


Algoritmer findes overalt, men hvad skal der til for at vi stoler på dem?
En algoritme følger bare regler designet enten direkte eller indirekte af et menneske. Kredit:Shutterstock/Billion Photos
Algoritmernes rolle i vores liv vokser hurtigt, fra blot at foreslå online søgeresultater eller indhold i vores feed på sociale medier, til mere kritiske spørgsmål som at hjælpe læger med at bestemme vores kræftrisiko.
Men hvordan ved vi, at vi kan stole på en algoritmes beslutning? I juni, næsten 100 chauffører i USA lærte på den hårde måde, at nogle gange algoritmer kan få det meget forkert.
Google Maps fik dem alle fast på en mudret privat vej i en mislykket omvej for at undslippe en trafikprop på vej til Denver International Airport, i Colorado.
Efterhånden som vores samfund i stigende grad afhænger af algoritmer til rådgivning og beslutningstagning, det bliver presserende at tackle det tornede spørgsmål om, hvordan vi kan stole på dem.
Algoritmer beskyldes regelmæssigt for partiskhed og diskrimination. De har tiltrukket bekymring fra amerikanske politikere, blandt påstande har vi hvide mænd, der udvikler ansigtsgenkendelsesalgoritmer uddannet til kun at fungere godt for hvide mænd.
Men algoritmer er ikke andet end computerprogrammer, der tager beslutninger baseret på regler:enten regler, som vi gav dem, eller regler fandt de ud af selv baseret på eksempler, vi gav dem.
I begge tilfælde, mennesker har kontrol over disse algoritmer, og hvordan de opfører sig. Hvis en algoritme er defekt, det gør vi.
Så før vi alle ender i en metaforisk (eller bogstaveligt talt!) Mudret trafikprop, der er et presserende behov for at genoverveje, hvordan vi mennesker vælger at stresstest disse regler og få tillid til algoritmer.
Algoritmer afprøvet, slags
Mennesker er naturligt mistænkelige skabninger, men de fleste af os kan overbevises af beviser.
I betragtning af nok testeksempler - med kendte korrekte svar - udvikler vi tillid, hvis en algoritme konsekvent giver det korrekte svar, og ikke kun for lette indlysende eksempler, men for de udfordrende, realistiske og mangfoldige eksempler. Så kan vi være overbevist om, at algoritmen er upartisk og pålidelig.
Det lyder let nok, ret? Men er det sådan algoritmer normalt testes? Det er sværere end det lyder at sikre, at testeksempler er upartiske og repræsentative for alle mulige scenarier, der kan støde på.
Mere almindeligt, velstuderede benchmarkeksempler bruges, fordi de er let tilgængelige fra websteder. (Microsoft havde en database med berømthedsansigter til test af ansigtsgenkendelsesalgoritmer, men den blev for nylig slettet på grund af bekymringer om privatlivets fred.)
Sammenligning af algoritmer er også lettere, når den testes på delte benchmarks, men disse testeksempler bliver sjældent undersøgt for deres skævheder. Værre endnu, algoritmers ydeevne rapporteres typisk i gennemsnit på tværs af testeksemplerne.
Desværre, at vide, at en algoritme i gennemsnit fungerer godt, fortæller os ikke noget om, hvorvidt vi kan stole på den i bestemte tilfælde.
Det er ikke overraskende at læse, at læger er skeptiske over for Googles algoritme til kræftdiagnose, som giver 89% nøjagtighed i gennemsnit. Hvordan ved en læge, om deres patient er en af de uheldige 11% med en forkert diagnose?
Med stigende efterspørgsel efter personlig medicin, der er skræddersyet til den enkelte (ikke kun Mr./Ms Average), og med gennemsnit kendt for at skjule alle slags synder, de gennemsnitlige resultater vil ikke vinde menneskelig tillid.
Behovet for nye testprotokoller
Det er tydeligvis ikke strengt nok til at teste en masse eksempler-velundersøgte benchmarks eller ej-uden at bevise, at de er upartiske, og derefter drage konklusioner om pålideligheden af en algoritme i gennemsnit.
Og alligevel er det paradoksalt nok den tilgang, som forskningslaboratorier rundt om i verden er afhængige af for at bøje deres algoritmiske muskler. Den akademiske peer-review-proces forstærker disse arvelige og sjældent spørgsmålstegn ved testprocedurer.
En ny algoritme kan udgives, hvis den i gennemsnit er bedre end eksisterende algoritmer på godt studerede benchmarkeksempler. Hvis det ikke er konkurrencedygtigt på denne måde, det er enten skjult væk fra yderligere peer-review-undersøgelse, eller nye eksempler præsenteres, for hvilke algoritmen ser nyttig ud.
På denne måde, en varm, flatterende lys skinner på hver nyligt offentliggjort algoritme, med lidt forsøg på at stress-teste dens styrker og svagheder, og præsenter det for vorter og det hele. Det er computervidenskabelig version af medicinske forskere, der ikke offentliggør de fulde resultater af kliniske forsøg.
Efterhånden som algoritmisk tillid bliver mere afgørende, vi er presserende nødt til at opdatere denne metode for at undersøge, om de valgte testeksempler er egnede til formålet. Indtil nu, forskere er blevet holdt tilbage fra mere stringente analyser på grund af manglen på egnede værktøjer.
Vi har bygget en bedre stresstest
Efter mere end et årti med forskning, mit team har lanceret et nyt online algoritme analyseværktøj kaldet MATILDA:Melbourne Algorithm Test Instance Library med Data Analytics.
Det hjælper stresstestalgoritmer mere stringent ved at oprette kraftfulde visualiseringer af et problem, viser alle scenarier eller eksempler en algoritme bør overveje til omfattende test.
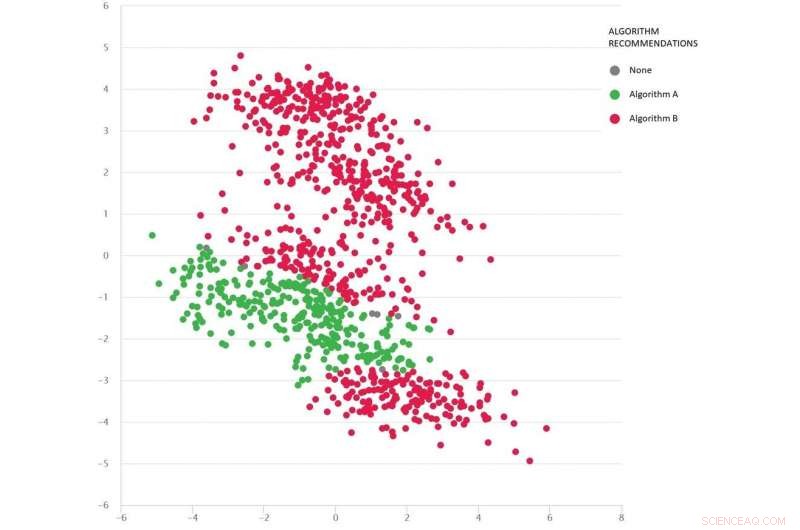
Et problem af typen Google-maps med forskellige testscenarier som prikker:Algoritme B (rød) er bedst i gennemsnit, men algoritme A (grøn) er bedre i mange tilfælde. Kredit:MATILDA, Forfatter oplyst
MATILDA identificerer hver algoritms unikke styrker og svagheder, anbefale hvilken af de tilgængelige algoritmer, der skal bruges under forskellige scenarier, og hvorfor.
For eksempel, hvis den seneste regn har gjort uforseglede veje til mudder, nogle "korteste vej" -algoritmer kan være upålidelige, medmindre de kan forudse vejrets sandsynlige indvirkning på rejsetider, når de giver råd til den hurtigste rute. Medmindre udviklere tester sådanne scenarier, ved de aldrig om sådanne svagheder, før det er for sent, og vi sidder fast i mudderet.
MATILDA hjælper os med at se benchmarks mangfoldighed og alsidighed, og hvor nye testeksempler skal designes til at fylde alle kroge i det mulige rum, hvor algoritmen kan blive bedt om at fungere.
Billedet herunder viser et mangfoldigt sæt scenarier (prikker) for en problemstillingstype i Google Maps. Hvert scenario varierer betingelser - f.eks. Oprindelses- og destinationslokationer, det tilgængelige vejnet, vejrforhold, rejsetider på forskellige veje-og al denne information fanges matematisk og opsummeres af hvert scenarios todimensionelle koordinater i rummet.
To algoritmer sammenlignes (rød og grøn) for at se, hvilken der kan finde den korteste rute. Hver algoritme har vist sig at være bedst (eller vist upålidelig) i forskellige regioner afhængigt af, hvordan den fungerer i disse testede scenarier.
Vi kan også gætte godt på, hvilken algoritme der sandsynligvis er bedst til de manglende scenarier (huller), vi endnu ikke har testet.
Matematikken bag MATILDA hjælper med at skabe denne visualisering, ved at analysere algoritmens pålidelighedsdata fra testscenarier, og let finde en måde at se mønstrene på.
Indsigten og forklaringerne betyder, at vi kan vælge den bedste algoritme til problemet, frem for at krydse fingre og håbe på, at vi kan stole på den algoritme, der i gennemsnit fungerer bedst.
Ved strengt stresstestende algoritmer på denne måde-vorter og det hele-bør vi reducere risikoen for useriøse algoritmebeslutninger, sikring af tillid hos Mr./Ms Average, og måske endda de mest skeptiske mennesker.
Denne artikel er genudgivet fra The Conversation under en Creative Commons -licens. Læs den originale artikel. 
 Varme artikler
Varme artikler
-
 Ny lufttrykssensor kan forbedre hverdagens enhederShahrzad Sherry Towfighian er lektor i maskinteknik ved Binghamton University, State University of New York. Kredit:Binghamton University, State University of New York Et hold af mekaniske ingeniø
Ny lufttrykssensor kan forbedre hverdagens enhederShahrzad Sherry Towfighian er lektor i maskinteknik ved Binghamton University, State University of New York. Kredit:Binghamton University, State University of New York Et hold af mekaniske ingeniø -
 Vermont starter små pakker en stor ting for energiindustrienEnergisk vækst. UVM spinoff -virksomheden Packetized Energy er i gang, tilføjelse af personale, kunder og forretningspartnere ved et imponerende klip. Omgivet af fuldtids- og deltidsansatte i virksomh
Vermont starter små pakker en stor ting for energiindustrienEnergisk vækst. UVM spinoff -virksomheden Packetized Energy er i gang, tilføjelse af personale, kunder og forretningspartnere ved et imponerende klip. Omgivet af fuldtids- og deltidsansatte i virksomh -
 Spotify stiger i 26 milliarder dollars aktiedebutHandlende arbejder på gulvet under Spotify-børsnoteringen på New York Stock Exchange den dag, musikstreamingtjenesten begyndte at handle sine aktier som SPOT Spotify steg tirsdag til en værdi af me
Spotify stiger i 26 milliarder dollars aktiedebutHandlende arbejder på gulvet under Spotify-børsnoteringen på New York Stock Exchange den dag, musikstreamingtjenesten begyndte at handle sine aktier som SPOT Spotify steg tirsdag til en værdi af me -
 Ny sender bruger ultrahurtigt frekvenshop og datakryptering for at beskytte signaler mod at blive op…Kredit:CC0 Public Domain I dag, mere end 8 milliarder enheder er forbundet rundt om i verden, dannelse af et tingenes internet, der omfatter medicinsk udstyr, wearables, køretøjer, og smarte husho
Ny sender bruger ultrahurtigt frekvenshop og datakryptering for at beskytte signaler mod at blive op…Kredit:CC0 Public Domain I dag, mere end 8 milliarder enheder er forbundet rundt om i verden, dannelse af et tingenes internet, der omfatter medicinsk udstyr, wearables, køretøjer, og smarte husho
- Forskere forbedrer bornitrid nanorør til næste generations kompositter
- Solar nanotråd array kan øge procentdelen af solfrekvenser, der er tilgængelige til energiomdan…
- Undersøgelse finder 6, 600 spild fra fracking i kun fire stater
- Hvordan man laver en model af en Mosquito Insect Science Project
- Retsmedicinsk kemiker opdager brug af marihuana baseret på svedtest
- Døden i rummet:Her er hvad der ville ske med vores kroppe