


En CNN-baseret metode til matematisk formelscript og typeidentifikation
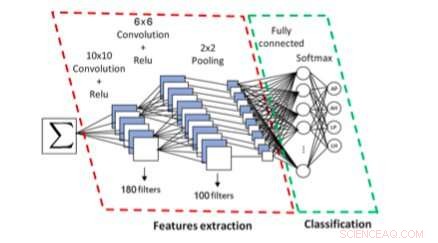
Det CNN-baserede system til symbolskrift og typeidentifikation. Kredit:Khazri &Echi.
Forskere ved University of Tunis har for nylig foreslået et nyt system til matematisk formelscript og typeidentifikation, som er baseret på konvolutionelle neurale netværk (CNN'er). Deres metode, præsenteret i et papir udgivet af Springer, kan automatisk skelne mellem trykte/håndskrevne og arabiske/latinske formler.
I de seneste år, forskere har forsøgt at udvikle systemer, der kan identificere de former, et dokument præsenteres i, det anvendte sprog, og om teksten er maskintrykt eller håndskrevet, for at vælge det passende genkendelsessystem for hvert dokument. De fleste af disse tilgange fokuserer på at identificere forskellige tekstformer, mens meget få er designet til at analysere matematiske formler.
"I denne sammenhæng, vi præsenterer en ny tilgang til problemet med identifikation af scriptet, arabisk eller latin; og typen, håndskrevet eller maskintrykt, af matematiske formler, " skrev forskerne ved University of Tunis i deres papir. "Dette arbejde kommer som en del af vores forskning om offline-genkendelse af arabiske matematiske formler."
I deres undersøgelse, forskerne præsenterede et syntaksstyret system designet til at genkende symboler og analysere deres arrangement. For at genkende symboler, deres tilgang bruger statistiske funktioner og en Bayes netværksklassifikator.
For at analysere strukturen af en formel, deres system anvender en top-down og bottom-up parsing ordning baseret på operatør dominans. Med andre ord, deres system udfører en leksikalsk, geometrisk og syntaktisk analyse af en formel, som hjælper den med at identificere sit skrift (latin vs. arabisk), og om det var håndskrevet eller maskinskrevet.
"Formelparsing består i at anvende, fra den dominerende operatør og dens kontekst, den passende regel til at opdele formlerne i underformler, som vil blive rekursivt analyseret på samme måde, " forklarede forskerne i deres papir.
Ved hjælp af et CNN, den tilgang, som forskerne har udtænkt, udtrækker først og klassificerer forbundne komponenter i en formel. Forskerne trænede og evaluerede deres system ved hjælp af latinske skriftformler fra InftyMDB-1 og CROHME databaserne, samt arabiske formler scannet fra matematikbøger eller håndskrevne af fem forskellige forfattere.
"Det foreslåede genkendelsessystem blev testet på komplekse matematiske formler indeholdende implicit multiplikation, nedskrevet og hævet, med tilfredsstillende resultater, " skrev forskerne. "Tilføjelse af flere funktioner, test af andre funktionsvalgalgoritmer og valg af hurtigere klassifikatorer bør forbedre ydeevnen af det foreslåede system."
Samlet set, evalueringerne foretaget af forskerne gav meget lovende resultater, med deres system, der opnår en identifikationsrate på 94,6 procent. Den parser, de brugte til at analysere formelstrukturen, ser også ud til at være meget robust, da den opnåede en imponerende anerkendelsesrate på 97,63 procent. I deres fremtidige arbejde, forskerne planlægger at forbedre ydeevnen af deres system ved at videreudvikle CNN's filtre og arkitektur.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Et multimateriale, voxel-udskrivningsmetode gør billeddatasæt til fysiske objekter291, 362 farvede linjesegmenter i denne 3D-printede model af en menneskelig hjerne repræsenterer bundter af axoner, der forbinder forskellige områder af hjernen, farvekodede baseret på deres orienteri
Et multimateriale, voxel-udskrivningsmetode gør billeddatasæt til fysiske objekter291, 362 farvede linjesegmenter i denne 3D-printede model af en menneskelig hjerne repræsenterer bundter af axoner, der forbinder forskellige områder af hjernen, farvekodede baseret på deres orienteri -
 Afstemning:Unge amerikanere siger, at onlinemobning er et alvorligt problemI denne 28. feb. 2018 foto, Matty Nev Luby holder sin telefon op foran et ringelys, hun bruger til at læbesynkronisere med smartphone-appen Musical.ly, i Wethersfield, Conn. Teenagere og unge voksne s
Afstemning:Unge amerikanere siger, at onlinemobning er et alvorligt problemI denne 28. feb. 2018 foto, Matty Nev Luby holder sin telefon op foran et ringelys, hun bruger til at læbesynkronisere med smartphone-appen Musical.ly, i Wethersfield, Conn. Teenagere og unge voksne s -
 Fransk flyboard vovehals til at give et nyt kanalbudFranky Zapata faldt i vandet i et mislykket forsøg på at tanke brændstof under sit første forsøg på at krydse Den Engelske Kanal En franskmand, der har fanget landets fantasi med sit jetdrevne fly
Fransk flyboard vovehals til at give et nyt kanalbudFranky Zapata faldt i vandet i et mislykket forsøg på at tanke brændstof under sit første forsøg på at krydse Den Engelske Kanal En franskmand, der har fanget landets fantasi med sit jetdrevne fly -
 Flyver den sikrere himmelI Atlanta, hvor verdens travleste lufthavn udfører tusindvis af flyvninger hver dag, Professor i anvendt lingvistik, Eric Friginal, arbejder på at forbedre kommunikation og sikkerhed i globale rejser.
Flyver den sikrere himmelI Atlanta, hvor verdens travleste lufthavn udfører tusindvis af flyvninger hver dag, Professor i anvendt lingvistik, Eric Friginal, arbejder på at forbedre kommunikation og sikkerhed i globale rejser.
- On-chip observation af THz grafen plasmoner
- Sporing af tropernes bevægelse 800 år tilbage i fortiden
- Hvordan man identificerer forurening
- Neutroner hjælper med at måle cellemembranens viskositet - og afsløre dens grundlag
- Gaia:Mest nøjagtige data nogensinde for næsten to milliarder stjerner
- Australien er ikke på vej til at nå Paris-målet for 2030 (men potentialet er der)