


En metode til selvovervåget robotlæring, der indebærer at sætte sig gennemførlige mål

Robotten indsamler tilfældige interaktionsdata, der skal bruges til at træne en repræsentation og som off-policy data for RL. Kredit:Nair et al.
Reinforcement learning (RL) har indtil videre vist sig at være en effektiv teknik til at træne kunstige midler på individuelle opgaver. Imidlertid, når det kommer til træning af multifunktionelle robotter, som skal kunne udføre en række opgaver, der kræver forskellige færdigheder, de fleste eksisterende RL-tilgange er langt fra ideelle.
Med det i tankerne, et team af forskere ved UC Berkeley har for nylig udviklet en ny RL-tilgang, der kunne bruges til at lære robotter at tilpasse deres adfærd baseret på den opgave, de præsenteres for. Denne tilgang, skitseret i et papir, der er forududgivet på arXiv og præsenteret på dette års konference om robotlæring, giver robotter mulighed for automatisk at komme med adfærd og øve dem over tid, lære, hvilke der kan udføres i et givet miljø. Robotterne kan derefter genbruge den viden, de har erhvervet, og anvende den til nye opgaver, som menneskelige brugere beder dem om at udføre.
"Vi er overbeviste om, at data er nøglen til robotmanipulation og for at få nok data til at løse manipulation på en generel måde, robotter skal selv indsamle data, "Ashvin Nair, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "Dette er, hvad vi kalder selvovervåget robotlæring:En robot, der aktivt kan indsamle sammenhængende udforskningsdata og på egen hånd forstå, om den har haft succes eller fejlet med opgaver for at lære nye færdigheder."
Den nye tilgang udviklet af Nair og hans kolleger er baseret på en målbetinget RL-ramme, der blev præsenteret i deres tidligere arbejde. I denne tidligere undersøgelse, forskerne introducerede målsætning i et latent rum som en teknik til at træne robotter i færdigheder som at skubbe objekter eller åbne døre direkte fra pixels, uden behov for en ekstern belønningsfunktion eller statsestimat.
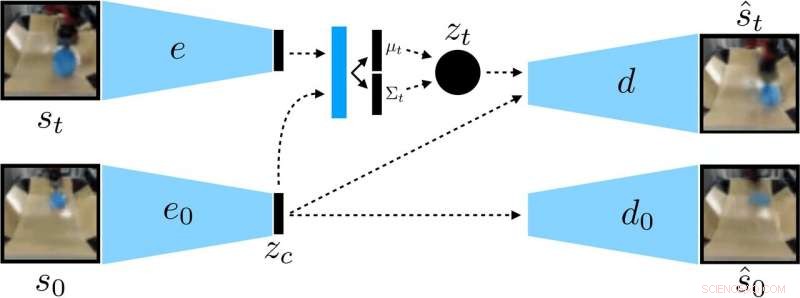
Forskerne trænede en kontekstbetinget VAE på dataene, som adskiller kontekst, der forbliver konstant under en udrulning. Kredit:Nair et al.
"I vores nye arbejde, vi fokuserer på generalisering:Hvordan kan vi lave selvovervåget læring for ikke kun at lære en enkelt færdighed, men også være i stand til at generalisere til visuel mangfoldighed, mens han udfører den færdighed?" Nair sagde. "Vi tror, at evnen til at generalisere til nye situationer vil være nøglen til bedre robotmanipulation."
I stedet for at træne en robot på mange færdigheder individuelt, den betingede målsætningsmodel foreslået af Nair og hans kolleger er designet til at sætte specifikke mål, der er gennemførlige for robotten og er tilpasset dens nuværende tilstand. I det væsentlige, den algoritme, de udviklede, lærer en bestemt type repræsentation, der adskiller ting, som robotten kan kontrollere, fra de ting, den ikke kan kontrollere.
Når de bruger deres selvovervågede læringsmetode, robotten indsamler oprindeligt data (dvs. et sæt billeder og handlinger) ved tilfældigt at interagere med dets omgivende miljø. Efterfølgende det træner en komprimeret repræsentation af disse data, der konverterer billeder til lavdimensionelle vektorer, der implicit indeholder information såsom objekters position. I stedet for at blive eksplicit fortalt, hvad de skal lære, denne repræsentation forstår automatisk begreber via dens komprimeringsmål.
"Ved at bruge den lærte repræsentation, robotten øver sig i at nå forskellige mål og træner en politik ved hjælp af forstærkende læring, " Forklarede Nair. "Den komprimerede repræsentation er nøglen til denne praksisfase:den bruges til at måle, hvor tæt to billeder er, så robotten ved, hvornår det er lykkedes eller fejlet, og det bruges til at prøve mål, som robotten kan øve sig på. På prøvetidspunktet, det kan derefter matche et målbillede specificeret af et menneske ved at udføre dets lærte politik."
Forskerne evaluerede effektiviteten af deres tilgang i en række eksperimenter, hvor et kunstigt middel manipulerede tidligere usete objekter i et miljø skabt ved hjælp af MuJuCo-simuleringsplatformen. Interessant nok, deres træningsmetode tillod robotagenten at tilegne sig færdigheder automatisk, som den derefter kunne anvende i nye situationer. Mere specifikt, robotten var i stand til at manipulere en række genstande, generaliserende manipulationsstrategier, den tidligere har tilegnet sig, til nye objekter, som den ikke havde mødt under træning.
"Vi er mest spændte på to resultater fra dette arbejde, " sagde Nair. "Først, vi fandt ud af, at vi kan træne en politik til at skubbe objekter i den virkelige verden på omkring 20 objekter, men den lærte politik kan faktisk også skubbe andre objekter. Denne type generalisering er hovedløftet for dyb læringsmetoder, og vi håber, at dette er starten på meget mere imponerende former for generalisering, der kommer."
Bemærkelsesværdigt, i deres eksperimenter, Nair og hans kolleger var i stand til at træne en politik fra et fast datasæt af interaktioner uden at skulle indsamle en stor mængde data online. Dette er en vigtig præstation, da dataindsamling til robotforskning generelt er meget dyr, og at kunne lære færdigheder fra faste datasæt gør deres tilgang langt mere praktisk.
I fremtiden, den model for selvovervåget læring, som forskerne har udviklet, kunne hjælpe med udviklingen af robotter, der kan tackle en bredere vifte af opgaver uden at træne et stort sæt færdigheder individuelt. I mellemtiden, Nair og hans kolleger planlægger at fortsætte med at teste deres tilgang i simulerede miljøer, samtidig med at man undersøger måder, hvorpå det kan forbedres yderligere.
"Vi forfølger nu et par forskellige forskningslinjer, herunder løsning af opgaver med en meget større mængde visuel diversitet, samt at løse et stort sæt opgaver samtidigt og se, om vi er i stand til at bruge løsningen på én opgave for at fremskynde løsningen af den næste opgave, " sagde Nair.
© 2019 Science X Network
Sidste artikelHvordan hackere kunne bruge Wi-Fi til at spore dig inde i dit hjem
Næste artikelUAW-medlemmer ratificerer Fords arbejdsaftale
 Varme artikler
Varme artikler
-
 Inkblot test med AI:OMG, gadestikkeri? Ingen, blomst og fløjteKredit:MIT At lære, hvad folk ser på deres Rorschach-test (den psykologiske test, hvor din opfattelse af en blækklat analyseres for at undersøge personlighed og følelsesmæssig funktion) er interes
Inkblot test med AI:OMG, gadestikkeri? Ingen, blomst og fløjteKredit:MIT At lære, hvad folk ser på deres Rorschach-test (den psykologiske test, hvor din opfattelse af en blækklat analyseres for at undersøge personlighed og følelsesmæssig funktion) er interes -
 Ubehageligt skrånende toilet designet til at skylle udsatte medarbejdere udKredit:CC0 Public Domain Det er en måde at få styr på medarbejderne, der udsætter sig på badeværelset. Et opstartsfirma i Det Forenede Kongerige blev i denne uge styrtet i strid for at have udtæn
Ubehageligt skrånende toilet designet til at skylle udsatte medarbejdere udKredit:CC0 Public Domain Det er en måde at få styr på medarbejderne, der udsætter sig på badeværelset. Et opstartsfirma i Det Forenede Kongerige blev i denne uge styrtet i strid for at have udtæn -
 Ny AI-chipdesignplatform, der giver halvlederindustrien et løft i produktivitet og kvalitetKredit:CC0 Public Domain A*STAR-forskere har udviklet en AI-chipdesignplatform, der har potentiale til at transformere designindustrien med mange milliarder dollar globalt integreret kredsløb (IC)
Ny AI-chipdesignplatform, der giver halvlederindustrien et løft i produktivitet og kvalitetKredit:CC0 Public Domain A*STAR-forskere har udviklet en AI-chipdesignplatform, der har potentiale til at transformere designindustrien med mange milliarder dollar globalt integreret kredsløb (IC) -
 Qatar Airways udvider trods stort tab:chefEn A350 af Qatar Airways er afbilledet den 19. oktober, 2017, efter start fra Toulouse-Blagnac lufthavn, i nærheden af Toulouse Qatar Airways vil fortsætte med at ekspandere, selvom det forbered
Qatar Airways udvider trods stort tab:chefEn A350 af Qatar Airways er afbilledet den 19. oktober, 2017, efter start fra Toulouse-Blagnac lufthavn, i nærheden af Toulouse Qatar Airways vil fortsætte med at ekspandere, selvom det forbered
- Det første eksperimentelle bevis på udbredelsen af plasmaturbulens
- Hvad er det ultimative slutresultat af glycolyse?
- Hvor kommer vandet i en brønd fra?
- Ny teknik kortlægger hurtigt unge isaflejringer og formationer på Mars
- Kæmpe sorte hul par fotobomber Andromeda galaksen
- Et katalytisk system af uædle metaller til højeffektiv hydrogenering af nitroarener