


Træning af robotter til at identificere objektplaceringer ved at hallucinere scener

Oier Mees demonstrerer, hvordan den nye tilgang fungerer. Kredit:Mees et al.
Med flere robotter nu på vej ind i en række indstillinger, forskere forsøger at gøre deres interaktioner med mennesker så glat og naturlig som muligt. Træning af robotter til at reagere øjeblikkeligt på talte instruktioner, såsom "saml glasset op, flyt den til højre, " etc., ville være ideel i mange situationer, da det i sidste ende ville muliggøre mere direkte og intuitive menneske-robot-interaktioner. Imidlertid, det er ikke altid nemt, da det kræver, at robotten forstår en brugers instruktioner, men også at vide, hvordan man flytter objekter i overensstemmelse med specifikke rumlige relationer.
Forskere ved universitetet i Freiburg i Tyskland har for nylig udtænkt en ny tilgang til at lære robotter, hvordan man flytter objekter rundt som instrueret af menneskelige brugere, som virker ved at klassificere "hallucinerede" scenerepræsentationer. Deres papir, forudgivet på arXiv, vil blive præsenteret på IEEE International Conference on Robotics and Automation (ICRA) i Paris, denne juni.
"I vores arbejde vi koncentrerer os om instruktioner til placering af relationelle objekter, såsom 'placer kruset til højre for æsken' eller 'sæt det gule legetøj oven på æsken, "Oier Mees, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "For at gøre det, robotten skal ræsonnere om, hvor kruset skal placeres i forhold til æsken eller ethvert andet referenceobjekt for at gengive den rumlige relation, som er beskrevet af en bruger."
Det kan være meget svært at træne robotter til at forstå rumlige relationer og flytte objekter i overensstemmelse hermed. da en brugers instruktioner typisk ikke afgrænser et specifikt sted inden for en større scene observeret af robotten. Med andre ord, hvis en menneskelig bruger siger "placer kruset til venstre på uret, " hvor langt tilbage fra uret skal robotten placere kruset, og hvor er den nøjagtige grænse mellem forskellige retninger (f.eks. ret, venstre, foran, bag, etc.)?
"På grund af denne iboende tvetydighed, der er heller ingen grundsandhed eller 'korrekte' data, der kan bruges til at lære at modellere rumlige relationer, " sagde Mees. "Vi adresserer problemet med utilgængeligheden af jord-sandhed pixelvise annoteringer af rumlige relationer fra perspektivet af hjælpelæring."
Hovedtanken bag den tilgang, som Mees og hans kolleger har udtænkt, er, at når de gives to objekter og et billede, der repræsenterer den kontekst, hvori de findes, det er lettere at bestemme det rumlige forhold mellem dem. Dette gør det muligt for robotterne at registrere, om det ene objekt er til venstre for det andet, Oven på det, foran det, etc.
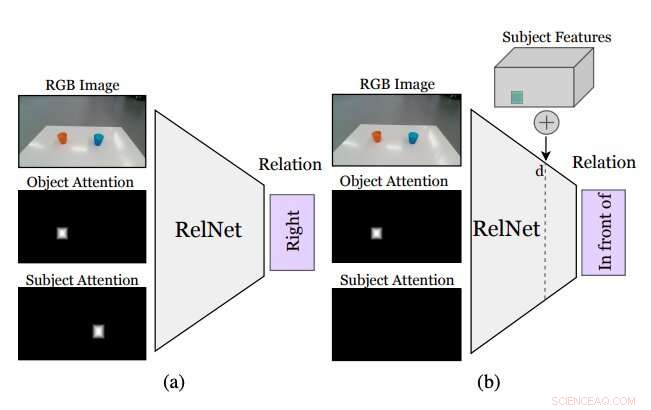
Figur, der opsummerer, hvordan den tilgang, som forskerne har udtænkt, fungerer. En hjælpe-CNN, kaldet RelNet, er trænet til at forudsige rumlige relationer givet inputbilledet og to opmærksomhedsmasker, der refererer til to objekter, der danner en relation. (a) efter træning, netværket kan 'narres' til at klassificere hallucinerede scener ved (b) at implementere elementer på højt niveau på forskellige rumlige steder. Kredit:Mees et al.
Mens identifikation af et rumligt forhold mellem to objekter ikke specificerer, hvor objekterne skal placeres for at reproducere denne relation, indsættelse af andre objekter i scenen kunne give robotten mulighed for at udlede en fordeling over flere rumlige relationer. Tilføjelse af disse ikke-eksisterende (dvs. hallucinerede) objekter til det, robotten ser, skulle give den mulighed for at evaluere, hvordan scenen ville se ud, hvis den udførte en given handling (dvs. placere en af genstandene et bestemt sted på bordet eller overfladen foran det).
"Mest almindeligt, At 'indsætte' objekter realistisk i et billede kræver enten adgang til 3-D-modeller og silhuetter eller omhyggeligt design af optimeringsproceduren for generative adversarial networks (GAN'er), " sagde Mees. "Desuden, at naivt "indsætte" objektmasker i billeder skaber subtile pixelartefakter, der fører til mærkbart forskellige funktioner og til, at træningen fejlagtigt fokuserer på disse uoverensstemmelser. Vi tager en anden tilgang og implanterer objekter på højt niveau i feature maps af scenen genereret af et foldet neuralt netværk for at hallucinere scenerepræsentationer, som så klassificeres som en hjælpeopgave for at få læringssignalet."
Før du træner et konvolutionelt neuralt netværk (CNN) til at lære rumlige relationer baseret på hallucinerede objekter, forskerne skulle sikre sig, at den var i stand til at klassificere relationer mellem individuelle par objekter baseret på et enkelt billede. Efterfølgende de "lurede" deres netværk, døbt RelNet, til at klassificere "hallucinerede" scener ved at implantere elementer på højt niveau på forskellige rumlige steder.
"Vores tilgang tillader en robot at følge instrukser om naturligt sprogplacering givet af menneskelige brugere med minimal dataindsamling eller heuristik, " sagde Mees. "Alle vil gerne have en servicerobot derhjemme, som kan udføre opgaver ved at forstå instruktioner på det naturlige sprog. Dette er et første skridt til at sætte en robot i stand til bedre at forstå betydningen af almindeligt anvendte rumlige præpositioner."
De fleste eksisterende metoder til træning af robotter til at flytte objekter rundt bruger information relateret til objekterne" 3-D-former til at modellere parvise rumlige forhold. En vigtig begrænsning ved disse teknikker er, at de ofte kræver yderligere teknologiske komponenter, såsom sporingssystemer, der kan spore forskellige objekters bevægelser. Metoden foreslået af Mees og hans kolleger, på den anden side, kræver ikke yderligere værktøjer, da det ikke er baseret på 3-D synsteknikker.
Forskerne evaluerede deres metode i en række eksperimenter, der involverede rigtige menneskelige brugere og robotter. Resultaterne af disse test var meget lovende, da deres metode tillod robotter effektivt at identificere de bedste strategier til at placere objekter på et bord i overensstemmelse med de rumlige relationer skitseret af en menneskelig brugers talte instruktioner.
"Vores nye tilgang til hallucinerende scenerepræsentationer kan også have flere anvendelser i robotteknologi og computersynssamfund, da robotter ofte skal være i stand til at vurdere, hvor god en fremtidig tilstand kan være for at ræsonnere over de handlinger, de skal tage, " sagde Mees. "Det kunne også bruges til at forbedre ydeevnen af mange neurale netværk, såsom objektdetekteringsnetværk, ved at bruge hallucinerede scenerepræsentationer som en form for dataforøgelse."
Mees og hans kolleger er vi i stand til at modellere et sæt af naturlige sproglige rumlige præpositioner (f.eks. højre, venstre, på toppen af, osv.) pålideligt og uden brug af 3-D vision-værktøjer. I fremtiden, den tilgang, der præsenteres i deres undersøgelse, kunne bruges til at forbedre eksisterende robotters kapacitet, giver dem mulighed for at udføre simple objektskifteopgaver mere effektivt, mens de følger en menneskelig brugers talte instruktioner.
I mellemtiden deres papir kunne informere udviklingen af lignende teknikker til at forbedre interaktioner mellem mennesker og robotter under andre objektmanipulationsopgaver. Hvis det kombineres med hjælpelæringsmetoder, tilgangen udviklet af Mees og hans kolleger kan også reducere omkostningerne og indsatsen i forbindelse med kompilering af datasæt til robotforskning, da det muliggør forudsigelse af pixelvise sandsynligheder uden at kræve store annoterede datasæt.
"Vi føler, at dette er et lovende første skridt mod at muliggøre en fælles forståelse mellem mennesker og robotter, " konkluderede Mees. "I fremtiden, vi ønsker at udvide vores tilgang til at inkorporere en forståelse af refererende udtryk, for at udvikle et pick-and-place system, der følger naturlige sproginstruktioner."
© 2020 Science X Network
 Varme artikler
Varme artikler
-
 Store luftfartsselskaber, statens AG'er vil arbejde for at bekæmpe robocallsI denne 11. august, 2019, fil foto, en mand bruger en mobiltelefon i New Orleans. Store telefonvirksomheder fortæller landets statsadvokater, at de vil gøre mere mod robocalls. Det er det sidste skrid
Store luftfartsselskaber, statens AG'er vil arbejde for at bekæmpe robocallsI denne 11. august, 2019, fil foto, en mand bruger en mobiltelefon i New Orleans. Store telefonvirksomheder fortæller landets statsadvokater, at de vil gøre mere mod robocalls. Det er det sidste skrid -
 Instadrugs:ny forskning afslører skjulte farer, når unge mennesker bruger apps til at købe ulovli…Hurtigt, nemt – og meget, meget risikabelt. Kredit:The Conversation UK. Markederne for ulovlige stoffer udvikler sig konstant for at øge profitten og reducere risici for leverandører som svar på r
Instadrugs:ny forskning afslører skjulte farer, når unge mennesker bruger apps til at købe ulovli…Hurtigt, nemt – og meget, meget risikabelt. Kredit:The Conversation UK. Markederne for ulovlige stoffer udvikler sig konstant for at øge profitten og reducere risici for leverandører som svar på r -
 Patenteret teknologi klæder placering på mobile enheder for at beskytte privatlivets fredYing Cai siger, at hans tilsløringsteknologi kan skjule din præcise placering, når du bruger apps på din mobiltelefon. Kredit:Dave Olson Vi accepterer at opgive en vis grad af fortrolighed, når vi
Patenteret teknologi klæder placering på mobile enheder for at beskytte privatlivets fredYing Cai siger, at hans tilsløringsteknologi kan skjule din præcise placering, når du bruger apps på din mobiltelefon. Kredit:Dave Olson Vi accepterer at opgive en vis grad af fortrolighed, når vi -
 Forældre opfordres til at tænke sig om to gange om at købe Amazon Echo Dot til børnAlexa, vent lidt. Amazon Dot Echo Kids Edition startede levering i denne uge, men børns fortalere og andre beder forældre om at vente med at købe $79-versionen af virksomhedens markedsledende smart
Forældre opfordres til at tænke sig om to gange om at købe Amazon Echo Dot til børnAlexa, vent lidt. Amazon Dot Echo Kids Edition startede levering i denne uge, men børns fortalere og andre beder forældre om at vente med at købe $79-versionen af virksomhedens markedsledende smart
- Rapporten dokumenterer de kortsigtede virkninger af klimaændringer på investorer
- Udbredt database med molekylære fingeraftryk opgraderet
- Revisioner af drikkevandsstandarden strammer blyudvaskningsgodtgørelsen for VVS-produkter
- Hvorfor er kræftens tropik vigtig?
- Hvad er meningen med kinetisk energi?
- Asteroidefragmenter, der skal studeres ved hjælp af specialiserede røntgenteknikker