


SentiArt:et følelsesanalyseværktøj til profilering af karakterer fra verdenslitteraturtekster
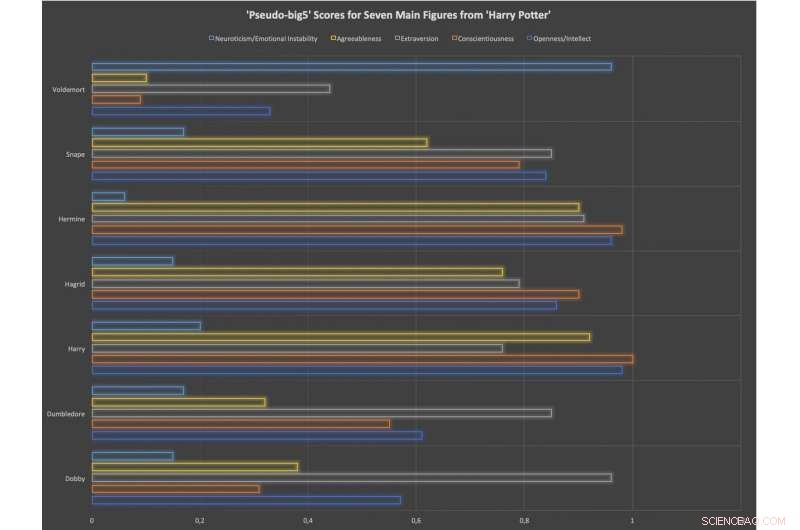
Pseudo-store 5 scorer for syv hovedfigurer i Harry Potter-bøgerne. Disse scoringer er percentiler baseret på en stikprøve på 100 figurer i bogserien. Kredit:Arthur M. Jacobs.
Arthur Jacobs, professor og forsker ved Freie Universität Berlin, har for nylig udviklet SentiArt, en ny machine learning -teknik til at udføre følelsesanalyser af litterære tekster, samt både fiktive og ikke-fiktive figurer. I sit papir, sat til at blive offentliggjort af Grænser inden for robotik og AI , han anvendte dette værktøj til passager og karakterer fra Harry Potter -bøgerne.
Jacobs har en baggrund inden for neurolingvistik, en gren af lingvistik, der udforsker de neurale mekanismer, der er forbundet med sprogtilegnelse, forståelse og udtryk. I sit tidligere arbejde, han har ofte undersøgt, hvordan maskinlæringsværktøjer kan bruges til at analysere og bedre forstå menneskeligt sprog. Han er især interesseret i det, han kalder computational poetics, et studieområde, der fokuserer på brugen af beregningsværktøjer til at forstå litterært indhold.
"I 2011, Jeg skrev en bog med den østrigske digter Raoul Schrott kaldet 'Hjerne og poesi , 'hvor vi spekulerede i, at det ville hjælpe med at udvikle følelsesanalyseværktøjer til litterære tekster og poesi, ikke kun til filmanmeldelser eller Trump tweets, som ser ud til at være guldstandarden i klassisk følelsesanalyse, "Jacobs fortalte TechXplore." Vi ville også udvikle et værktøj, der kan forudsige menneskelige neuronale og adfærdsmæssige data, ikke kun selvrapporter indsamlet via Amazon Turk. "
I sit nye studie, Jacobs forsøgte at omsætte nogle af de ideer, der blev introduceret i hans tidligere arbejde, i praksis ved at udvikle et værktøj til at analysere følelser i litterære tekster. Den teknik, han foreslog, kaldet SentiArt, bruger vektorrumsmodeller og teori-guidet, empirisk validerede lister over etiketter til beregning af værdien af individuelle ord i en tekst. Vektorrumsmodeller er repræsentationer af tekstdokumenter som vektorer af identifikatorer, som ofte bruges til at filtrere, hente eller organisere oplysninger.
"SentiArt er et meget forenklet værktøj, der kan bruges af ikke-eksperter til blot at sammenligne ordene i deres testtekst (dvs. teksten, de vil lave en følelsesanalyse på) med et excelark, som de kan downloade gratis fra min hjemmeside, "Jacobs forklaret." I princippet værktøjet skal fungere på ethvert sprog, som du kan downloade Facebooks såkaldte vektorrumsmodeller til, på fastText -websiden. Mens mit studie fokuserer på engelsk og tysk, du kan også bruge det på malaysisk, Farsi eller en kinesisk dialekt, og en lang række andre sprog, som fastText har vektorrumsmodeller til over 290 sprog. "
Jacobs fremhæver, at SentiArt er ret let at bruge, tilføjede, at han var i stand til at lære 30 tyske litteraturstuderende at bruge det i løbet af en times time. I sit seneste arbejde, han testede værktøjets nøjagtighed ved hjælp af data indsamlet under en neurokognitiv undersøgelse og brugte det derefter til at beregne følelsesmæssige og personlighedsfigurprofiler for nogle af de vigtigste Harry Potter -karakterer, herunder Voldemort, Snape, Hermione, Hagrid, Harry, Dumboldore og Dobby.
Interessant nok, han beregnede disse karakterers følelsesmæssige figurer og personlighedsprofiler baseret på 'big five' personlighedsteorien, en etableret konstruktion inden for psykologiforskning. 'Big Five' -teorien bruges generelt til groft at måle menneskers personlighedstræk baseret på fem nøgledimensioner, nemlig åbenhed, samvittighedsfuldhed, ekstraversion, behagelighed og følelsesmæssig stabilitet.
Jacobs gennemførte en række analyser, der sammenlignede det værktøj, han udviklede, med andre maskinlæringsklassifikatorer til følelsesanalyse, såsom Vader og Hu-Liu. SentiArt klarede sig bemærkelsesværdigt godt med at forudsige følelsespotentialet i tekstpassager fra Harry Potter -bøgerne, samtidig med at han laver sandsynlige forudsigelser om fiktive personers følelsesmæssige og personlighedsprofil. Endelig, værktøjet opnåede en lovende krydsvalideringsnøjagtighed ved at klassificere 100 fiktive figurer i 'gode' eller 'dårlige'.
"Papiret er på få begrænsede applikationer og på to sprog (tysk/engelsk), så før jeg kan spekulere i applikationspotentialet, at være en eksperimentel videnskabsmand, Jeg ville ønske at have mange flere krydsvalideringsundersøgelser ved hjælp af menneskelige data, "Forklarede Jacobs." Sådan er jeg uddannet, selvom det normalt ikke er i naturligt sprog (NLP) eller maskinlæringsfællesskabet, det er hovedprioriteterne. Men som neurolingforskere, vi ville altid prøve at teste forudsigelserne om en algoritme med menneskelige data, før vi spekulerer i, hvad det virkelig er nyttigt til. "
Selvom Jacobs understreger behovet for yderligere undersøgelser for at fastslå SentiArts effektivitet og generaliserbarhed, værktøjet, han udviklede, kunne i sidste ende have mange interessante applikationer. For eksempel, det kunne anvendes inden for områder som computinglingvistik, personlighedspsykologi, digitale humaniora og måske endda i kliniske rammer. Det kan, i princippet, også anvendes på ikke-fiktive tegn, der vises på Wikipedia eller Wikinews, f.eks. Winston Churchill, Marilyn Monroe eller Angela Merkel.
"Modellen passede med et første sæt empiriske data, Harry Potter -karaktererne, er bestemt opmuntrende, "Tilføjede Jacobs." Også to af de mest populære følelsesanalyseværktøjer, jeg sammenlignede det med, klarer sig ikke bedre i denne sammenhæng, så jeg synes, at dette er en præstation, der fortjener offentliggørelse. Jeg synes, at det at vise den følelsesmæssige karakterprofil for Voldemort eller Harry Potter var en god gimmick, men selvfølgelig, værktøjet kan også anvendes på ikke-fiktive tegn. "
Jacobs planlægger nu at udføre yderligere krydsvalideringsundersøgelser, der tester hans models forudsigelser med menneskelige data. Han håber, at teams på andre universiteter vil gøre det samme, enten ved hjælp af data indsamlet via Amazon Turk eller neuroimaging data, som i "Harry Potter 'undersøgelsen udført i hans laboratorium. Derudover har han vil gerne undersøge måder at forbedre ydelsen af følelsesanalyseværktøjer i opgaver ved hjælp af maskinlæringsregressorer i stedet for klassifikatorer.
"Machine learning approaches are generally divided into two different types, " Jacobs explained. "The first are classification approaches, which classify data into categories, such as positive or negative. This is where my algorithm does very well. The hard test is not classification, it's regression, which entails fitting an algorithm's predictions to continuous human data, such as ratings on a scale from one to 10. Few people in sentiment analysis use regressors, especially for literary texts, because accuracy tends to drop, for eksempel, from over 90 percent to about 30 percent to 50 percent. I would like to see more work testing this, and once more empirical data has been published, I will try to improve parts of the algorithm in agreement with this new data."
In addition to his research endeavors, Jacobs will soon start teaching natural language programming (NLP) and machine learning as part of a new data science course at Freie Universität Berlin. His hope is to train new generations of data scientists to value the collection of empirical human data related to reading literature and poetry just as much as publishing code or predicting particular things.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Europæiske lande ødelægger massiv ulovlig fildelingsringKredit:CC0 Public Domain Tyske anklagere siger, at myndigheder i tre europæiske lande har demonteret en massiv ulovlig fildelingsside for film, musik og pornografi. Anklagere i den vestlige delst
Europæiske lande ødelægger massiv ulovlig fildelingsringKredit:CC0 Public Domain Tyske anklagere siger, at myndigheder i tre europæiske lande har demonteret en massiv ulovlig fildelingsside for film, musik og pornografi. Anklagere i den vestlige delst -
 Fra bip til boom:Europa hører opkald fra kinesiske telefonerEkspansionen til Europa af firmaer som Xiaomi kommer, efterhånden som brugerne bliver mere og mere uvillige til at betale $1, 000 for en ny enhed Kinas smartphoneproducenter har længe været begræn
Fra bip til boom:Europa hører opkald fra kinesiske telefonerEkspansionen til Europa af firmaer som Xiaomi kommer, efterhånden som brugerne bliver mere og mere uvillige til at betale $1, 000 for en ny enhed Kinas smartphoneproducenter har længe været begræn -
 Elektrisk skift får bæltestramninger til tyske bilproducenterBMWs administrerende direktør Harald Krueger med den tyske bilproducents Vision iNEXT konceptbil, et helt elektrisk og stærkt automatiseret køretøj Tyske bilproducenter henvender sig i stigende gr
Elektrisk skift får bæltestramninger til tyske bilproducenterBMWs administrerende direktør Harald Krueger med den tyske bilproducents Vision iNEXT konceptbil, et helt elektrisk og stærkt automatiseret køretøj Tyske bilproducenter henvender sig i stigende gr -
 George Laurer, opfinder af allestedsnærværende UPC, dør som 94-årigI denne 24. sept. 2015, fil foto, tags med stregkoder hænger på et anlæg i Flandreau, S.D. George J. Laurer, hvis opfindelse af Universal Product Code hos IBM transformerede detailhandel og andre indu
George Laurer, opfinder af allestedsnærværende UPC, dør som 94-årigI denne 24. sept. 2015, fil foto, tags med stregkoder hænger på et anlæg i Flandreau, S.D. George J. Laurer, hvis opfindelse af Universal Product Code hos IBM transformerede detailhandel og andre indu
- Sådan beregnes kølehastighed
- Lys kan magnetisere ikke-magnetiske metaller, foreslå fysikere
- Forskere forklarer synligt lys fra 2-D blyhalogenidperovskitter
- Alexa, tjek mine sikkerhedsindstillinger
- Facebook -chef er vært for konservative gæster midt i partiskabelse
- Folk samles ved Stonehenge til Solstice trods råd