazon fremhævede som en stor sejr for NY, men matematik er mere komplekstI denne 13. november, 2018, fil foto, en måge flyver af sted med fiskerester i nærheden af et tidligere havneanlæg, med Long Island malet på gamle overførselsbroer i Gantry State Park i Long Island -
 Californien sigter mod at blive kulstoffri i 2045 – er det muligt?Diagram:Samtalen, CC-BY-ND Kilde:California Energy Commission Californiens guvernør Jerry Brown har underskrevet en ny lov, der påbyder, at den elektricitet, staten forbruger, ikke forårsager kuls
Californien sigter mod at blive kulstoffri i 2045 – er det muligt?Diagram:Samtalen, CC-BY-ND Kilde:California Energy Commission Californiens guvernør Jerry Brown har underskrevet en ny lov, der påbyder, at den elektricitet, staten forbruger, ikke forårsager kuls -
 Stanfords ingeniører skaber formændrende, fritgående blød robotSet ovenfra af den isoperimetriske robot, der griber og håndterer en basketball. Kredit:Farrin Abbott Fremskridt inden for blød robotik kunne en dag tillade robotter at arbejde sammen med menneske
Stanfords ingeniører skaber formændrende, fritgående blød robotSet ovenfra af den isoperimetriske robot, der griber og håndterer en basketball. Kredit:Farrin Abbott Fremskridt inden for blød robotik kunne en dag tillade robotter at arbejde sammen med menneske -
 Apple tager imod Netflix med en streamingtjeneste på $5 om månedenApples administrerende direktør Tim Cook annoncerer nye produkter ved en begivenhed tirsdag, 10. september, 2019, i Cupertino, Californien (AP Photo/Tony Avelar) Apple tager endelig imod Netflix m
Apple tager imod Netflix med en streamingtjeneste på $5 om månedenApples administrerende direktør Tim Cook annoncerer nye produkter ved en begivenhed tirsdag, 10. september, 2019, i Cupertino, Californien (AP Photo/Tony Avelar) Apple tager endelig imod Netflix m