


Supercomputer analyserer webtrafik på tværs af hele internettet
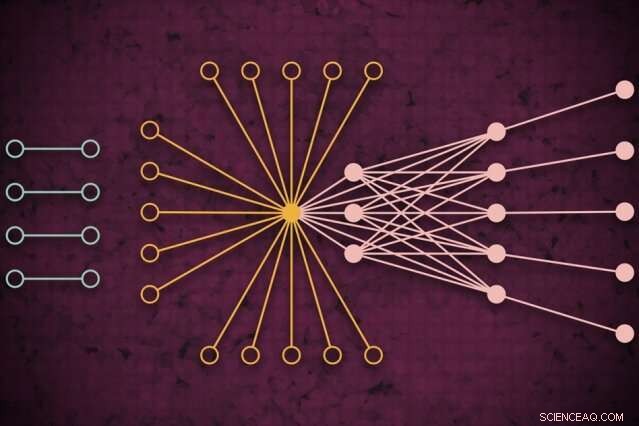
Ved hjælp af et supercomputersystem, MIT -forskere udviklede en model, der fanger, hvordan global webtrafik kunne se ud på en given dag, inklusive tidligere usete isolerede links (venstre), der sjældent forbinder, men som ser ud til at påvirke kernewebtrafik (højre). Kredit:MIT News
Ved hjælp af et supercomputersystem, MIT -forskere har udviklet en model, der fanger, hvordan webtrafik ser ud rundt om i verden på en given dag, som kan bruges som et måleværktøj til internetforskning og mange andre applikationer.
Forståelse af webtrafikmønstre i så stor en skala, siger forskerne, er nyttig til at informere internetpolitik, identificere og forhindre afbrydelser, forsvare sig mod cyberangreb, og design af mere effektiv computerinfrastruktur. Et papir, der beskriver fremgangsmåden, blev præsenteret på den seneste IEEE High Performance Extreme Computing Conference.
For deres arbejde, forskerne samlede det største offentligt tilgængelige internettrafikdatasæt, omfattende 50 milliarder datapakker udvekslet forskellige steder over hele kloden over en periode på flere år.
De kørte dataene gennem en ny "neuralt netværk" pipeline, der kører på tværs af 10, 000 processorer af MIT SuperCloud, et system, der kombinerer databehandlingsressourcer fra MIT Lincoln Laboratory og på tværs af instituttet. Denne pipeline trænede automatisk en model, der fanger forholdet for alle links i datasættet - fra almindelige pings til giganter som Google og Facebook, til sjældne links, der kun kortvarigt forbinder, men alligevel ser ud til at have en vis indflydelse på webtrafikken.
Modellen kan tage ethvert massivt netværksdatasæt og generere nogle statistiske målinger af, hvordan alle forbindelser i netværket påvirker hinanden. Det kan bruges til at afsløre indsigt i peer-to-peer fildeling, ondsindede IP-adresser og spammingadfærd, fordelingen af angreb i kritiske sektorer, og trafikflaskehalse for bedre at allokere computerressourcer og holde data flydende.
I konceptet, værket ligner måling af den kosmiske mikrobølge baggrund af rummet, de næsten ensartede radiobølger, der rejser rundt i vores univers, og som har været en vigtig informationskilde for at studere fænomener i det ydre rum. "Vi byggede en nøjagtig model til at måle baggrunden for internettets virtuelle univers, "siger Jeremy Kepner, en forsker ved MIT Lincoln Laboratory Supercomputing Center og en astronom ved uddannelse. "Hvis du vil opdage afvigelser eller uregelmæssigheder, du skal have en god model af baggrunden. "
Sammen med Kepner på papiret er:Kenjiro Cho fra Internet Initiative Japan; KC Claffy fra Center for Applied Internet Data Analysis ved University of California i San Diego; Vijay Gadepally og Peter Michaleas fra Lincoln Laboratory's Supercomputing Center; og Lauren Milechin, en forsker i MIT's Department of Earth, Atmosfæriske og planetariske videnskaber.
Opdeling af data
I internetforskning, eksperter studerer uregelmæssigheder i webtrafik, der kan indikere, for eksempel, cybertrusler. For at gøre det, det hjælper med først at forstå, hvordan normal trafik ser ud. Men at fange det har været udfordrende. Traditionelle "trafikanalysemodeller" kan kun analysere små prøver af datapakker, der udveksles mellem kilder og destinationer begrænset af placering. Det reducerer modellens nøjagtighed.
Forskerne søgte ikke specifikt at tackle dette trafikanalyseproblem. Men de havde udviklet nye teknikker, der kunne bruges på MIT SuperCloud til at behandle massive netværksmatricer. Internettrafik var den perfekte testcase.
Netværk studeres normalt i form af grafer, med aktører repræsenteret af noder, og links, der repræsenterer forbindelser mellem noderne. Med internettrafik, knudepunkterne varierer i størrelser og placering. Store supernoder er populære knudepunkter, såsom Google eller Facebook. Bladknude spreder sig fra denne supernode og har flere forbindelser til hinanden og supernoden. Beliggende uden for den "kerne" af supernoder og bladknuder er isolerede knuder og links, som kun sjældent forbinder hinanden.
Det er umuligt at fange det fulde omfang af disse grafer for traditionelle modeller. "Du kan ikke røre ved disse data uden adgang til en supercomputer, " siger Kepner.
I partnerskab med det bredt integrerede distribuerede miljø (WIDE) -projekt, grundlagt af flere japanske universiteter, og Center for Applied Internet Data Analysis (CAIDA), i Californien, MIT-forskerne indsamlede verdens største pakkeopsamlingsdatasæt til internettrafik. Det anonymiserede datasæt indeholder næsten 50 milliarder unikke kilde- og destinationsdatapunkter mellem forbrugere og forskellige apps og tjenester på tilfældige dage på tværs af forskellige steder over Japan og USA, går tilbage til 2015.
Inden de kunne træne nogen model på disse data, de havde brug for en omfattende forbehandling. For at gøre det, de brugte software, de tidligere havde oprettet, kaldet Dynamic Distributed Dimensional Data Mode (D4M), som bruger nogle gennemsnitsteknikker til effektivt at beregne og sortere "hypersparse data", der indeholder langt mere tomt rum end datapunkter. Forskerne brød dataene op i enheder på omkring 100, 000 pakker på tværs af 10, 000 MIT SuperCloud-processorer. Dette genererede mere kompakte matricer på milliarder af rækker og kolonner med interaktioner mellem kilder og destinationer.
Optagelse af ekstremiteter
Men langt de fleste celler i dette hyperspare datasæt var stadig tomme. For at behandle matricerne, holdet kørte et neuralt netværk på samme 10, 000 kerner. Bag scenen, en prøve-og-fejl-teknik begyndte at tilpasse modeller til hele data, skabe en sandsynlighedsfordeling af potentielt nøjagtige modeller.
Derefter, den brugte en modificeret fejlkorrektionsteknik til yderligere at forfine parametrene for hver model for at fange så mange data som muligt. Traditionelt set fejlkorrigerende teknikker i maskinlæring vil forsøge at reducere betydningen af eventuelle eksterne data for at få modellen til at passe til en normal sandsynlighedsfordeling, hvilket gør det mere præcist generelt. Men forskerne brugte nogle matematiske tricks for at sikre, at modellen stadig så alle afsidesliggende data - såsom isolerede links - som væsentlige for de overordnede målinger.
Til sidst, det neurale netværk genererer i det væsentlige en simpel model, med kun to parametre, der beskriver internettrafikdatasættet, "fra virkelig populære noder til isolerede noder, og hele spektret af alt derimellem, " siger Kepner.
Forskerne når nu ud til det videnskabelige samfund for at finde deres næste ansøgning om modellen. Eksperter, for eksempel, kunne undersøge betydningen af de isolerede links, forskerne fandt i deres eksperimenter, som er sjældne, men som ser ud til at påvirke webtrafikken i kerneknuderne.
Ud over internettet, den neurale netværkspipeline kan bruges til at analysere ethvert hypersparse netværk, såsom biologiske og sociale netværk. "Vi har nu givet det videnskabelige samfund et fantastisk værktøj til folk, der ønsker at bygge mere robuste netværk eller opdage anomalier i netværk, "Kepner siger." Disse anomalier kan bare være normal adfærd for, hvad brugerne gør, eller det kan være folk, der gør ting, du ikke ønsker."
Denne historie er genudgivet med tilladelse fra MIT News (web.mit.edu/newsoffice/), et populært websted, der dækker nyheder om MIT-forskning, innovation og undervisning.
 Varme artikler
Varme artikler
-
 Overførsel i neural stil rekonstruerer uset Picasso -maleriParc del laberint d’horta; en tabt Rusiñol, rekonstrueret ved hjælp af neurale stiloverførsler. Kredit:arXiv:1909.05677 [cs.CV] Rekonstruktion af tabt kunstværk blev bare meget mere interessant nu
Overførsel i neural stil rekonstruerer uset Picasso -maleriParc del laberint d’horta; en tabt Rusiñol, rekonstrueret ved hjælp af neurale stiloverførsler. Kredit:arXiv:1909.05677 [cs.CV] Rekonstruktion af tabt kunstværk blev bare meget mere interessant nu -
 Motorola vender efter sin futuristiske foldbare telefonDette udaterede produktbillede leveret af Motorola af Motorolas nye Razr -telefon. Motorola forbereder sig på fremtiden ved at vende tilbage til fortiden, da den vedtager et historisk flip-telefon-des
Motorola vender efter sin futuristiske foldbare telefonDette udaterede produktbillede leveret af Motorola af Motorolas nye Razr -telefon. Motorola forbereder sig på fremtiden ved at vende tilbage til fortiden, da den vedtager et historisk flip-telefon-des -
 Forskeren studerer strømforbrug i skyinfrastrukturerKredit:Victorgrigas/ Wikideia/ CC BY-SA 3.0 I sin doktorafhandling ved Umeå Universitet, Jakub Krzywda har udviklet modeller og algoritmer til at kontrollere afvejninger mellem strømforbruget i cl
Forskeren studerer strømforbrug i skyinfrastrukturerKredit:Victorgrigas/ Wikideia/ CC BY-SA 3.0 I sin doktorafhandling ved Umeå Universitet, Jakub Krzywda har udviklet modeller og algoritmer til at kontrollere afvejninger mellem strømforbruget i cl -
 Partikelfysikere designer forenklet ventilator til COVID-19-patienterEt internationalt team af partikelfysikere under ledelse af Princetons Cristian Galbiati stoppede deres søgen efter mørkt stof for at fokusere på den stigende efterspørgsel efter ventilatorer, nødvend
Partikelfysikere designer forenklet ventilator til COVID-19-patienterEt internationalt team af partikelfysikere under ledelse af Princetons Cristian Galbiati stoppede deres søgen efter mørkt stof for at fokusere på den stigende efterspørgsel efter ventilatorer, nødvend
- Kvanteberegning gør det muligt for simuleringer at optrevle mysterier af magnetiske materialer
- Hvordan statistikker gælder for March Madness
- Singapores lov om falske nyheder træder i kraft, når kritikere slår alarm
- Forudsig monsunregn måneder i forvejen med satellitter og simuleringer
- Brand hærger Esrange Space Center i det nordlige Sverige
- Fox investerer 100 millioner dollars i online spilleplatformen Koffein