


Undersøgelse af selvopmærksomhedsmekanismen bag BERT-baserede arkitekturer
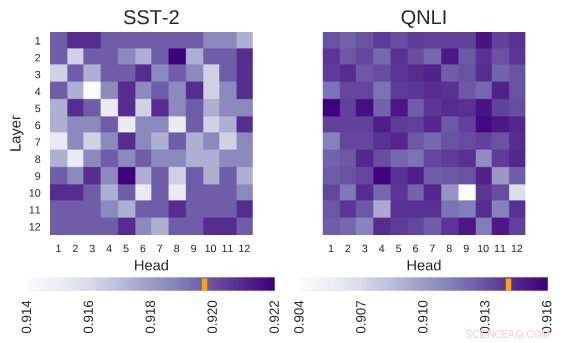
Undersøgt BERT-arkitektur har arkitekturen på 12 lag gange 12 hoveder. Hver celle i denne figur viser ydeevnen af BERT, hvis det tilsvarende hoved er slukket. Mørkere farver indikerer højere ydeevne, og hvide celler angiver hoveder, uden hvilke BERTs ydeevne falder. Stanford Sentiment Treebank (SST-2):Der er flere hoveder, der koder for information, som er nødvendig for opgaven. Question Natural Language Inference (QNLI):De fleste hoveder forbedrer den overordnede ydeevne, når de er slukket. Kredit:Kovaleva et al.
BERT, en transformer-baseret model karakteriseret ved en unik selvopmærksomhedsmekanisme, har indtil videre vist sig at være et gyldigt alternativ til tilbagevendende neurale netværk (RNN'er) til at tackle NLP-opgaver (natural language processing). På trods af deres fordele, indtil nu, meget få forskere har studeret disse BERT-baserede arkitekturer i dybden, eller forsøgt at forstå årsagerne bag effektiviteten af deres selvopmærksomhedsmekanisme.
Er opmærksom på dette hul i litteraturen, forskere ved University of Massachusetts Lowells Text Machine Lab for Natural Language Processing har for nylig udført en undersøgelse, der undersøger fortolkningen af selvopmærksomhed, den mest vitale komponent i BERT-modeller. Den ledende efterforsker og seniorforfatter for denne undersøgelse var Olga Kovaleva og Anna Rumshisky, henholdsvis. Deres papir er forududgivet på arXiv og skal præsenteres på EMNLP 2019-konferencen, antyder, at en begrænset mængde opmærksomhedsmønstre gentages på tværs af forskellige BERT-underkomponenter, antyder deres overparametrering.
"BERT er en nyere model, der gjorde et gennembrud i NLP-samfundet, overtage ranglisterne på tværs af flere opgaver. Inspireret af denne seneste trend, vi var nysgerrige efter at undersøge, hvordan og hvorfor det virker, " fortalte teamet af forskere til TechXplore via e-mail. "Vi håbede at finde en sammenhæng mellem selvopmærksomhed, BERT's vigtigste underliggende mekanisme, og sprogligt fortolkelige relationer inden for den givne inputtekst."
BERT-baserede arkitekturer har en lagstruktur, og hvert af dets lag består af såkaldte "hoveder". For at modellen skal fungere, hvert af disse hoveder er trænet til at kode en bestemt type information, dermed bidrage til den samlede model på sin egen måde. I deres undersøgelse, forskerne analyserede informationen kodet af disse individuelle hoveder, med fokus på både kvantitet og kvalitet.
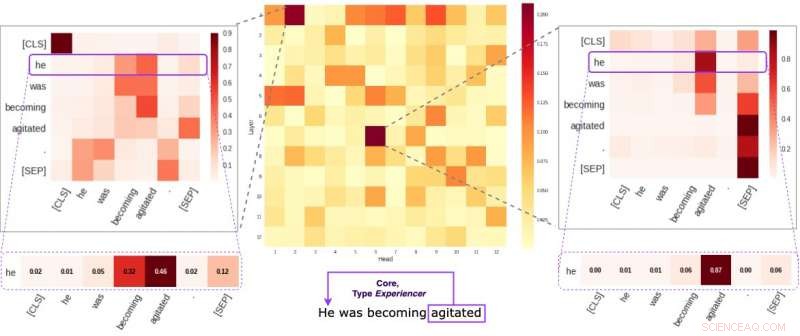
Hver celle i den midterste figur afspejler, hvordan individuelle hoveder er opmærksomme på kerne semantiske links inden for en given sætning (i gennemsnit). Vi identificerede to specifikke hoveder, der har tendens til at kode semantisk information mere end de andre. De to billeder på siderne viser, hvordan disse to hoveder tildeler vægt til individuelle ord i en tilfældig sætning i vores datasæt. Kredit:Kovaleva et al.
"Vores metodologi fokuserede på at undersøge individuelle hoveder og de opmærksomhedsmønstre, de frembragte, " forklarede forskerne. "I bund og grund, vi forsøgte at besvare spørgsmålet:"Når BERT koder et enkelt ord i en sætning, lægger den vægt på de andre ord på en måde, der er meningsfuld for mennesker?"
Forskerne udførte en række eksperimenter med både grundlæggende fortrænede og finjusterede BERT-modeller. Dette gjorde det muligt for dem at indsamle adskillige interessante observationer relateret til selvopmærksomhedsmekanismen, der ligger i kernen af BERT-baserede arkitekturer. For eksempel, de observerede, at et begrænset sæt opmærksomhedsmønstre ofte gentages på tværs af forskellige hoveder, hvilket tyder på, at BERT-modeller er overparametriserede.
"Vi fandt ud af, at BERT har en tendens til at være overparametriseret, og der er en masse redundans i den information, den koder, " sagde forskerne. "Dette betyder, at det beregningsmæssige fodaftryk ved træning af en så stor model ikke er velbegrundet."
Et yderligere interessant fund indsamlet af forskerholdet ved University of Massachusetts Lowell er, at afhængigt af opgaven, som en BERT-model løser, tilfældigt at slukke nogle af dens hoveder kan føre til en forbedring, snarere end et fald, i ydeevne. Ud over, forskerne har ikke identificeret nogen sproglige mønstre, der er af særlig betydning for at bestemme BERT's præstation i downstream-opgaver.
"At gøre dyb læring fortolkelig er vigtigt for både grundlæggende og anvendt forskning, og vi vil fortsætte med at arbejde i denne retning, " sagde forskerne. "Nye BERT-baserede modeller er for nylig blevet frigivet, og vi planlægger at udvide vores metode til også at undersøge dem."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Udbredt fald i vindenergiressourcer fundet på den nordlige halvkugleAsiens største vindmøllepark, vindmølleparken Dabancheng i Xinjiang -provinsen i Kina. Kredit:Gang Huang Da klimaforandringerne er ved at blive et større problem, bestræbelser på afbødning foretag
Udbredt fald i vindenergiressourcer fundet på den nordlige halvkugleAsiens største vindmøllepark, vindmølleparken Dabancheng i Xinjiang -provinsen i Kina. Kredit:Gang Huang Da klimaforandringerne er ved at blive et større problem, bestræbelser på afbødning foretag -
 Hvorfor blockchain udfordrer konventionel tænkning om intellektuel ejendomBlockchain-teknologi har vendt konventionel tænkning om intellektuel ejendomsret og ophavsret på hovedet. Kredit:www.shutterstock.com, CC BY-ND Kryptovalutaer får meget opmærksomhed, men finans er
Hvorfor blockchain udfordrer konventionel tænkning om intellektuel ejendomBlockchain-teknologi har vendt konventionel tænkning om intellektuel ejendomsret og ophavsret på hovedet. Kredit:www.shutterstock.com, CC BY-ND Kryptovalutaer får meget opmærksomhed, men finans er -
 Microsofts aktionærer besejrer 2 aktivistiske forslagI denne 28. nov. 2018, filfoto Microsofts administrerende direktør Satya Nadella taler under det årlige Microsoft Corp. aktionærmøde i Bellevue, Wash. Microsofts aktionærer stemte onsdag, 4. december
Microsofts aktionærer besejrer 2 aktivistiske forslagI denne 28. nov. 2018, filfoto Microsofts administrerende direktør Satya Nadella taler under det årlige Microsoft Corp. aktionærmøde i Bellevue, Wash. Microsofts aktionærer stemte onsdag, 4. december -
 Microsoft afslører ansigtsgenkendelsesprincipper, opfordrer til nye loveMicrosofts præsident, Brad Smith, afslørede principper, som techgiganten vil anvende til implementering af teknologi til ansigtsgenkendelse Microsoft sagde torsdag, at det vedtog et sæt principper
Microsoft afslører ansigtsgenkendelsesprincipper, opfordrer til nye loveMicrosofts præsident, Brad Smith, afslørede principper, som techgiganten vil anvende til implementering af teknologi til ansigtsgenkendelse Microsoft sagde torsdag, at det vedtog et sæt principper
- Fysikere finder stuetemperatur, 2D-til-1D topologisk overgang
- Arkæologiske beviser bekræfter længe tvivlsomme middelalderlige beretninger om det første korsto…
- Startup planlægger at opsende små satellitter fra Virginia-kysten
- Hvad er funktionerne ved en levercelle?
- Strømlining af måling af fononspredning
- Dampdrevet rumfartøjsprototype kan teoretisk udforske himmellegemer for evigt