


En hierarkisk RNN-baseret model til at forudsige scenediagrammer for billeder
Samlet procedure for scenediagramforudsigelse foreslået i det seneste papir. Kredit:Gao et al.
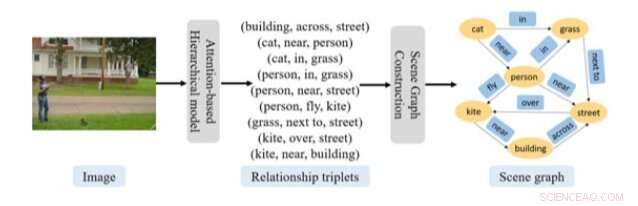
Forskere ved Shanghai University har for nylig udviklet en ny tilgang baseret på tilbagevendende neurale netværk (RNN'er) til at forudsige scenediagrammer fra billeder. Deres tilgang omfatter en model bestående af to opmærksomhedsbaserede RNN'er, samt en komponent til lokalisering af en enhed.
I løbet af det sidste årti eller deromkring, forskere inden for kunstig intelligens (AI) har udviklet en række automatiske værktøjer til at styre, analysere og hente digitale billeder. For at repræsentere indholdet af billeder, traditionelle metoder bruger typisk søgeord eller multi-view-funktioner. Imidlertid, afhængig af enten funktioner eller søgeord fører ofte til en begrænset forståelse af billeder, undlader at levere omfattende viden om dem.
For at afhjælpe disse mangler, et par år siden, et team af forskere ved Stanford University, Max Planck Institute for Informatics, Yahoo Labs og Snapchat foreslog brug af en 'scenediagram, 'en type datastruktur til beskrivelse af visuelle begreber i et billede. Motivgrafer kan gemme beskrivelsen af en scene, der er afbildet i billeder, som en struktureret graf, hvor noder repræsenterer objektinformation, og kanter giver forudsigelser mellem to noder.
Disse strukturerede repræsentationer kan hjælpe brugerne med at administrere digitale billeder. Imidlertid, at forudsige en scenediagram er ofte udfordrende, da det kræver effektive værktøjer til at genkende objekter, såvel som deres egenskaber og interaktioner mellem dem.
Selvom der er flere eksisterende tilgange til at forudsige scenediagrammer, de fleste af disse har betydelige begrænsninger. I deres undersøgelse, forskerne ved Shangai University satte sig for at udvikle en neural netværksbaseret model til at forudsige scenediagrammer fra et visuelt opmærksomhedsorienteret perspektiv.
"En scenediagram giver en stærk mellemliggende videnstruktur til forskellige visuelle opgaver, herunder hentning af semantisk billede, billedtekst, og besvarelse af visuelle spørgsmål, "forskerne skrev i deres papir, som blev offentliggjort på Wiley Online Library. "I denne avis, opgaven med at forudsige en scenediagram for et billede er formuleret som to forbundne problemer, dvs. at genkende relationstrillerne, struktureret som, og konstruere scenediagrammet ud fra de genkendte relationstrillinger. "
Den tilgang, som dette team af forskere har udtænkt, har to nøglekomponenter, den ene havde til formål at genkende det, de kalder 'relationstrillinger' og den anden til at konstruere en scenediagram. For at genkende relationstrillinger, forskerne brugte en model bestående af to opmærksomhedsbaserede RNN'er i en hierarkisk organisation.
"Det første netværk genererer en emnevektor for hver relationstriplet, der henviser til, at det andet netværk forudsiger hvert ord i denne relationstriplet givet emnevektoren, "forklarede forskerne i deres papir." Denne fremgangsmåde fanger med succes den kompositoriske struktur og kontekstuelle afhængighed af et billede og forholdet trillinger, der beskriver dets scene. "
Når denne RNN-baserede model har hentet relevante oplysninger fra et billede, den anden komponent i deres tilgang bruger disse data til at konstruere scenediagrammer. Til dette trin, forskerne brugte en entitetslokaliseringsmetode, som kan bestemme grafens struktur ved hjælp af den tilgængelige opmærksomhedsinformation. Ud over disse to komponenter, forskerne brugte en algoritme til at tydeliggøre den proces, hvorigennem deres tilgang konverterer den genererede relationstripletinformation til en scenediagram.
Deres tilgang blev evalueret ved hjælp af det populære visuelle genom (VG) datasæt og det visuelle relationsdatasæt (VRD). Med henblik på deres undersøgelse, forskerne kommenterede billederne i disse datasæt med et sæt trillinger, mærkning af hvert emne og objektpar med placeringsoplysninger.
"Resultaterne af eksperimenter på to populære datasæt viser, at den hierarkiske tilbagevendende tilgang fra det visuelt-opmærksomhedsorienterede perspektiv inde i vores model har en tydelig forbedring af resultaterne i forhold til baseline-modeller, "skrev forskerne." I fremtidigt arbejde, Vi planlægger at berige scenegrafen med semantik på højt niveau og mere diversificerede attributter. "
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Facebook har introduceret en brugerpålidelighedsscore - her er grunden til, at det skal gå længer…Facebook ønsker at forbedre tilliden. Kredit:Shutterstock Facebook er angiveligt begyndt at give brugerne en hemmelig troværdighedsscore i sit forsøg på at tackle falske nyheder. Ifølge Washington
Facebook har introduceret en brugerpålidelighedsscore - her er grunden til, at det skal gå længer…Facebook ønsker at forbedre tilliden. Kredit:Shutterstock Facebook er angiveligt begyndt at give brugerne en hemmelig troværdighedsscore i sit forsøg på at tackle falske nyheder. Ifølge Washington -
 Alle fingerrobotter vil have til jul er en hånd som DactylKredit:openai Et brev, flerfarvet blok:En triviel opgave venter på mennesker for at hente den, vend det om, kaste det rundt i vores håndflade. For en robotekspert, selvom, dette er en opgave, der
Alle fingerrobotter vil have til jul er en hånd som DactylKredit:openai Et brev, flerfarvet blok:En triviel opgave venter på mennesker for at hente den, vend det om, kaste det rundt i vores håndflade. For en robotekspert, selvom, dette er en opgave, der -
 Et fælles energiknudepunktEt af de første huse, der blev forankret. Kredit:Fraunhofer ITWM Mængden af energi produceret af vedvarende energikilder ebber og flyder. Fraunhofer Institute for Industrial Mathematics ITWM har
Et fælles energiknudepunktEt af de første huse, der blev forankret. Kredit:Fraunhofer ITWM Mængden af energi produceret af vedvarende energikilder ebber og flyder. Fraunhofer Institute for Industrial Mathematics ITWM har -
 Hvorfor politiet skal bruge maskinlæring - meget omhyggeligtKredit:Kirill_makarov/Shutterstock.com Debatten om, at politiet bruger maskinlæring, intensiveres - den betragtes i nogle kredse som lige så kontroversiel som stop og søg. Stop og søg er et af de
Hvorfor politiet skal bruge maskinlæring - meget omhyggeligtKredit:Kirill_makarov/Shutterstock.com Debatten om, at politiet bruger maskinlæring, intensiveres - den betragtes i nogle kredse som lige så kontroversiel som stop og søg. Stop og søg er et af de
- Bøjede nanoporer sænker DNA-passage for lettere sekventering
- Hvilke typer af molekyler katalyserer RNA-splejsning?
- Direkte visualisering af elektromagnetisk bølgedynamik ved hjælp af laserfri ultrahurtig elektronm…
- Hvad betyder COVID-19 for fremtidens arbejde?
- Opskalering af søgning efter analogier kan være nøglen til innovation
- En teknik til at sile universernes første gravitationsbølger